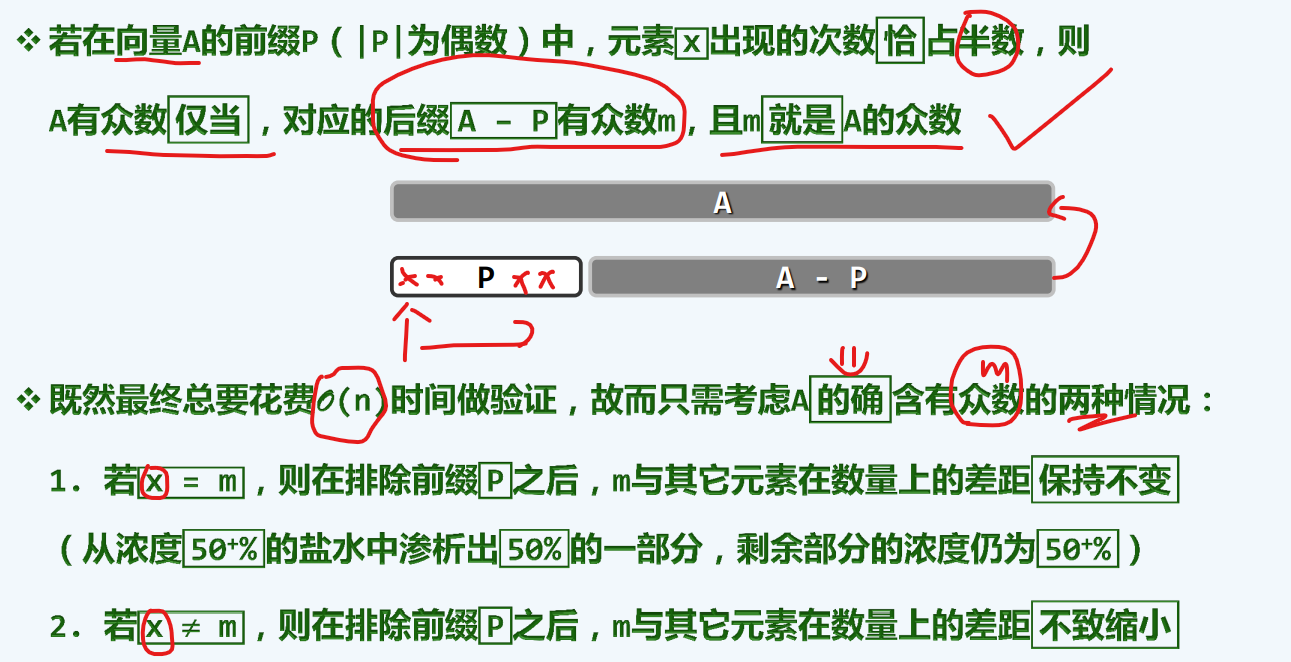
template <typename T> T majEleCandidate( Vector<T> A ){ //选出具备必要条件的众数候选者 0002 T maj; //众数候选者 0003// 线性扫描:借助计数器c,记录maj与其它元素的数量差额 0004for ( int c = 0, i = 0; i < A.size(); i++ ) 0005if ( 0 == c ) { //每当c归零,都意味着此时的前缀P可以剪除 0006 maj = A[i]; c = 1; //众数候选者改为新的当前元素 0007 } else//否则 0008 maj == A[i] ? c++ : c--; //相应地更新差额计数器 0009return maj; //至此,原向量的众数若存在,则只能是maj —— 尽管反之不然 0010 }
