
MySQL使用
MySQL 案例实战教程
案例1:MySQL的安装和基本使用
下载mariadb
Windows下安装见此贴
安装需要设置编码为 UTF-8 , 管理用户root,密码设置 root 或 123456
注意:MySQL在Windows不区分大小写,在Linux区分大小写
案例2:MySQL的数据类型
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
备注: char 和varchar 一定要指定长度,float 会自动提升为double,timestamp 是时间的混合类型,理论上可以存储 时间格式和时间戳。
| 类型 | 用途 |
|---|---|
| int | 整型,相当于java 的int |
| bigint | 整型,相当于java 的 long |
| float | 浮点型 |
| double | 浮点型 |
| datetime | 日期类型 |
| timestamp | 日期类型(可存储时间戳) |
| char | 定长字符 |
| varchar | 不定长字符 |
| text | 大文本,用于存储很长的字符内容(几万个字符) |
| blob | 字节数据类型,存储图片、音频等文件 |
案例3:建表操作
 语法
语法
1 | -- 删除表 PS: 两个横线一个空格代表单行注释符,多行就是/* 多行注释 */和c语言一样 |
在 SQL 中,我们有如下约束:
 NOT NULL - 指示某列不能存储 NULL 值。
NOT NULL - 指示某列不能存储 NULL 值。
 UNIQUE - 保证某列的每行必须有唯一的值。
UNIQUE - 保证某列的每行必须有唯一的值。
PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
 FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
 CHECK - 保证列中的值符合指定的条件。
CHECK - 保证列中的值符合指定的条件。
DEFAULT - 规定没有给列赋值时的默认值。
 实例
实例
1 |
|
案例4:插入、删除、更新
 插入语句
插入语句
1 | INSERT INTO websites(name,url,alexa,sal,country ) VALUES ('腾讯', 'https://www.qq.com', 18, 1000,'CN' ) ; |
 删除语句
删除语句
1 | delete from websites where id = 5; |
 更新语句
更新语句
1 | update websites set sal = null where id = 3 |
案例5:基本 select 查询语句
 初始化数据
初始化数据
1 | DROP TABLE IF EXISTS `websites`; CREATE TABLE `websites` ( |
查询语句
1 | -- 实际开发中尽量不要使用* 作为查询 |
我们选中右面的字段,进行鼠标左键拖动,可以一键将其拖入代码段中
案例6. 分页查询
mysql 的分页是最优雅
1 | select * from websites limit 2,3 ; --从第2条(下标从0开始)开始查,查3条数据 |
案例7. distinct 关键字
DISTINCT 关键词用于返回唯一的不同的值。
1 | select distinct country from websites |
案例8. where 语句
作为条件筛选, 运算符: > < >= <= <> != = (!= 和 <>意义相同)
is null is not null (因为在sql 语句中null 和任何东西比较都是假,包括它本身)
like in
1 | select * from websites where sal > 500 |
1 | UPDATE websites set sal = NULL WHERE id = 2; |

案例9. 逻辑条件: and 、or
1 | select * from websites where sal >= 0 and sal <= 2000; -- 收入在 0 到 2000之间 |
注意: null 的条件判断用 is null 或 is not null
案例10. order by
排序: 默认情况下是升序,asc 可以省略 。
1 | select * from websites order by sal asc,alexa desc ; |
案例11. like 和 通配符
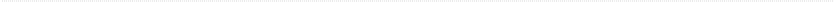
通配符是一种特殊语句,主要用来模糊查询。当不知道真正字符或者懒得输入完整名称时,可以使用通配符来代替一个或多个真正的字符。
like 模糊查询
通配符
%: 0个或多个字符“%” 是 MySQL 中最常用的通配符,它能代表任何长度的字符串,字符串的长度可以为 0。例如,a%b表示以字母 a 开头,以字母 b 结尾的任意长度的字符串。该字符串可以代表 ab、acb、accb、accrb 等字符串。
- 该实例代表,找到websites表中name项里有o的一项(前后项任意取都行,没有东西也行)

- 该实例代表,找到websites表中name项里有o的一项(前后项任意取都行,没有东西也行)
_: 1 个字符“_”只能代表单个字符,字符的长度不能为 0。例如,
a_b可以代表 acb、adb、aub 等字符串。如果 _o% 就代表了只有找到o前面只有一个字符的,才会返回- 这两张图就很好得反应出来了,_的绝对性


- 这两张图就很好得反应出来了,_的绝对性
案例12. in
匹配多个条件
1 | select * from websites where country in ('USA','鸟国','CN'); |
 等价于
等价于
1 | select * from websites where country = 'USA' or country = '鸟国' or country = 'CN' |

案例13. 别名
1 | select tt.name '网站名字' from websites tt -- 最好这样,比较直观 |


案例14. Group by 分组查询
注意:分组时候的筛选用 having
常见的几个组函数: max() min() avg() count() sum()
上面起别名已经使用了
1 | select avg(sal) aa from websites where sal is not null group by country having aa > 1200 |