选取:通用算法
排序计算自身需要高复杂度,如果我们只需要选取众数(选出特定的数)
则可以舍弃排序的思路
尝试
蛮力
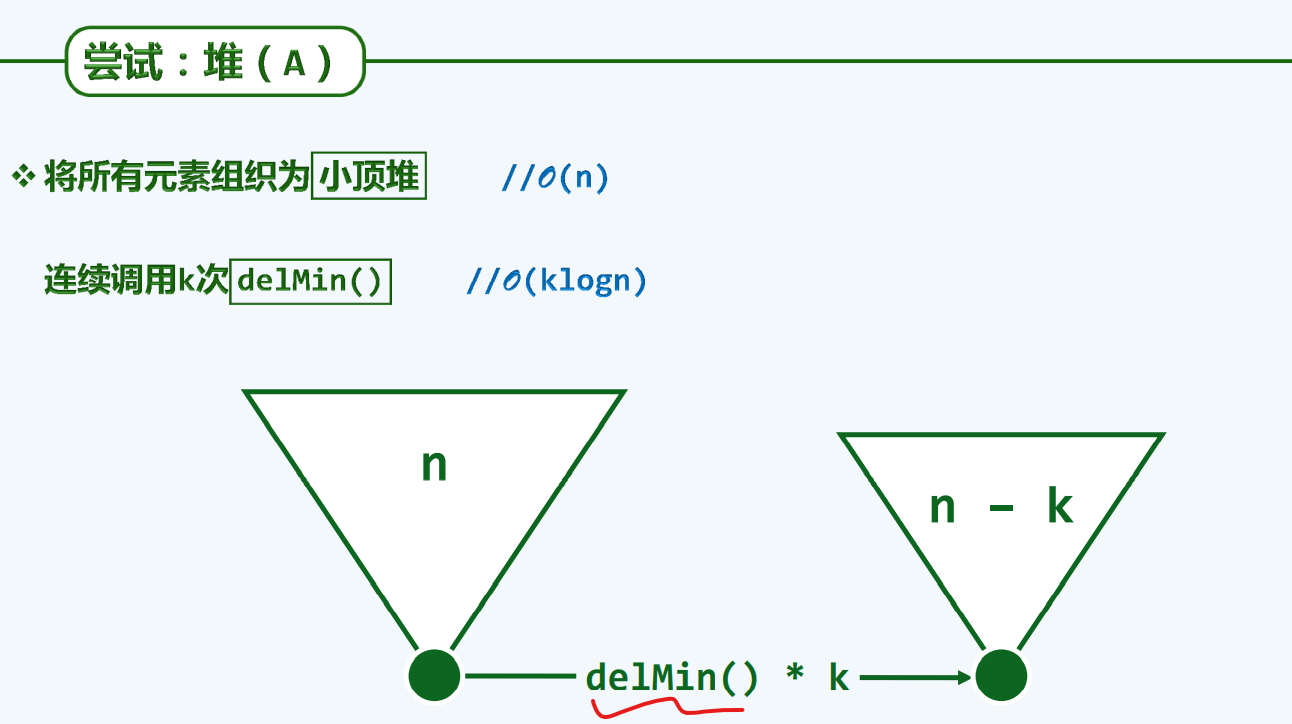
堆A
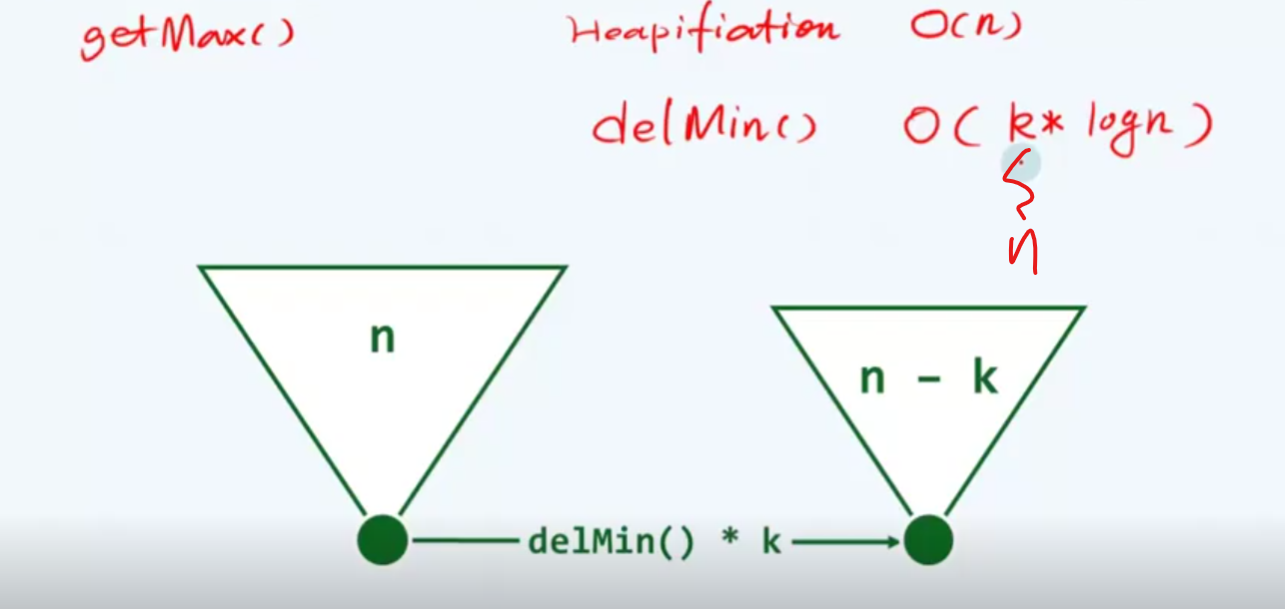
堆B
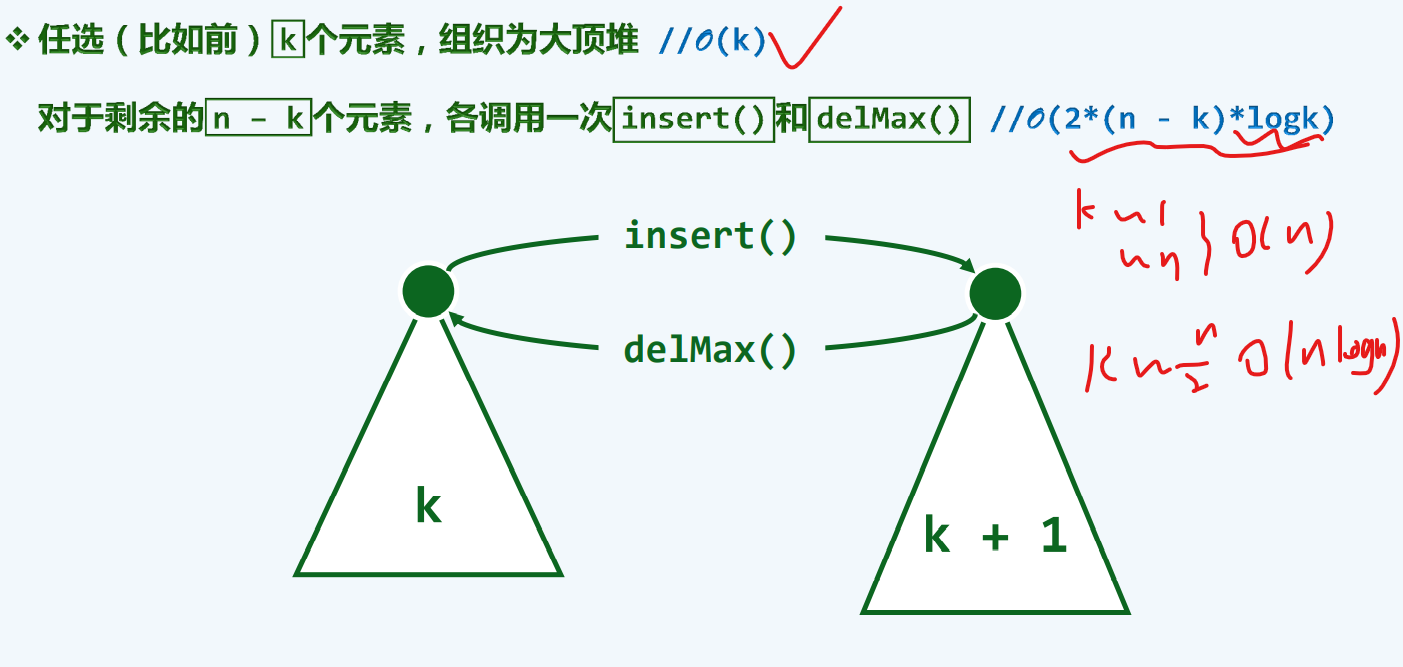
堆C
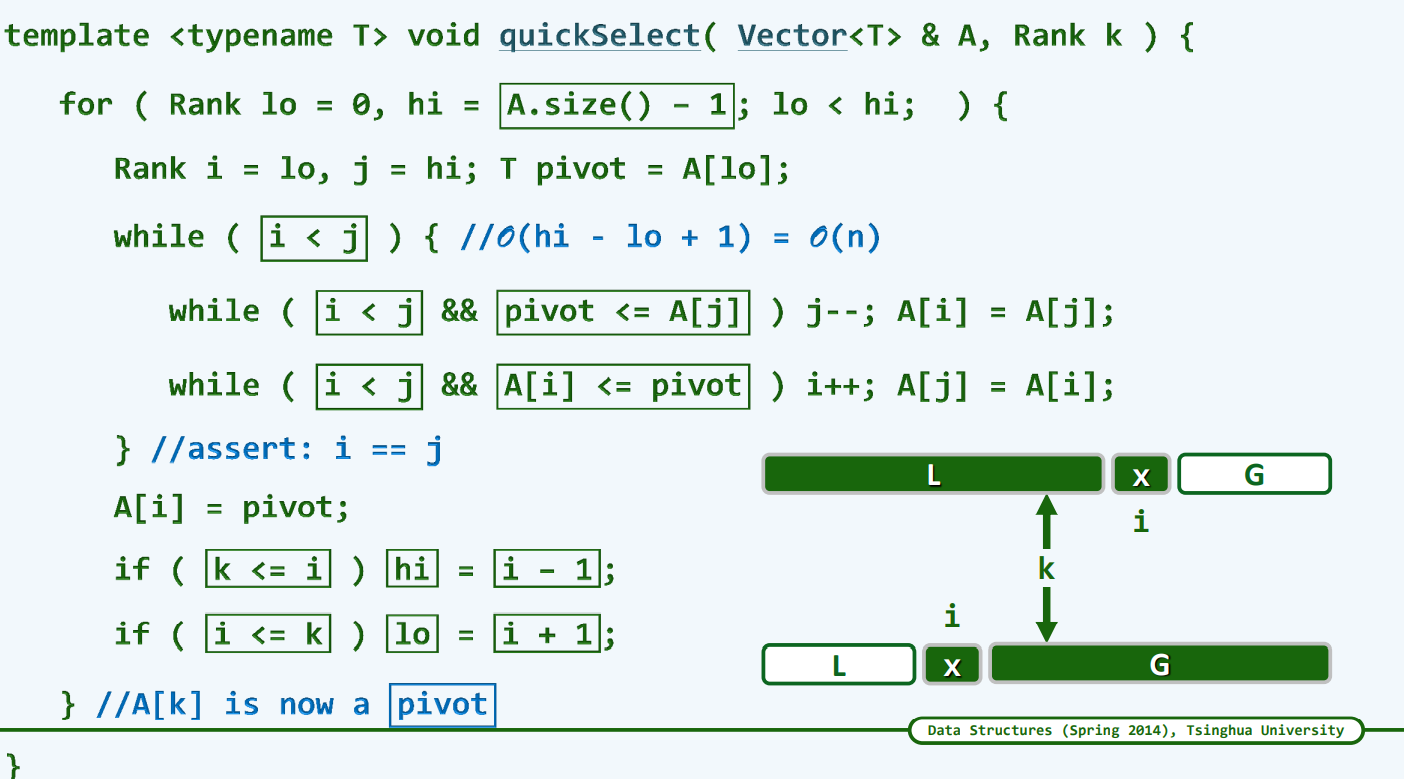
quickSelect
1 2 3 4 5 6 7 8 9 10 11 12
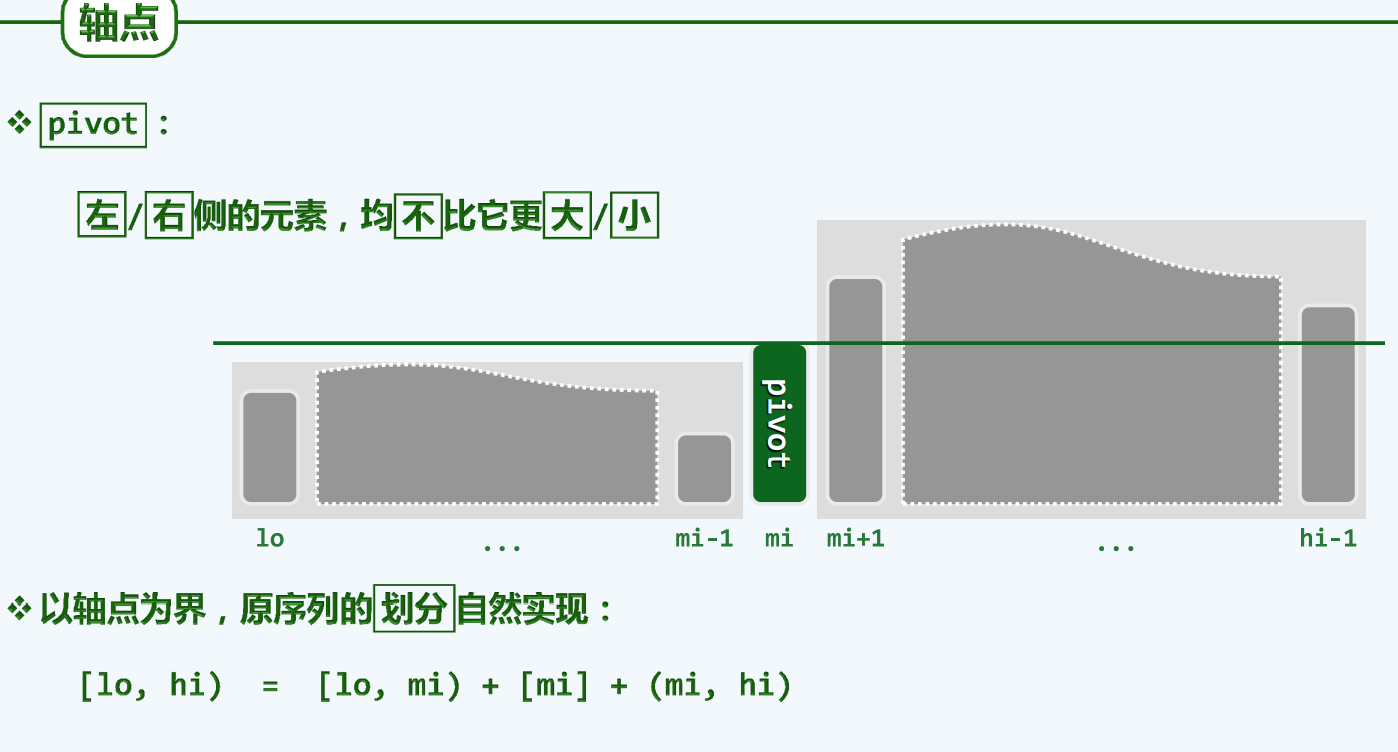