案例15. 子查询?
把查询的结果当作一个表来使用
案例16. 连接查询 *
1 | select name,count,date from websites w , access_log a ; |
如图:
1 | select name,count,date from websites w , access_log a where w.id = a.site_id; |
效果展示
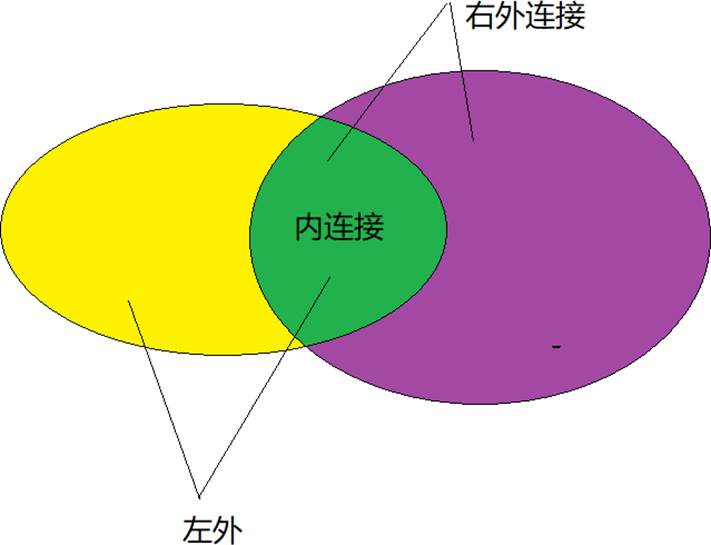
右外连接:
可以看到的是,右边是access_log,access里面有一个site_id为888,websites没有与他对应的ID,因此本着主要考虑右边,我们显示出888哪一行,并且左边的值全补null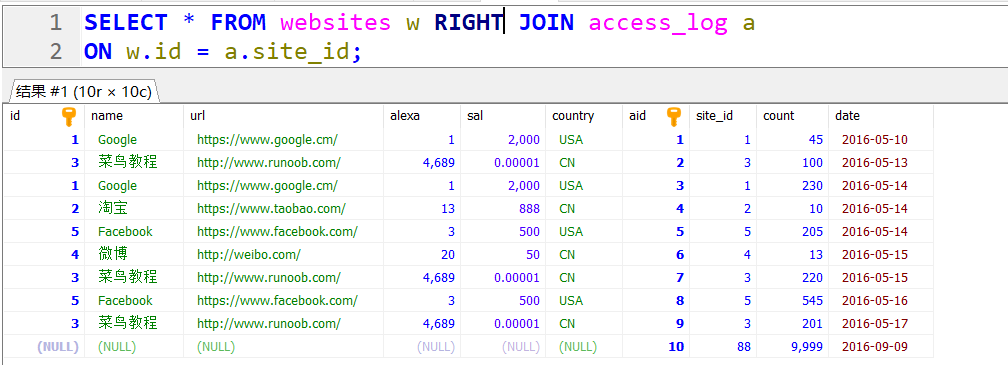
左外连接:
左外连接也是一样的道理,jjyaoao’home没有与他对应的东西,但照顾左边,显示出来
全连接:
仅仅在左连接代码与右连接代码中间加入一个union,就可以同时显示888和jjyaoao’home两行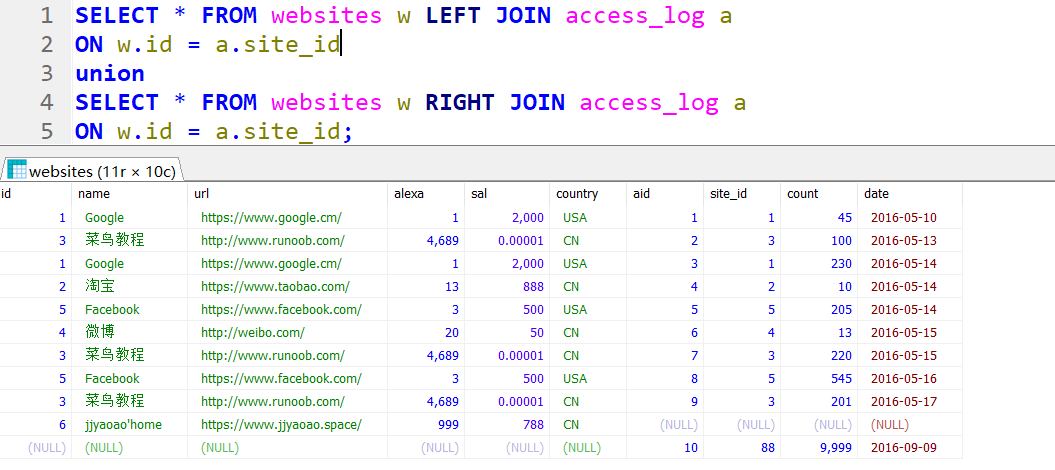
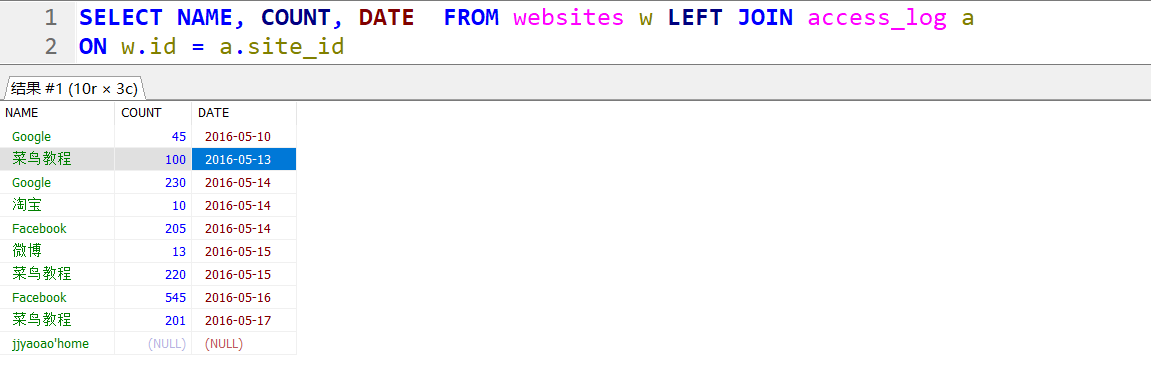
案例17. Null 处理l 函数
1 | SELECT NAME, COUNT, DATE FROM websites w LEFT JOIN access_log a |
ifnull函数将count的null值替换为了0 每个数据库都会有的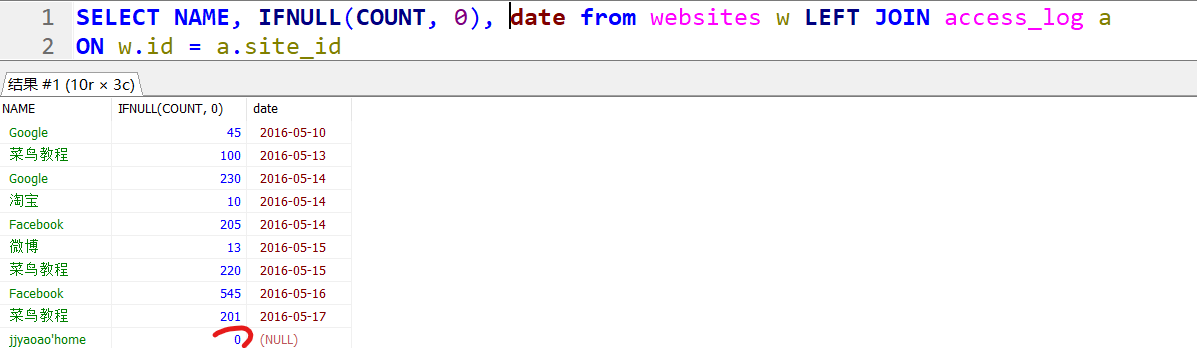
经典练习(Oracle的自带练习)
员工信息表
empno 员工编号, ename 员工名称, job 员工工作, mgr 员工的上司, hiredate 入职时间, sal 底薪, comm 奖金, deptno 部门编号
1 | -- 员工信息表 |
部门信息表
deptno 部门编号, dname 部门名称, loc 部门位置
1 | CREATE TABLE dept( |
基本查询
1 | -- 所有员工的信息 |
 分组查询
分组查询
1 | -- 每个部门的平均工资 |
子查询
1 | -- 单行子查询(> < >= <= = <>) |
SQL查询的综合案例
查询出高于本部门平均工资的员工信息
列出达拉斯加工作的人中,比纽约平均工资高的人
查询7369员工编号,姓名,经理编号和经理姓名
查询出各个部门薪水最高的员工所有信息
MySQL更多补充
COMMIT:提交事务
查看事务状态:select @@autocommit; show variables like ‘%autocommit%’;
1或者ON表示自动提交;0或者OFF表示手动提交:需要commit命令提交事务。
1 | mysql> select @@autocommit; |
设置手动提交:set autocommit=0; set autocommit=OFF;
1 | mysql> set autocommit=0; |
下面实际演示一下:
首先新开session1并建表create table test_a(id1 int,id2 int);
然后设置手动提交set autocommit=0;(这样设置只对当前session有效,是临时的,如果想要永久全局设置,修改my.cnf文件,添加autocommit=0);
再向表中插入数据insert into test_a values(1,1);
此时新开第二个session2,查询该表select * from test_a;可以发现,此时在session2上是查询不到数据的,原因就是因为在session1的事务还未提交。但是此时在session1是可以查到,这是不是和上述有点矛盾呢,其实不然,未提交的数据会临时写到内存或磁盘(内存不足的情况下),且未提交的数据上有个锁(涉及隔离级别,后续讲解),锁是只有当前事务唯一持有的,所以其他事务取不到,但当前事务是可以读取的。 <这段划重点,可以多理解一下>
接着换一种思路,在session2(自动提交)上插入一条新数据insert into test_a values(2,2);然后去session1查询,发现session1上仍然查不到新增的数据,这里有人会问session2不是设置的自动提交吗,为什么session1查不到数据呢?这是因为当session为非自动提交状态时,自事务开始后的DML操作对其都是不可见的,只有事务结束后才可见。在session1执行commit,就可以查询到新增数据了。
再看第三种情况,在session1新增一条数据,此时在session2查询是查不到新增数据的;此时在session1再新建一张表,再去session2查询,结果发现在session1未执行commit命令的情况下,session2竟然也可以查询到新增数据了。这是因为session1执行了DDL操作,触发了隐式提交事务的规则,所以其他session也可以看到DDL的修改了。但是drop命令有点特殊,如果事务还未结束,drop命令会被阻塞。
ROLLBACK:回滚事务
Rollback就是与commit相反,不提交事务,可以理解成撤回的意思
1 | mysql> insert into test_a values(1,1); |
约束
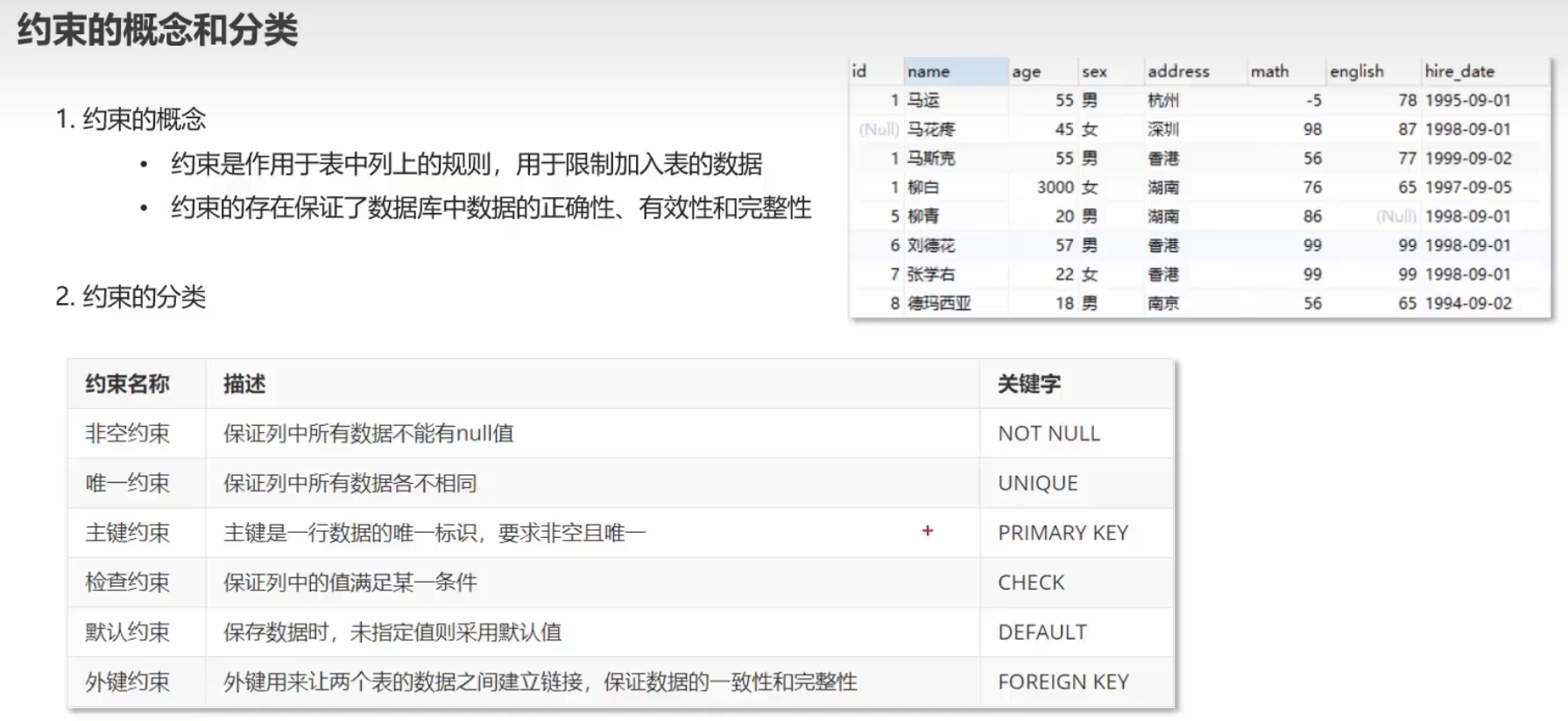
添加约束实例
id:int型主键
ename:字符串型非空唯一
joindate:日期型非空(有空值插入即报错)
salary:浮点型非空
bonus:没有数据默认为0
ps:auto_increment:数字类型+唯一约束可以加自增字段

加入自增字段
外键约束
constraint
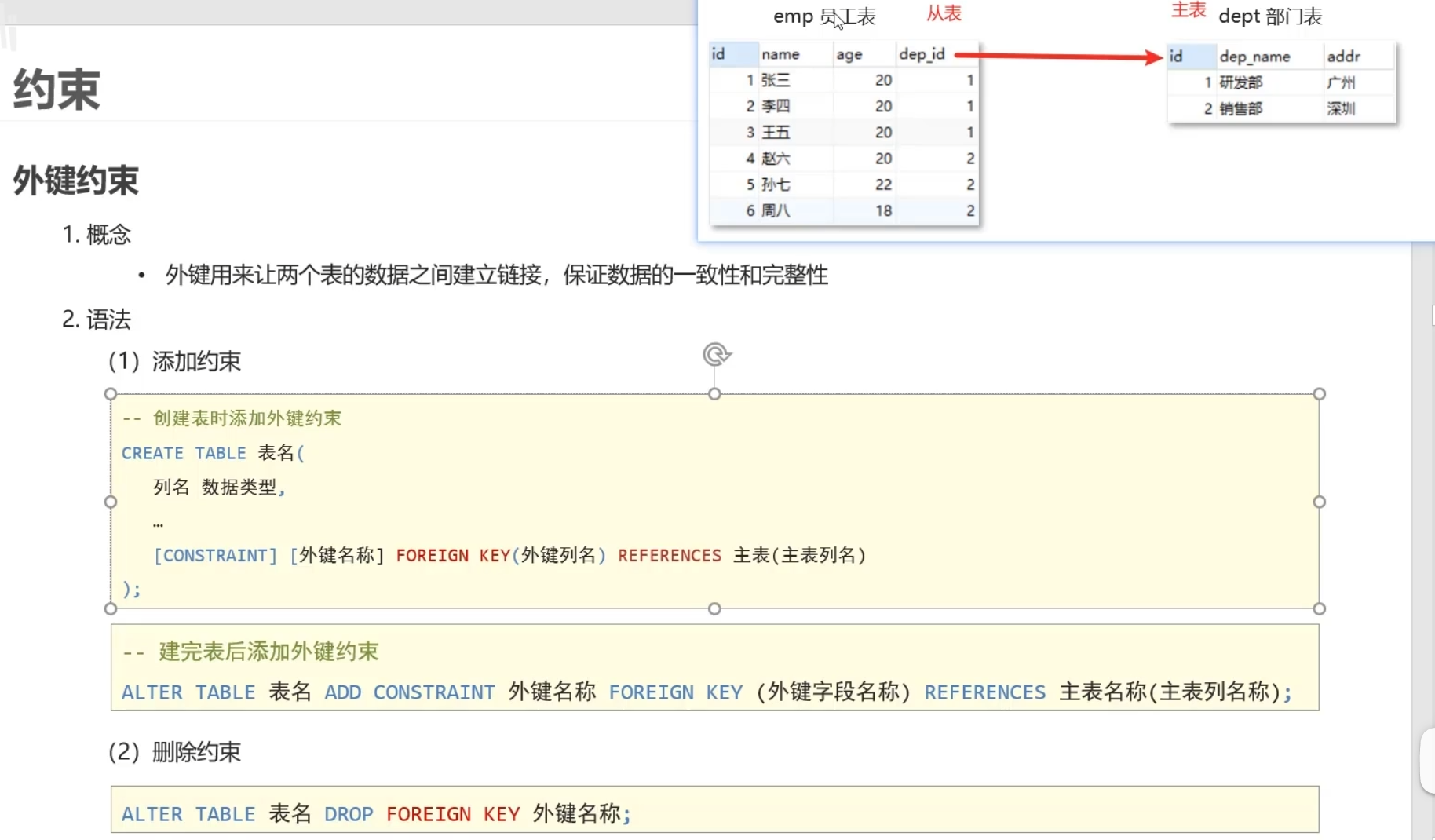
一般外键名称可以命名为fk_从表_主表,并且在从表中添加该行语句

如果这个时候想要删除主表的话会发生报错

若不在表内添加外键

数据库设计
设计概念
表间关系
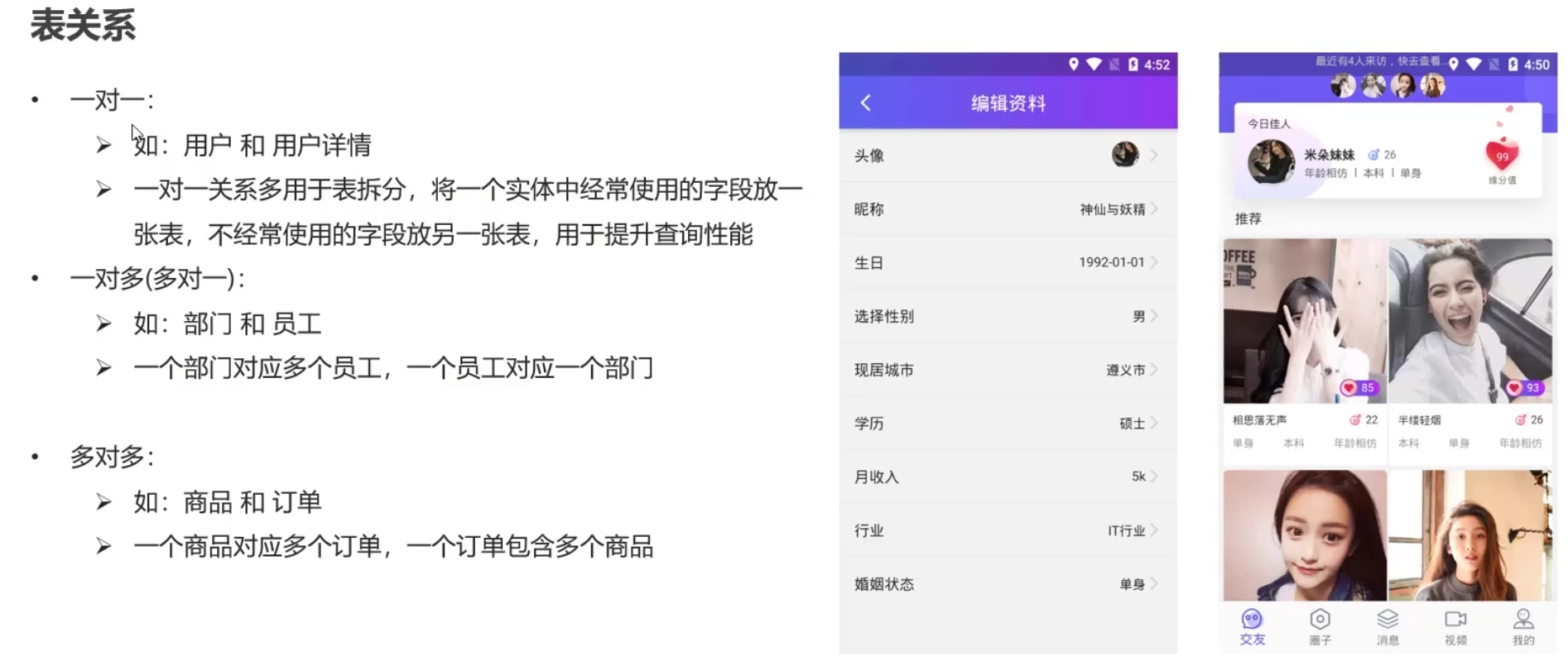
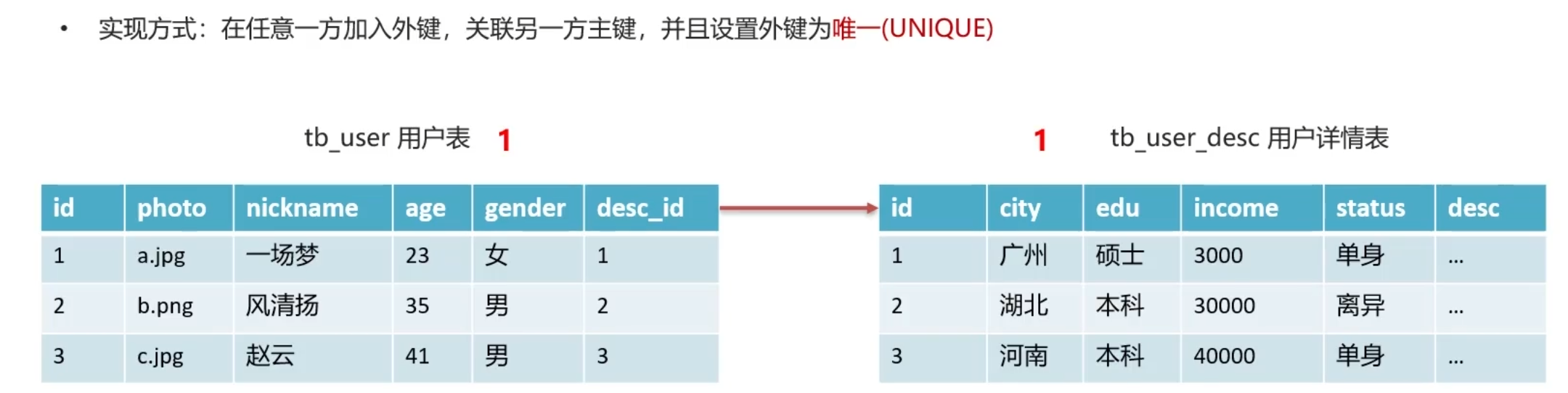
1 -> 1 添加外键,但是注意设置为unique,毕竟是1 to 1
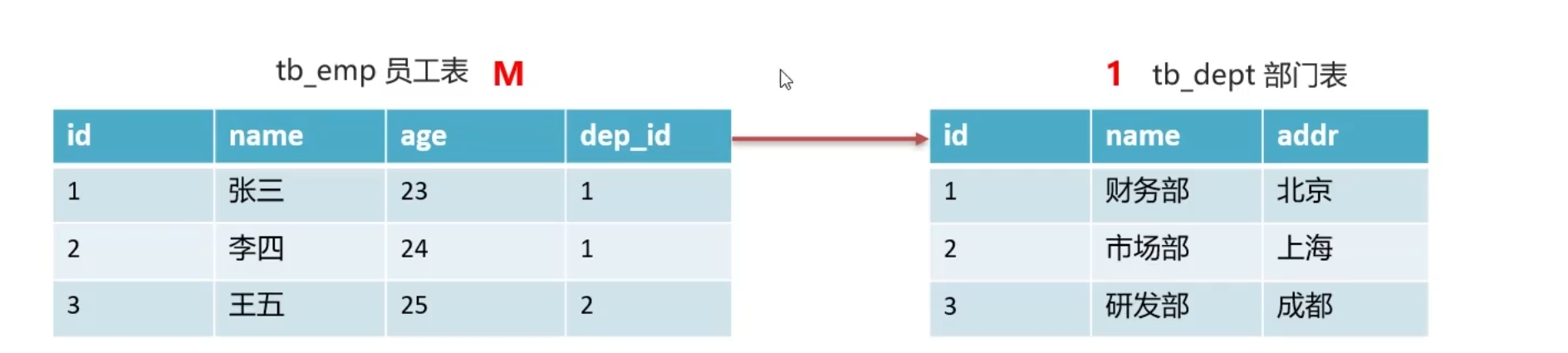
M -> 1补充,在M的一方加入外键,关联1的一方主键,主表的东西往往比附表要少
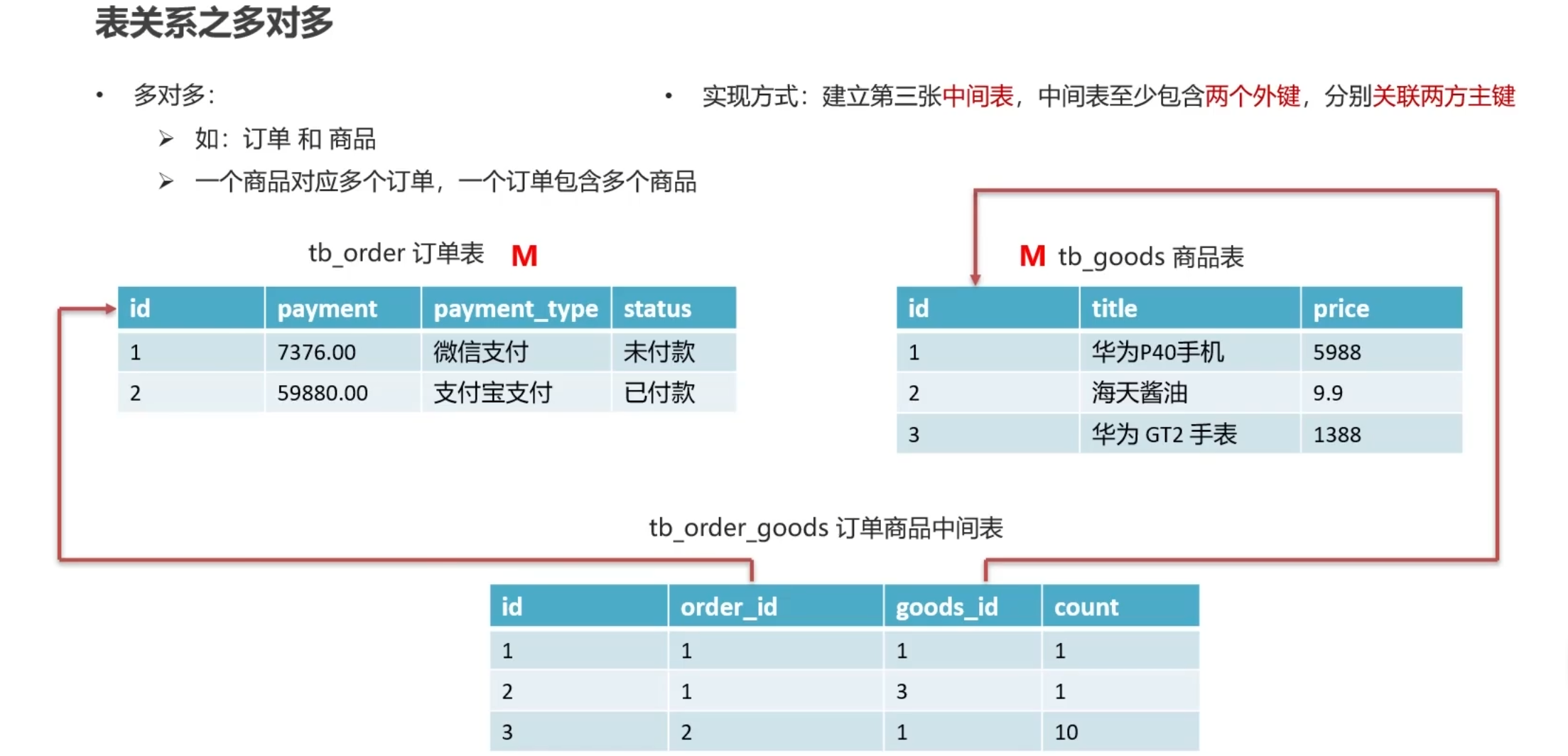
M -> M,使用中间表的方式,将两表构建关系,
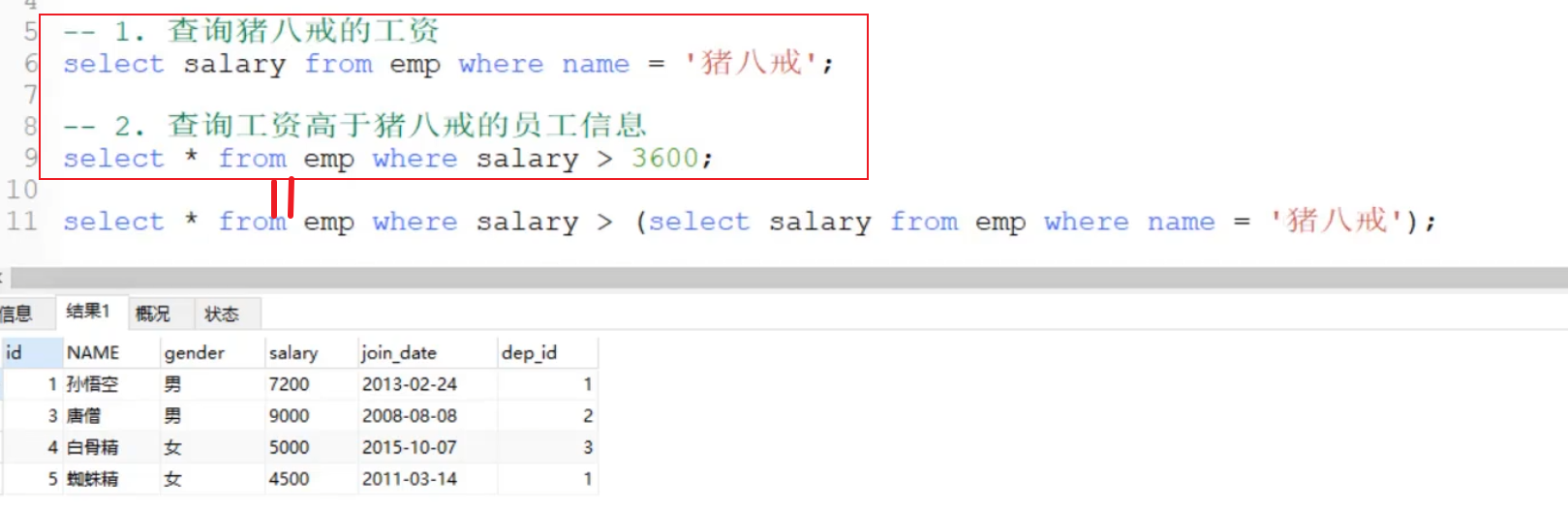
子查询
内外查询和子查询,我的评价是pandas
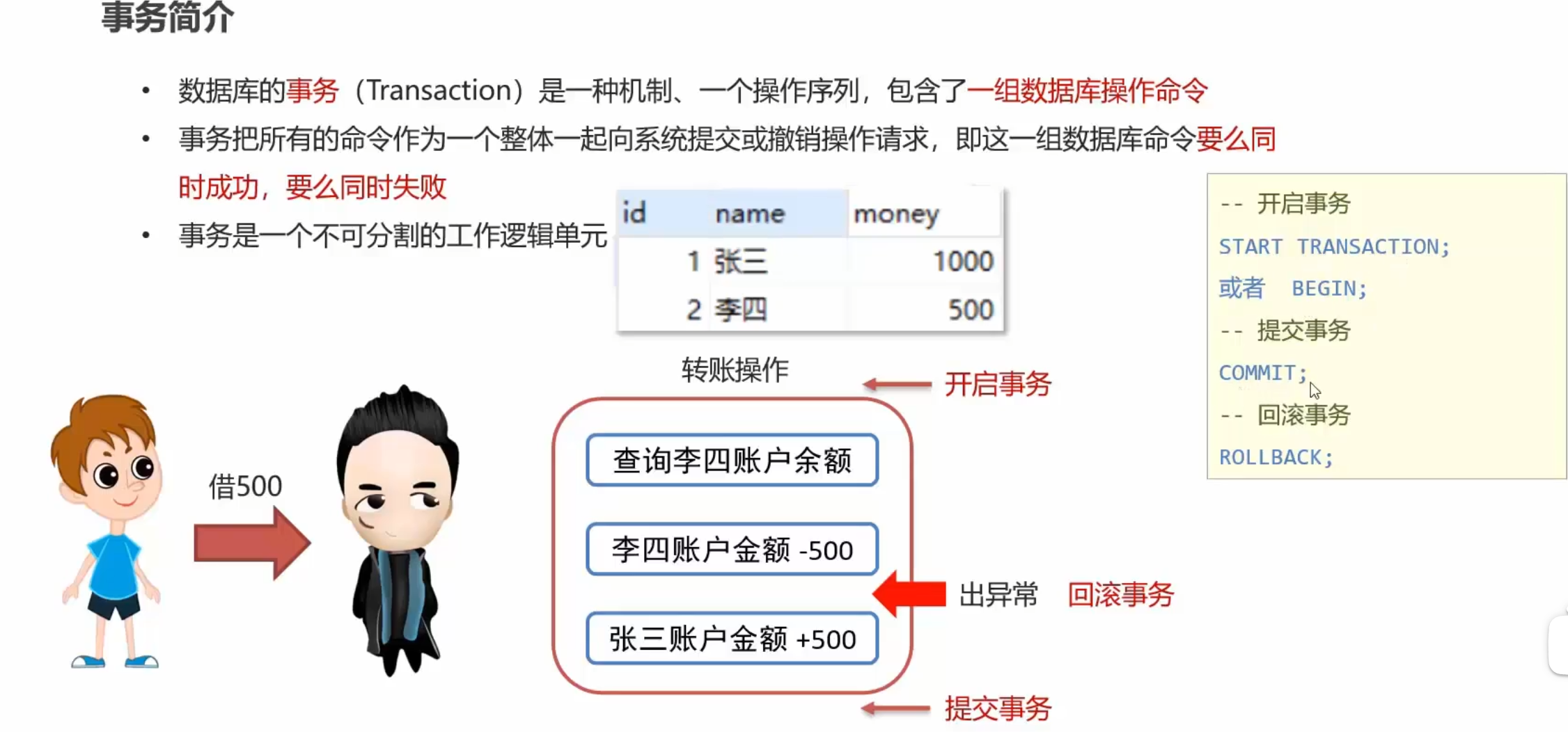
事务
事务是为了避免特殊情况下有一些操作本来该同时执行的,但是中途出现报错,导致最终结果出现问题而提出的技术手段。
简单来说就是用BEGIN – COMMIT\ROLLBACK三个部分来执行原子操作,BEGIN代表操作开始的flag,commit代表持久化更改数据,rollback就是把这次事务执行语句影响的结果复原,也就是从BEGIN到这一句的所有影响消除。通常commit和rollback在语句末尾任选一句放即可。当数据库数据变化不对劲的时候及时使用rollback,解决问题后用commit