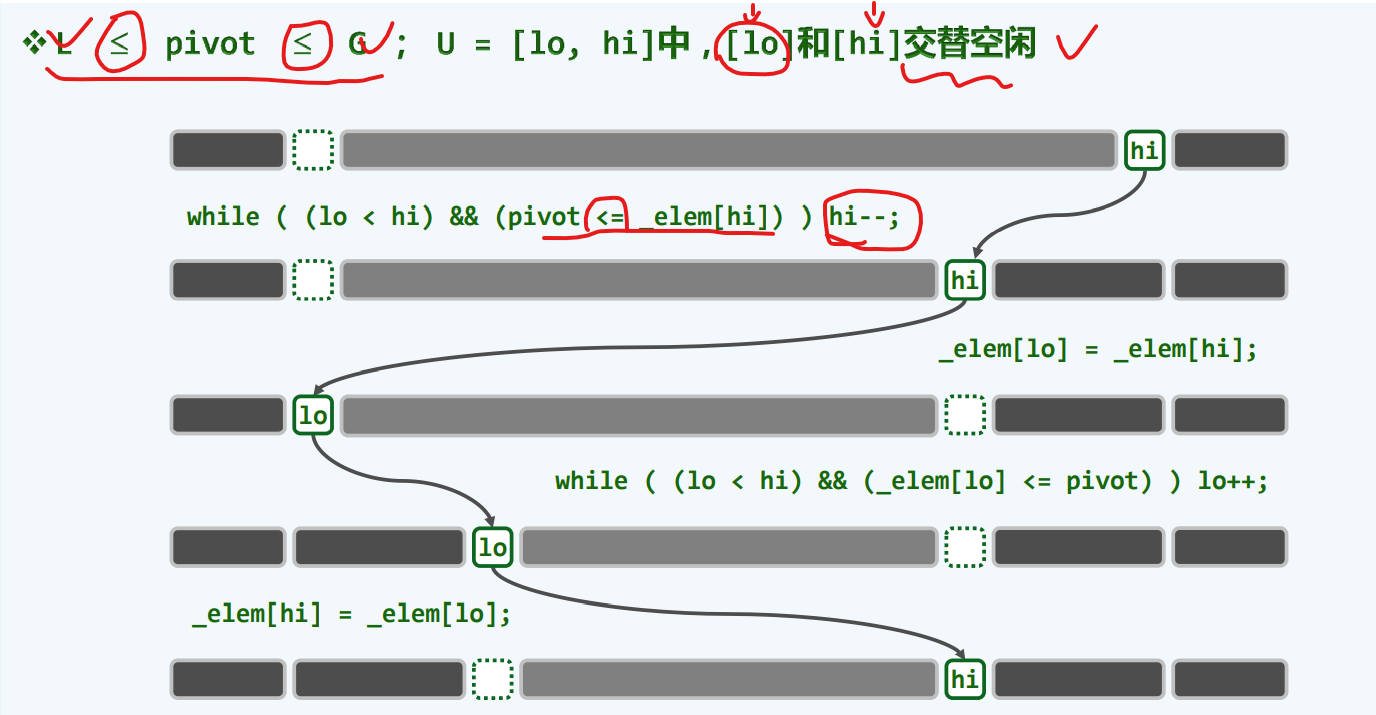
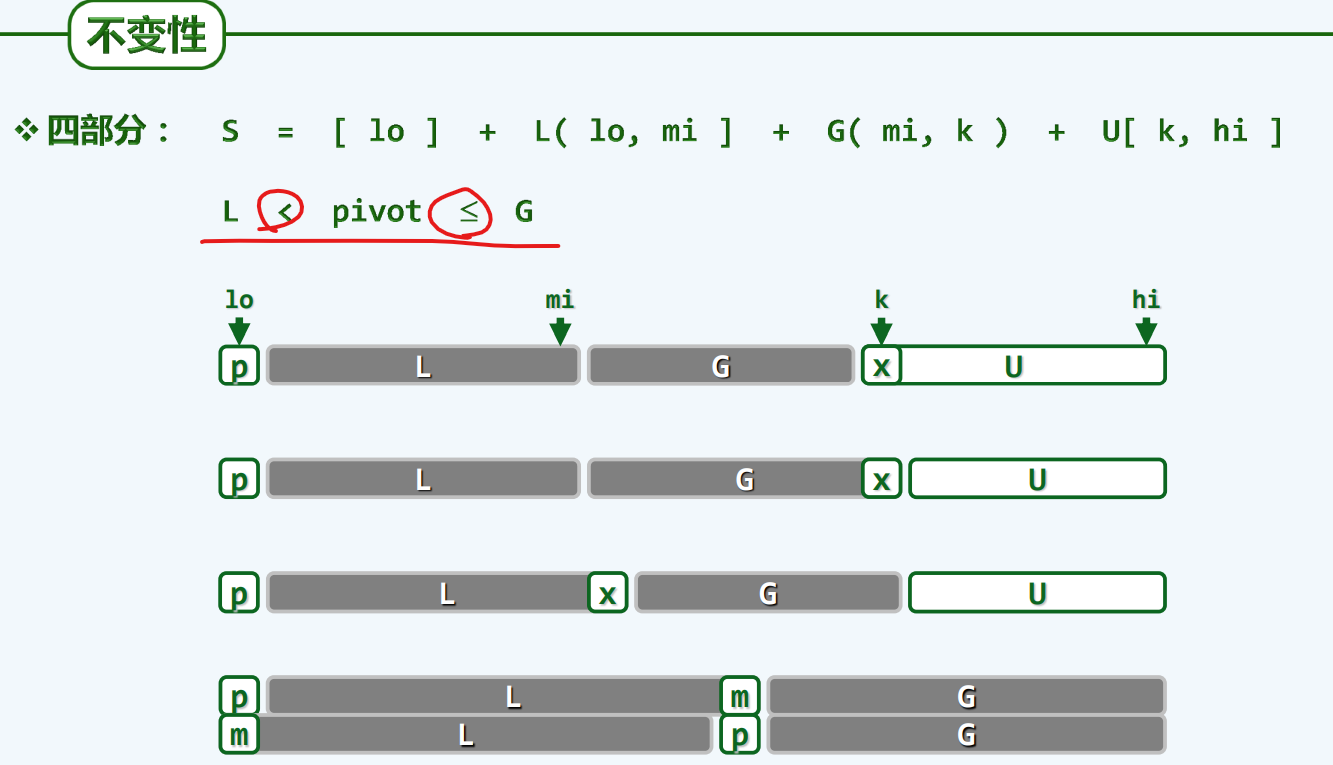
template <typename T> voidquickSelect( Vector<T> & A, Rank k ){ //基于快速划分的k选取算法 0002for ( Rank lo = 0, hi = A.size() - 1; lo < hi; ) { 0003 Rank i = lo, j = hi; T pivot = A[lo]; //大胆猜测 0004while ( i < j ) { //小心求证:O(hi - lo + 1) = O(n) 0005while ( ( i < j ) && ( pivot <= A[j] ) ) j--; A[i] = A[j]; 