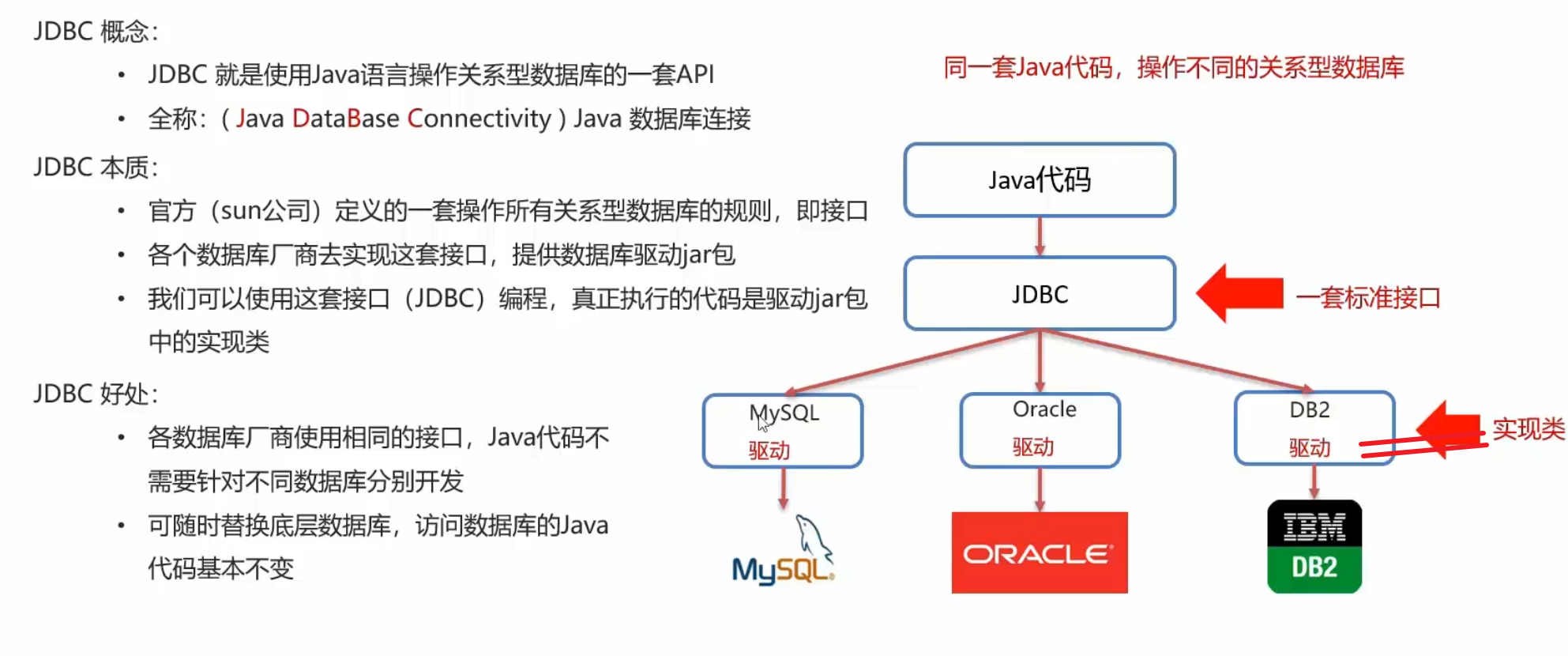
JDBC
JDBC的概念
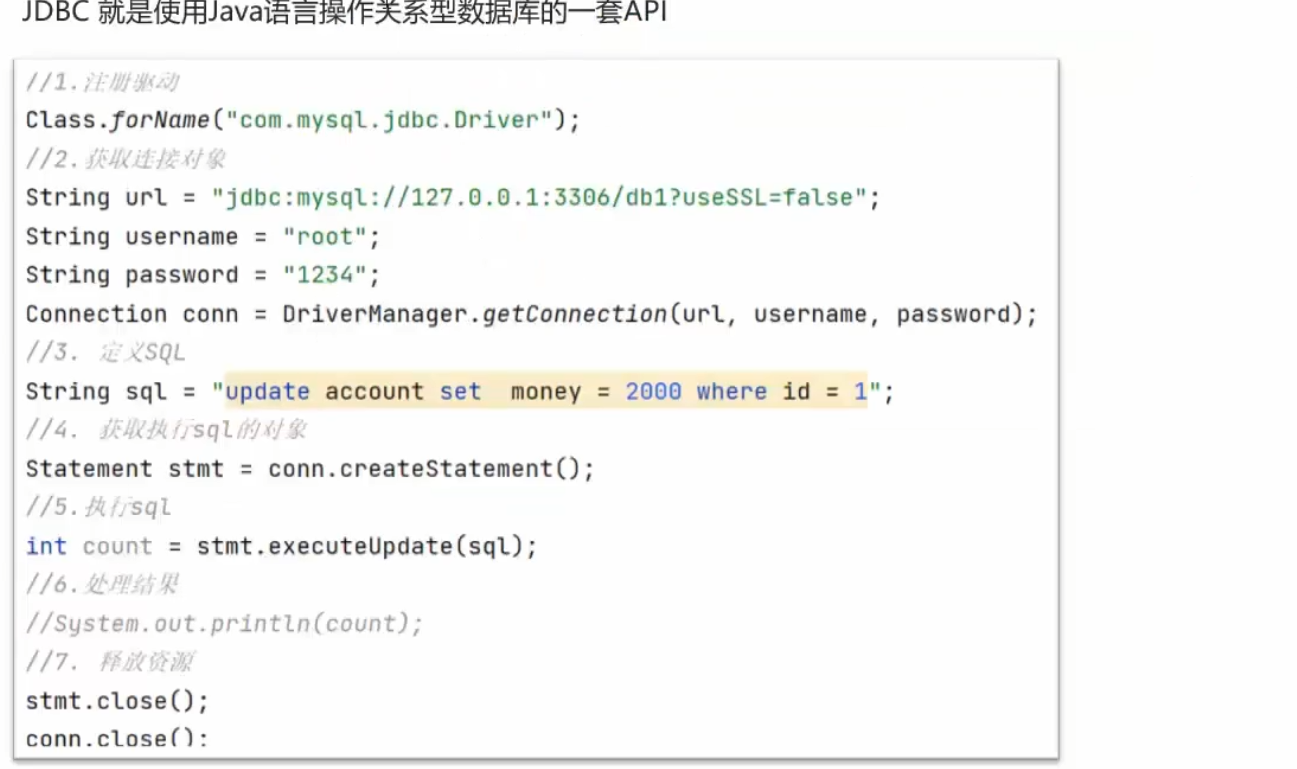
步骤
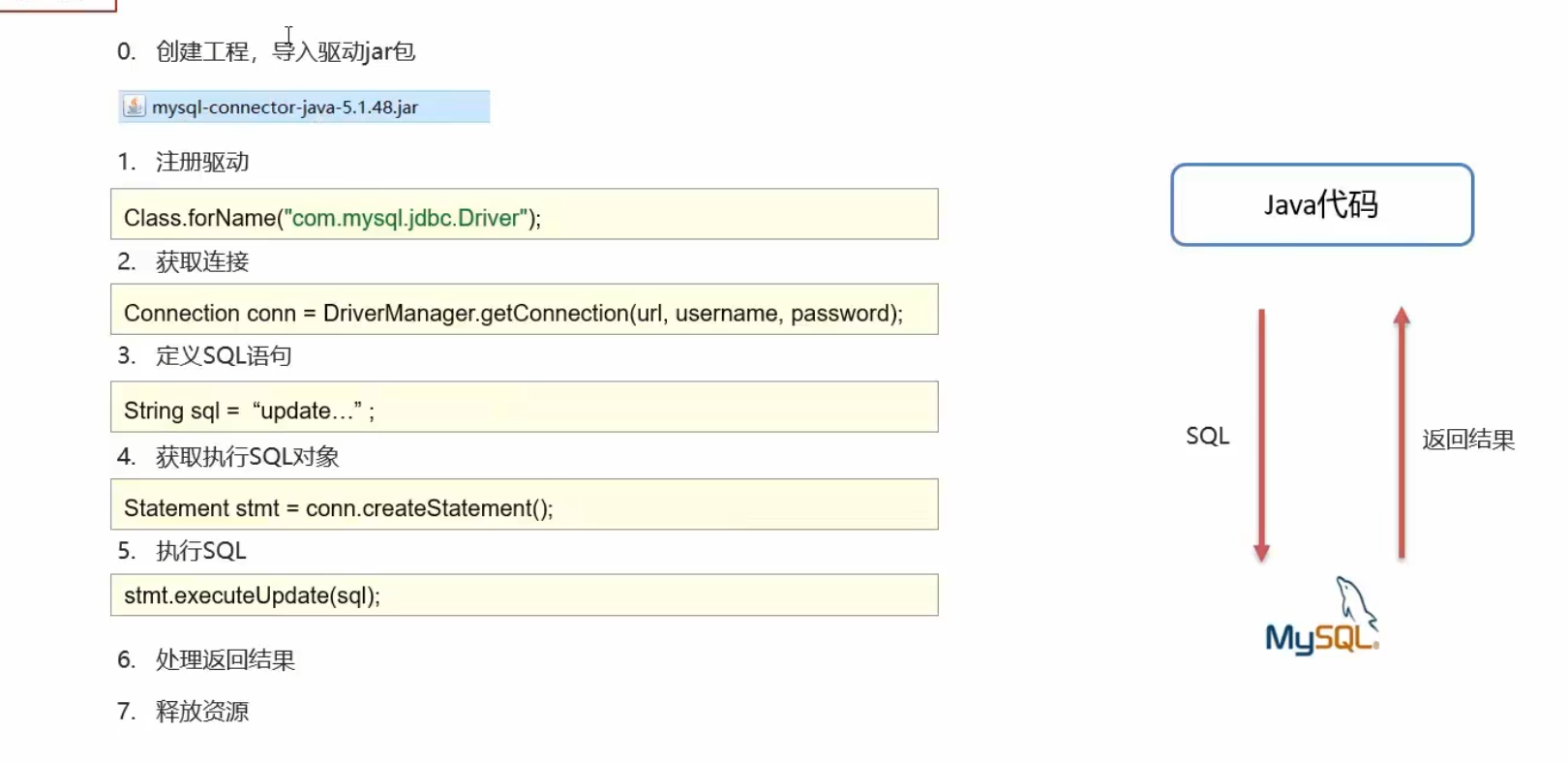
基本框架
框架
1 | public class demo { |
返回值:1
JDBC API
DriverManager