0006while ( ( i < j ) && ( A[i] <= pivot ) ) i++; A[j] = A[i]; 0007 } //assert: quit with i == j 0008 A[i] = pivot; // A[0,i) <= A[i] <= A(i, n) 0009if ( k <= i ) hi = i - 1; 0010if ( i <= k ) lo = i + 1; 0011 } //A[k] is now a pivot 0012 }
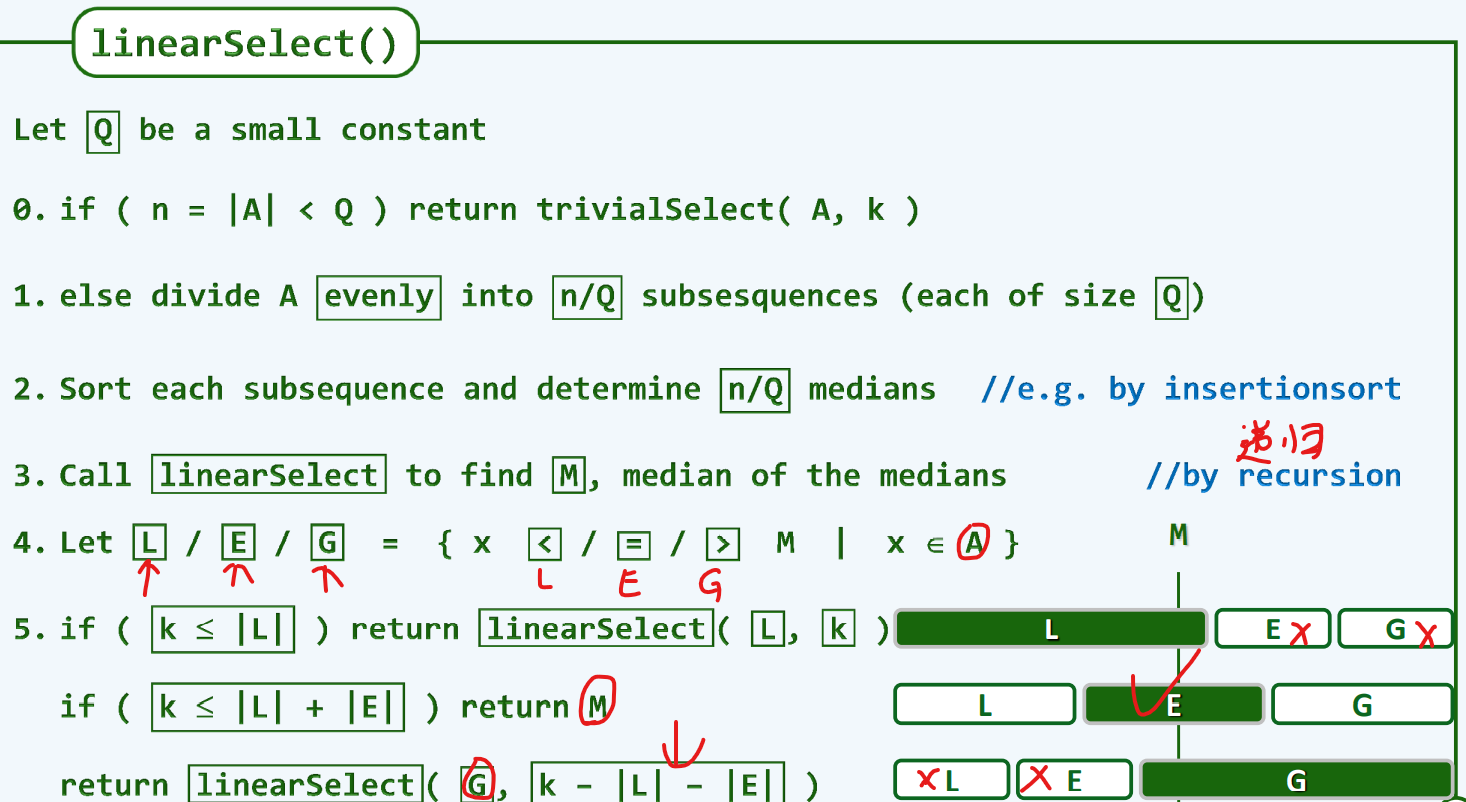
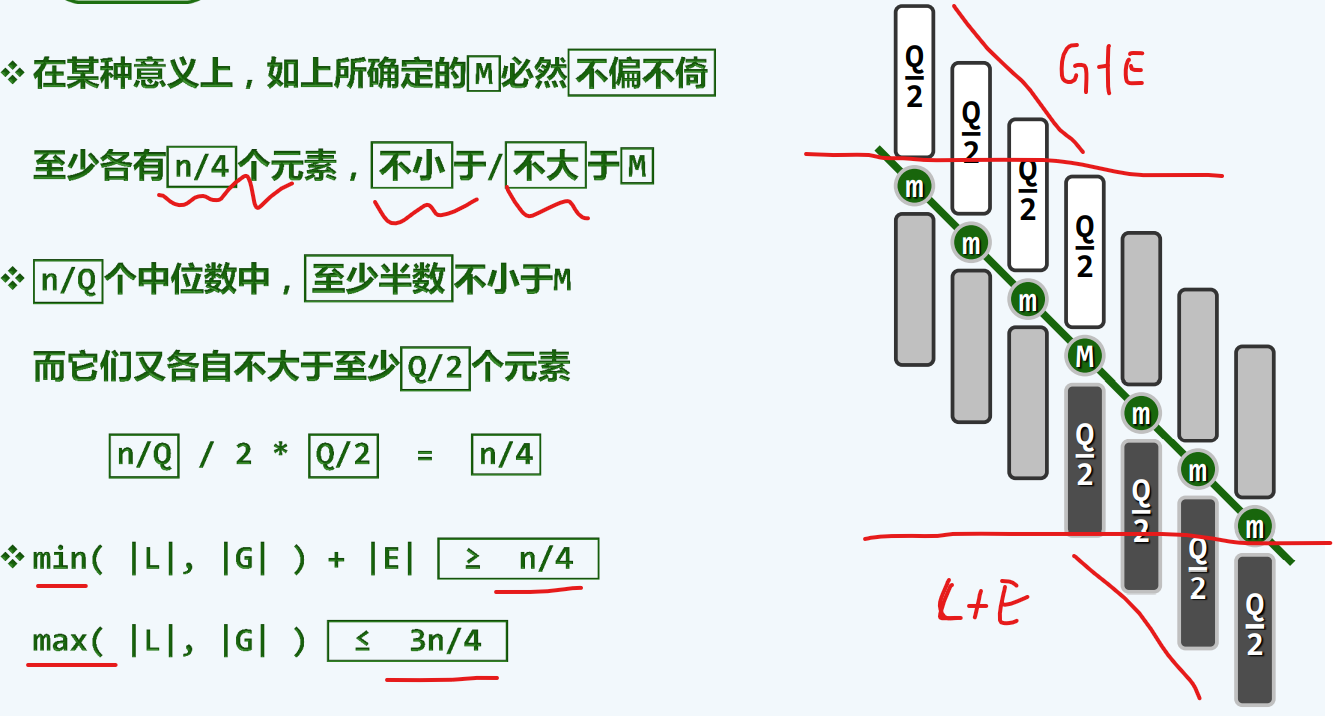
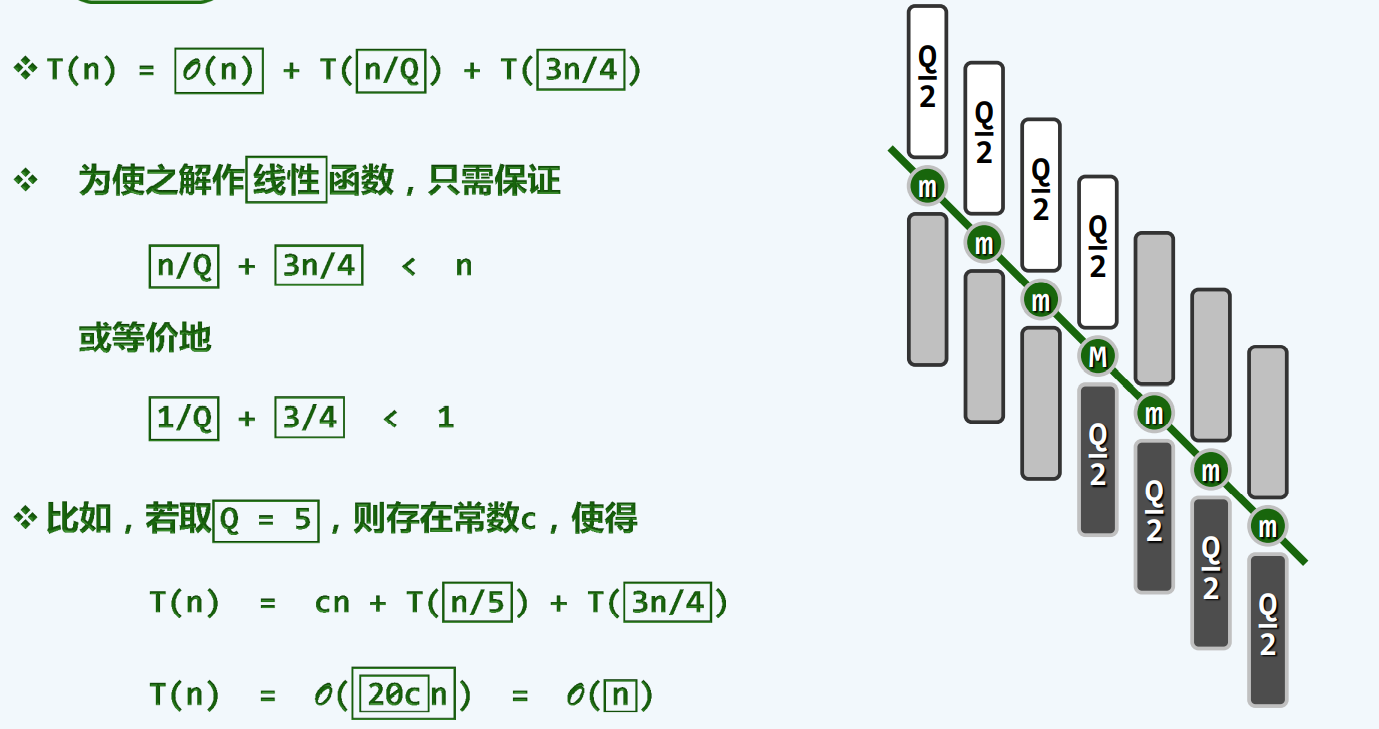
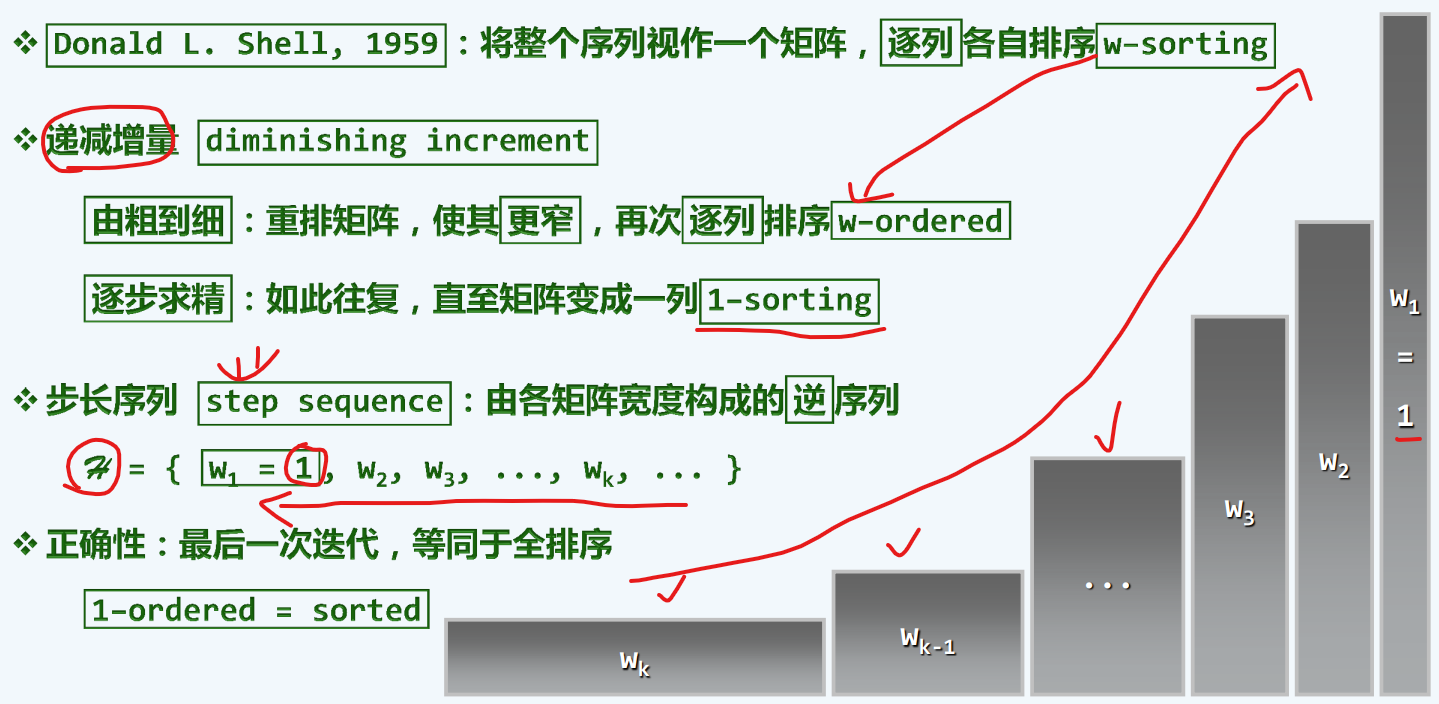
linearSelect
基本上没听了TAT这个
算法
性能分析
复杂度
我的实现
quickSort.h
1 2 3 4 5 6 7 8 9 10
#pragma once #include"partition.h" using Rank = int; template <typename T> voidquickSort(T* _elem, Rank lo, Rank hi){ if (hi - lo < 2) return; T mi = partition(_elem, lo, hi - 1); quickSort(_elem, lo, mi); quickSort(_elem, mi + 1, hi); }