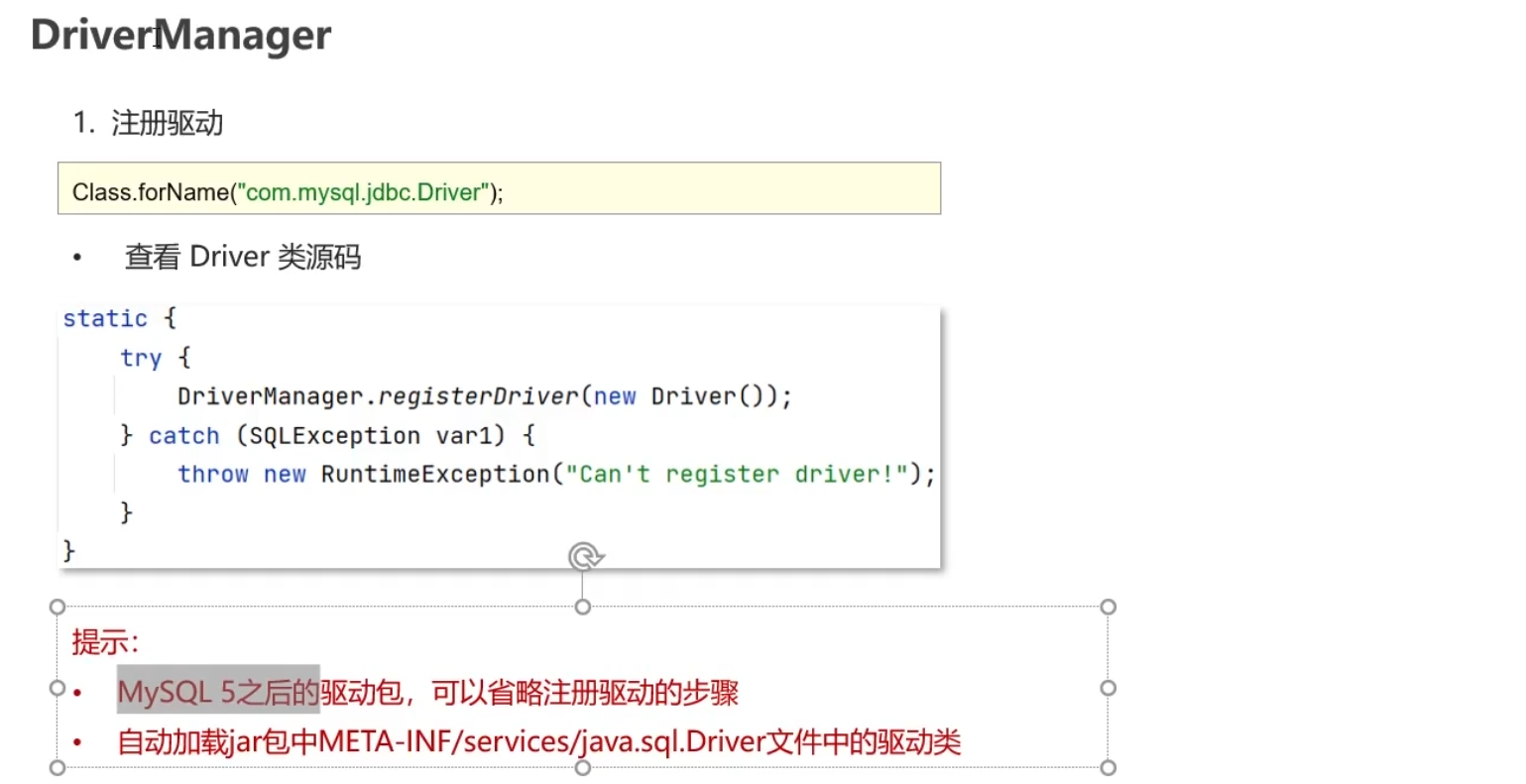
这里可能会有疑问为什么我们用forname注册驱动,却说他是DriverManager注册的呢?其实是因为我们可以点进去字符串中的Driver,可以看到里面有一个静态的方法,调用时自动启用DriverManager。
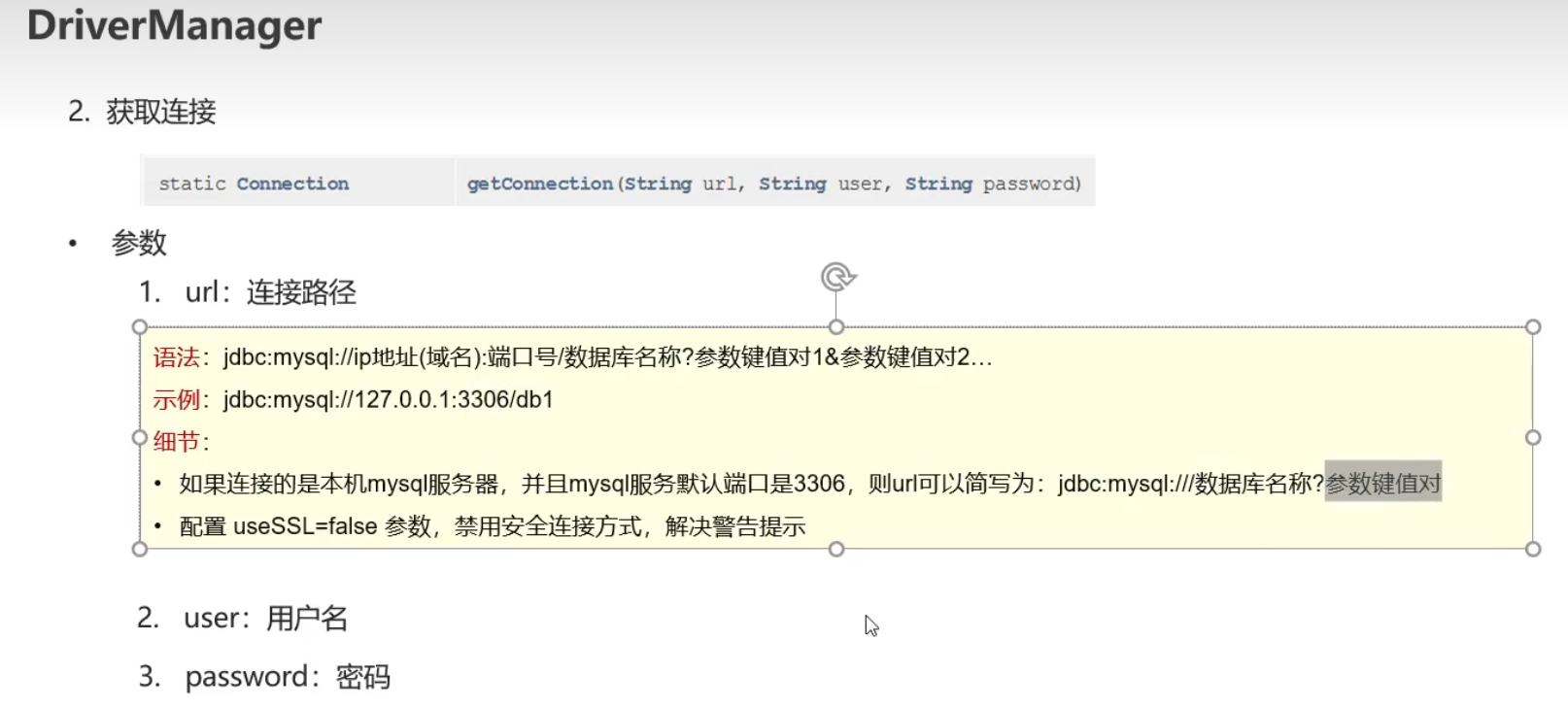
Connection

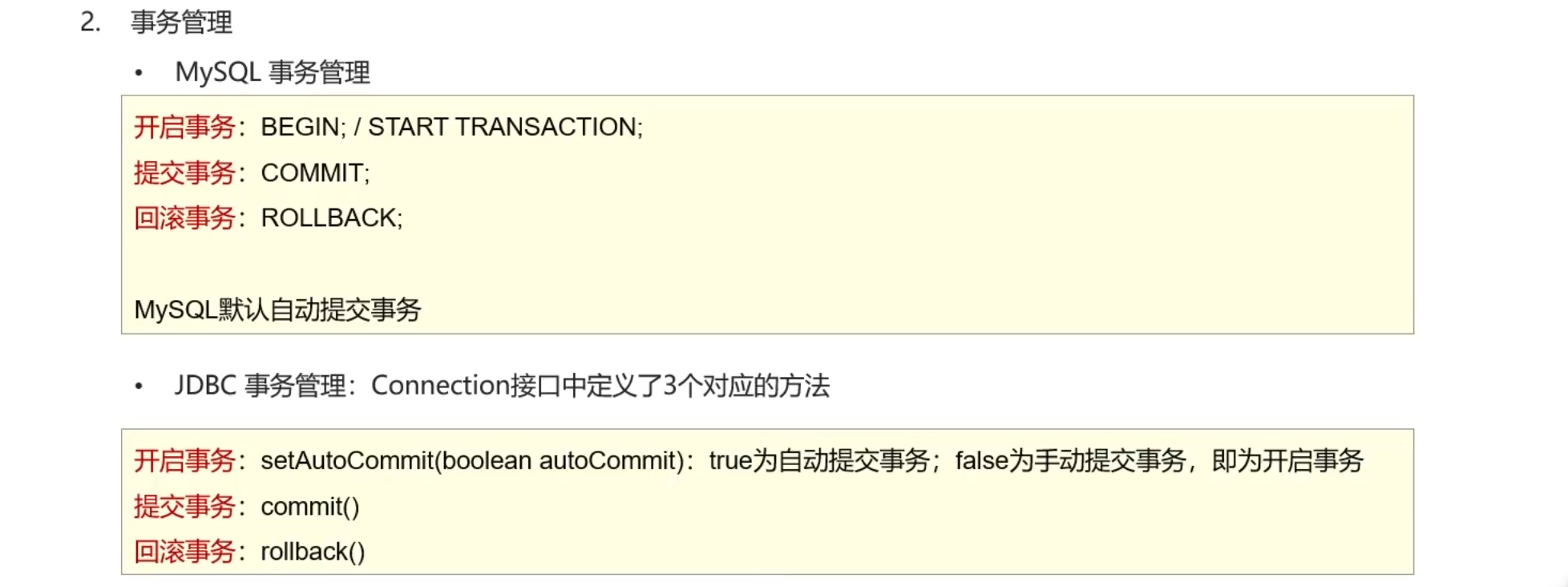
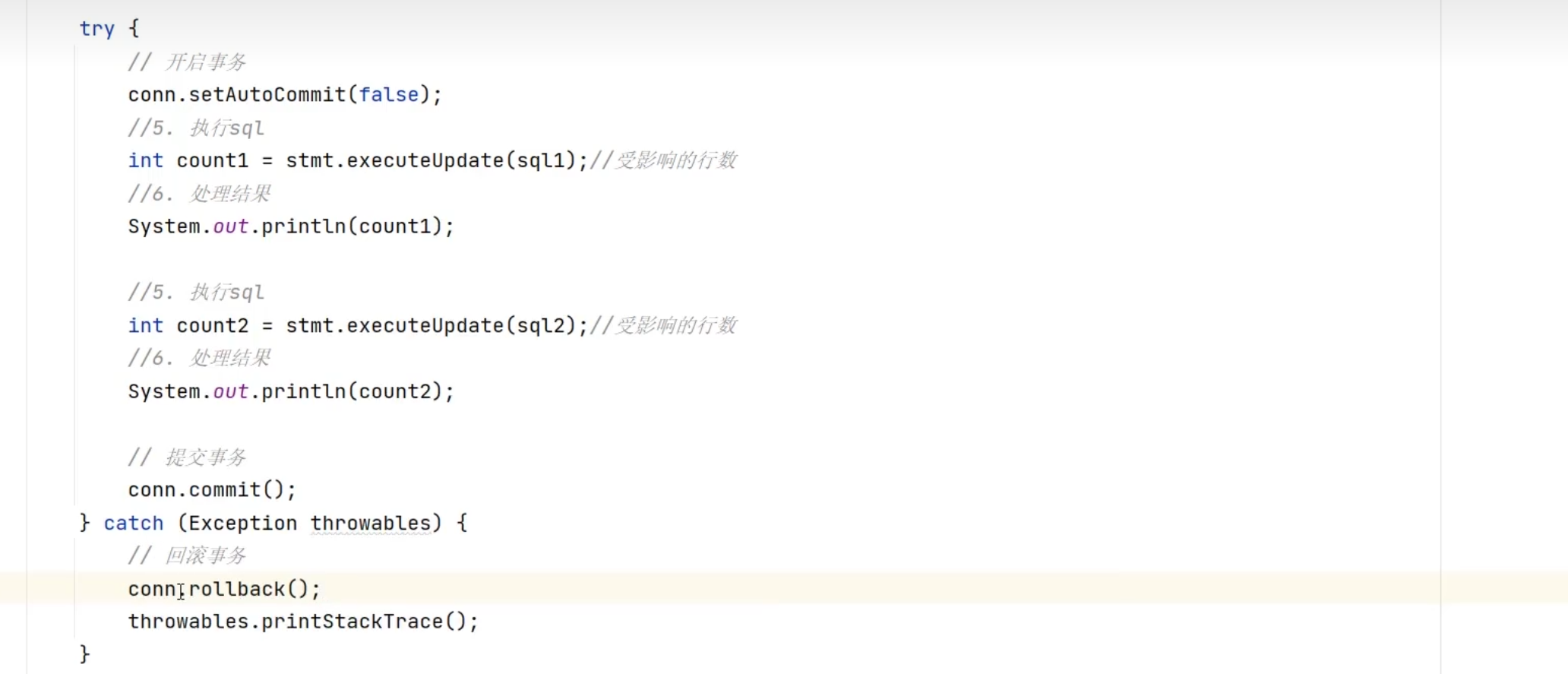
事务管理+trycatch
当程序能顺利执行到commit()即运行完毕,不然就在catch中进行回滚,close可以弄到finally里
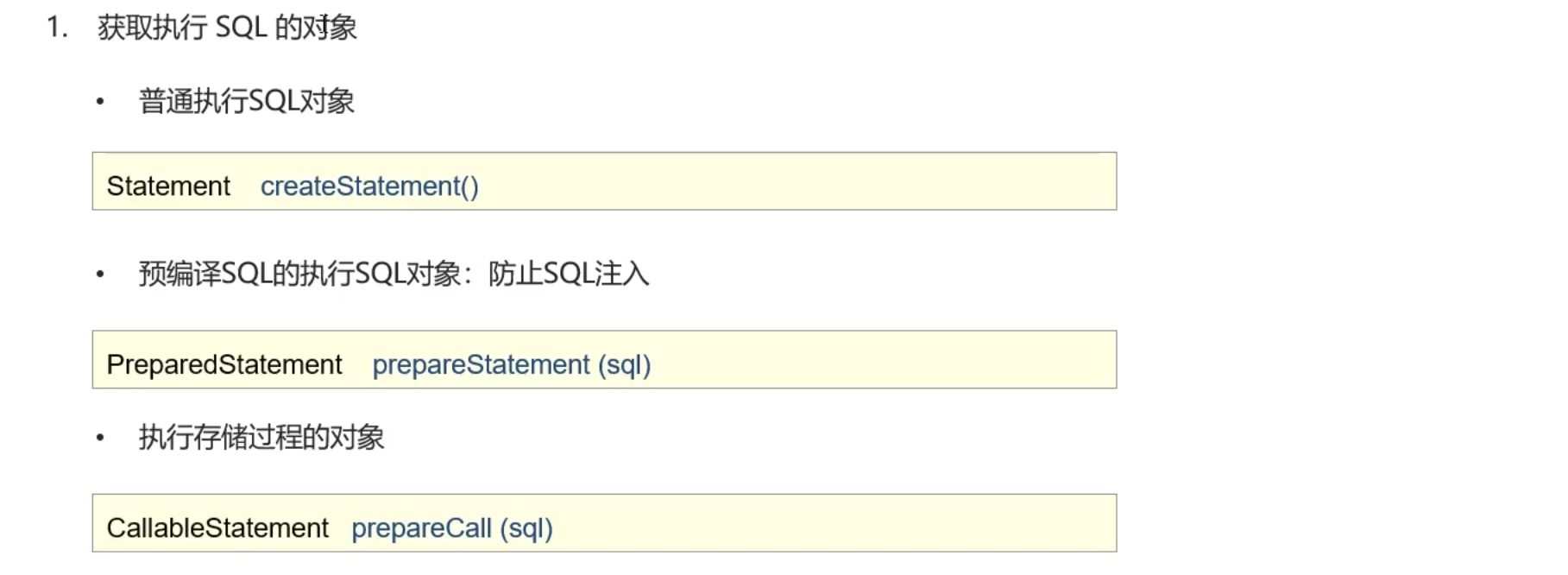
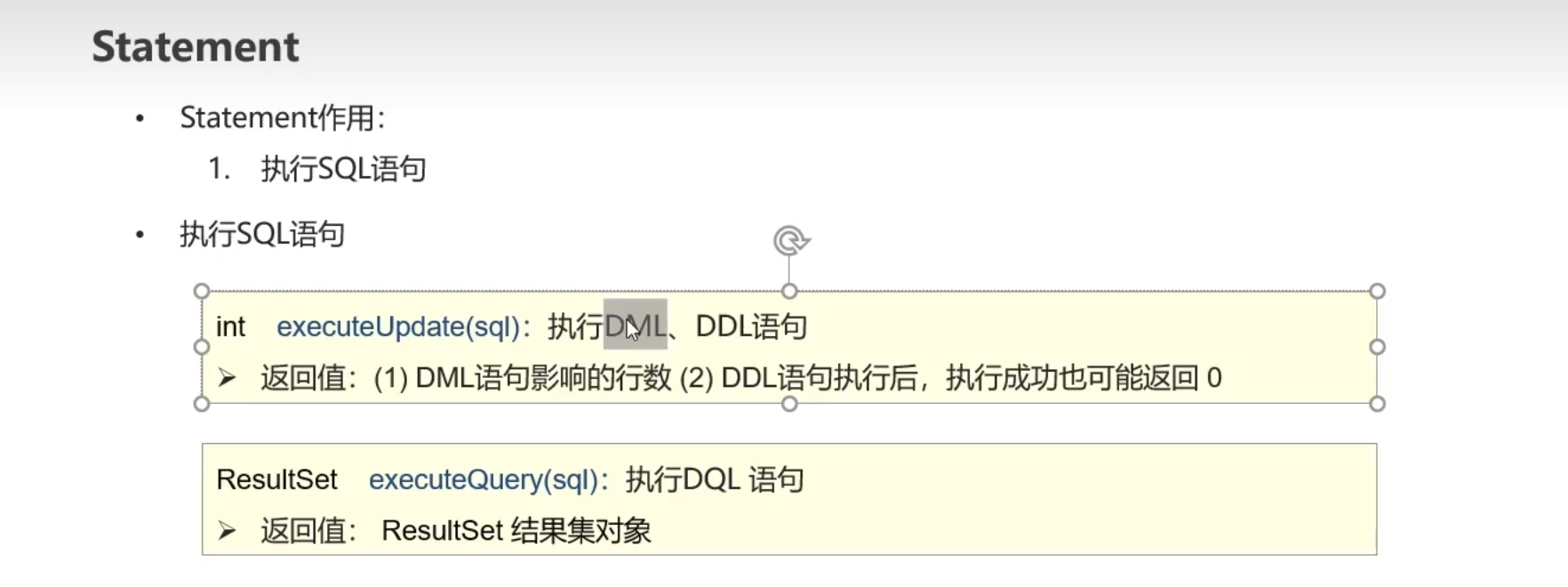
Statement
DDL:对数据表、库进行增删改查
DML:对数据的增删改
DQL:对数据的查询操作
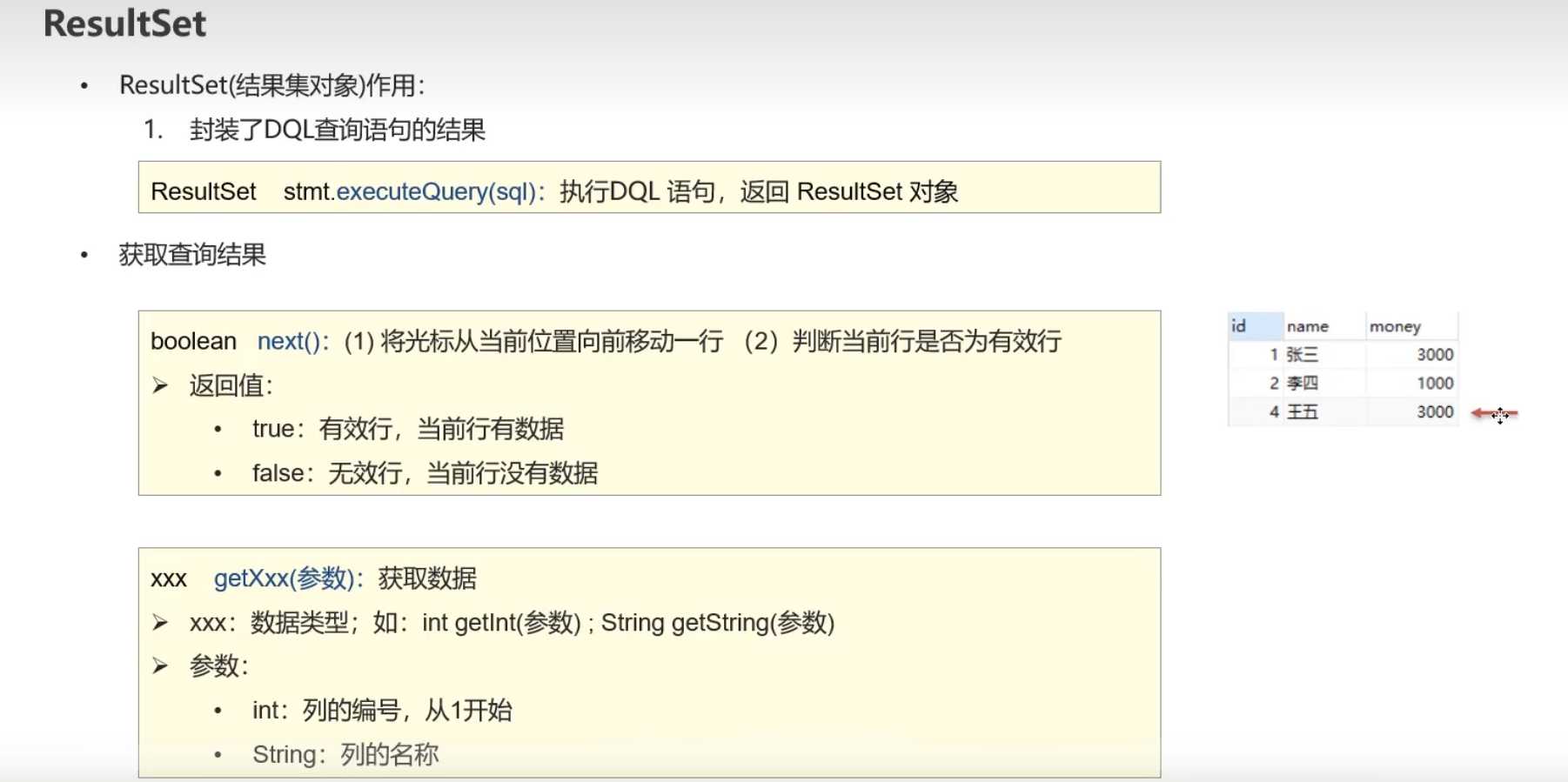
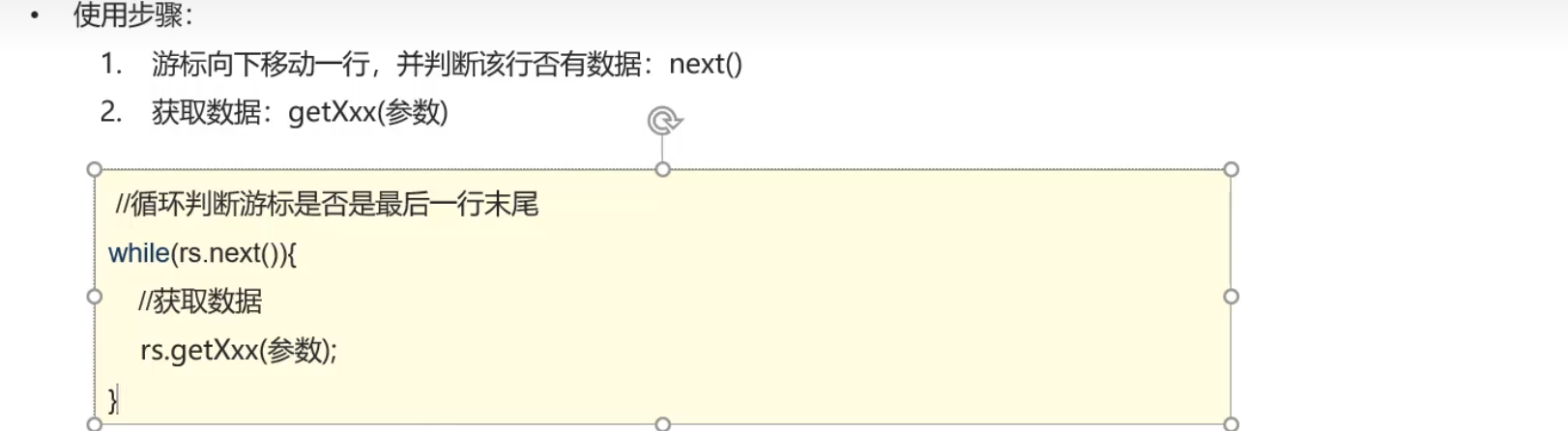
ResultSet
需要注意的就是参数部分,列的编号从1开始。
1 | public class demo02 { |
1 | 1 |
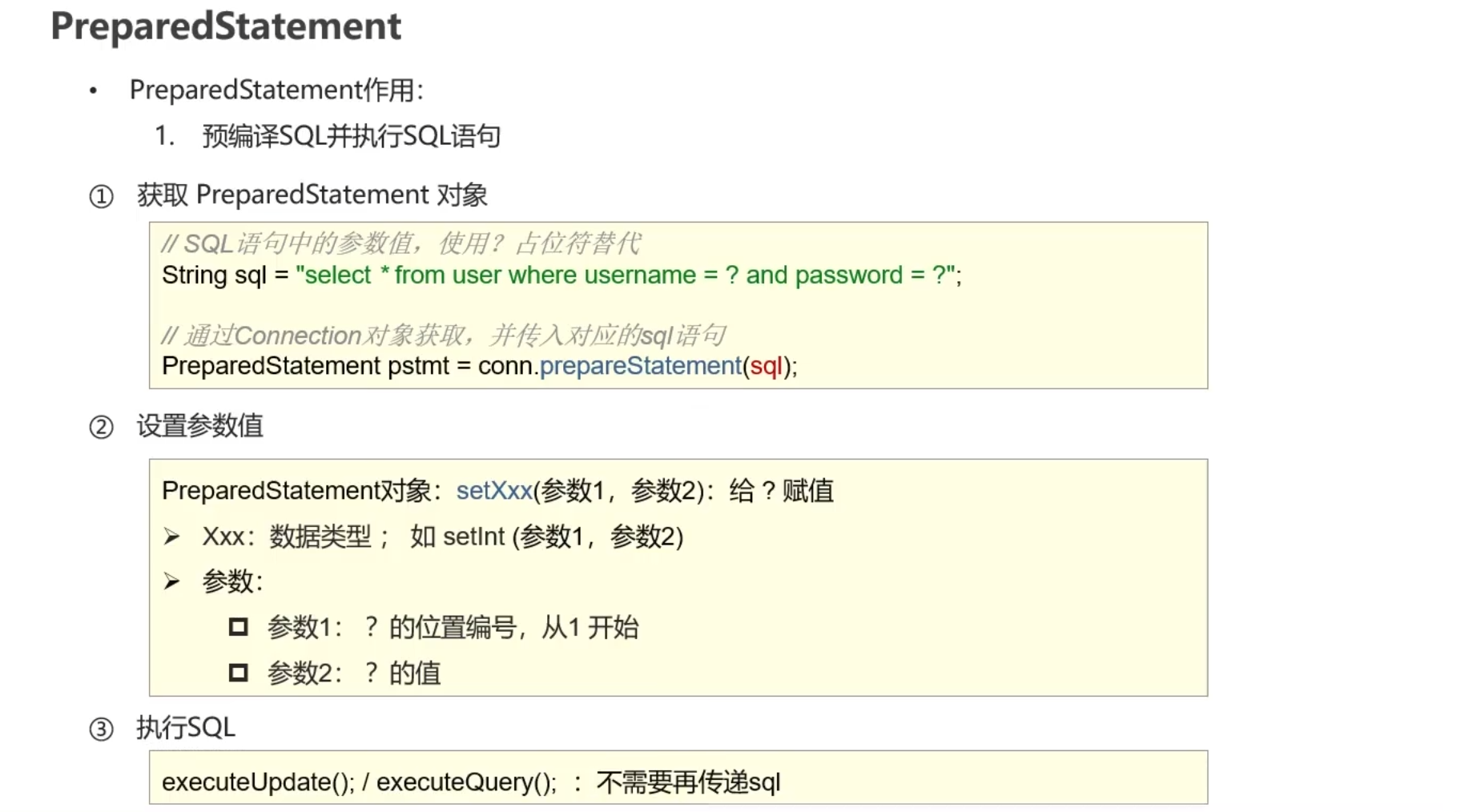
PreparedStatement
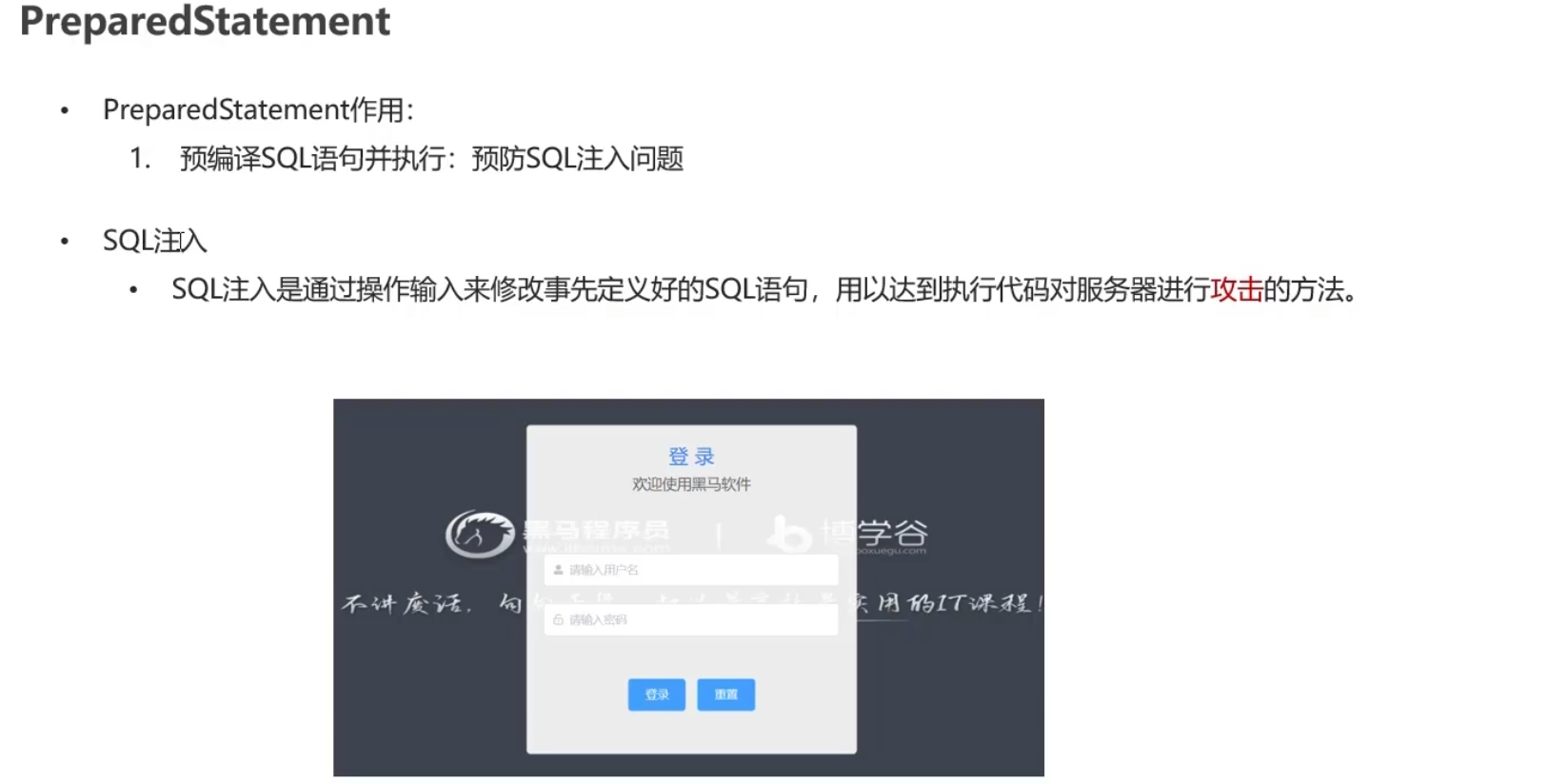