partition.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#pragma once #include"quickSort.h" #include<iostream> using Rank = int; template <typename T>//partitionLRU版本,我的最爱 Rank partition(T* _elem, Rank lo, Rank hi){ std::swap(_elem[lo], _elem[lo + rand() % (hi - lo + 1)]); T pivot = _elem[lo]; int mi = lo;
for (int k = lo + 1; k <= hi; k++)//k <= hi 而不是k < hi,第一次写写错了 if (_elem[k] < pivot) //因为传进来的时候已经hi-1了 std::swap(_elem[k], _elem[++mi]); std::swap(_elem[lo], _elem[mi]); return mi; }
quickSelect.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
#pragma once using Rank = int; #include<iostream>; template <typename T> voidquickSelect(T* A,int capacity ,Rank k){ //std::cout << sizeof(A) / sizeof(A[0]) - 1 << std::endl; for (Rank lo = 0, hi = capacity-1 ; lo < hi;) { Rank i = lo, j = hi; T pivot = A[lo]; while (i < j) { while (i < j && pivot <= A[j]) j--; A[i] = A[j]; while (i < j && A[i] <= pivot) i++; A[j] = A[i]; }//assert i == j; 快排中partition的LUR版本 A[i] = pivot; if (k <= i)hi = i - 1; if (i <= k)lo = i + 1; }//A[k] is now a pivot }































 微信
微信 支付宝
支付宝