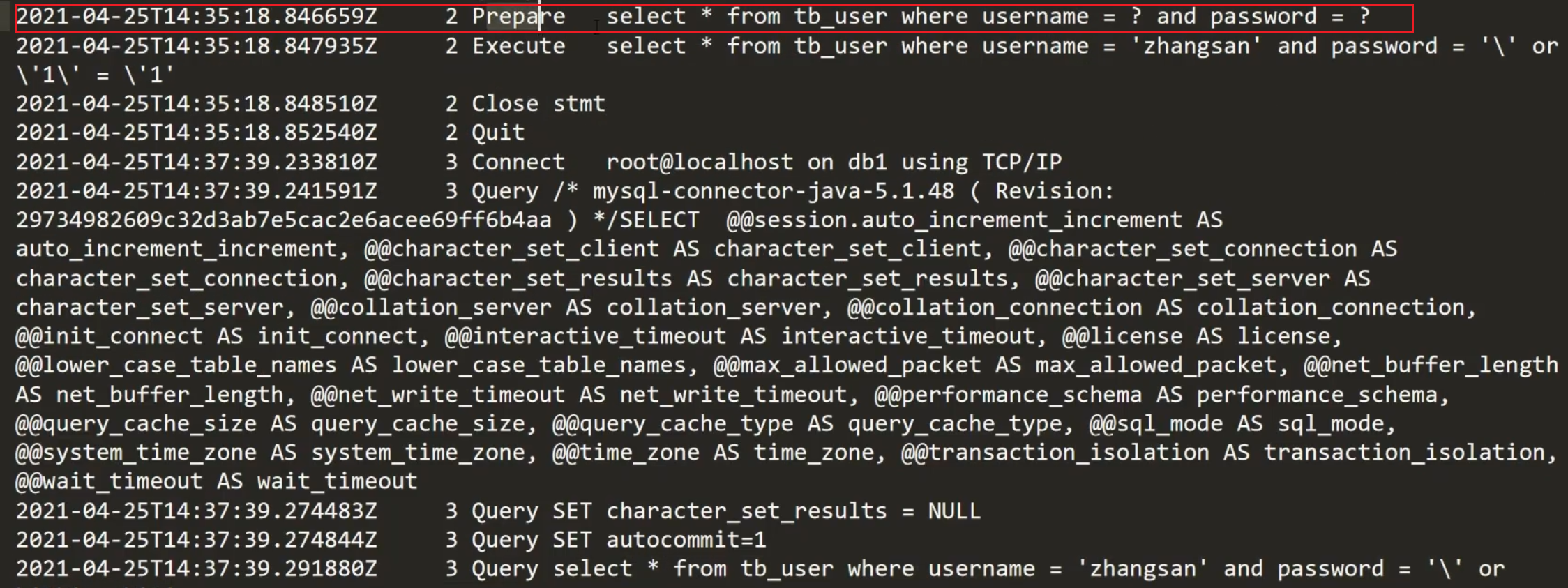
类似于将原来的password的’’给截断,然后使得他的意思发生改变。
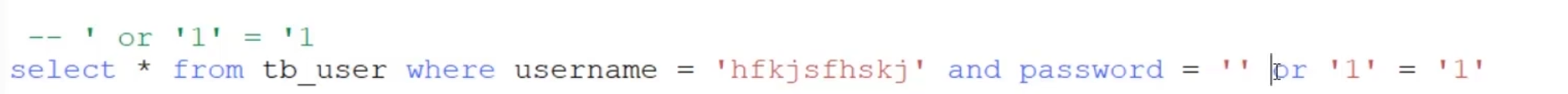
其实就干了一件事情
将文本数据中的特殊字符,加一个转译号

原理
注意:默认是没有开启预编译功能的
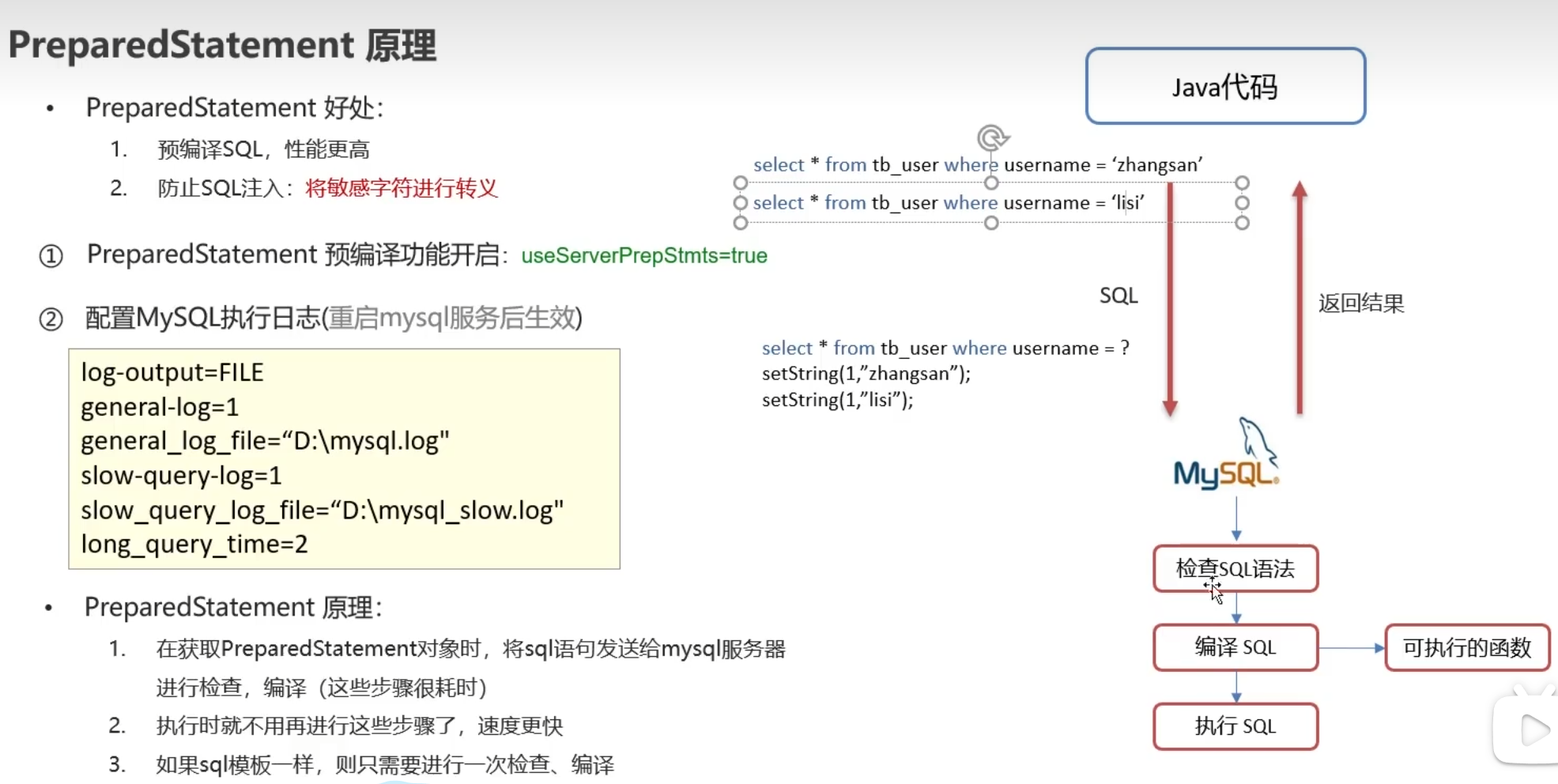
开启之后去mysql的myini文件加入执行日志的配置(上图黄色部分)后可看出他的原理,预编译需要开启,红色部分为已开启。
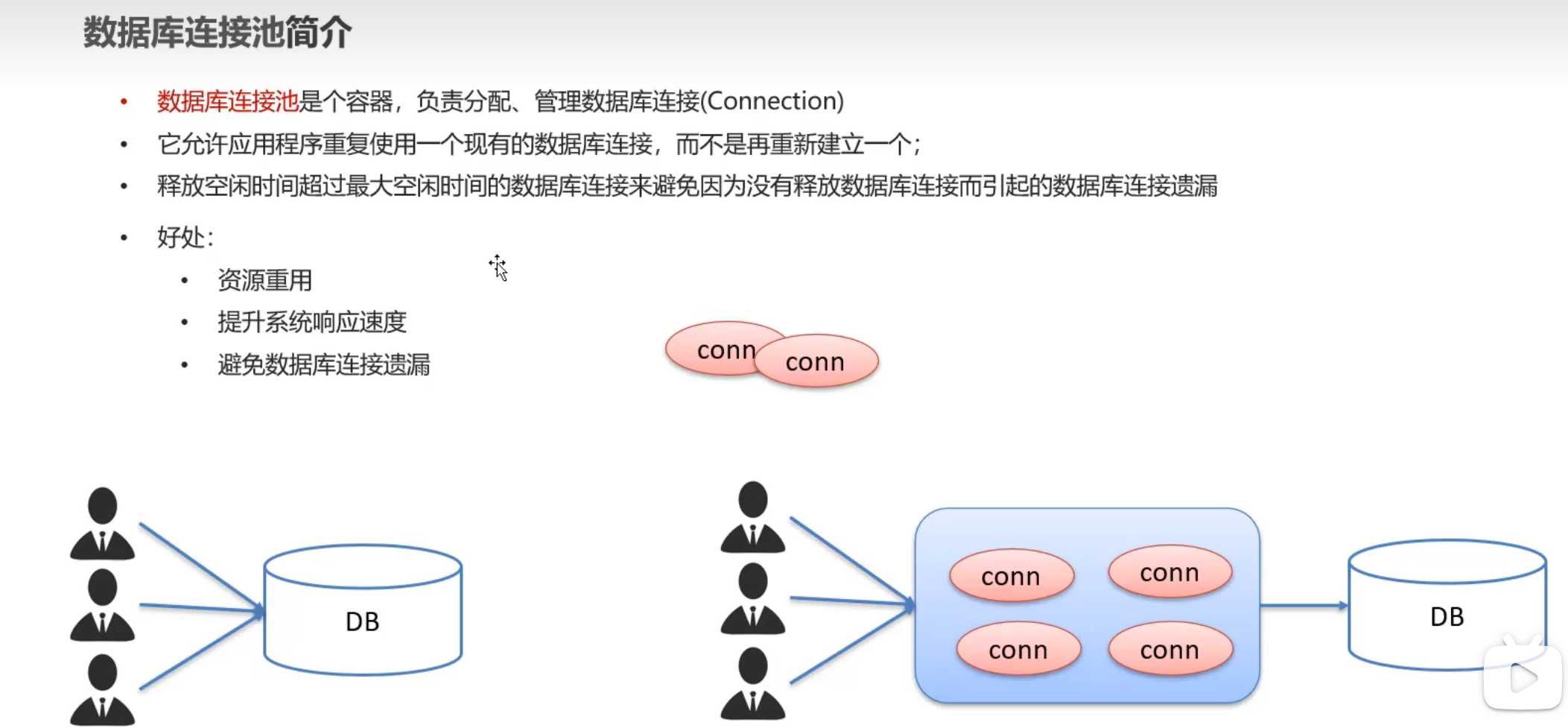
数据库连接池
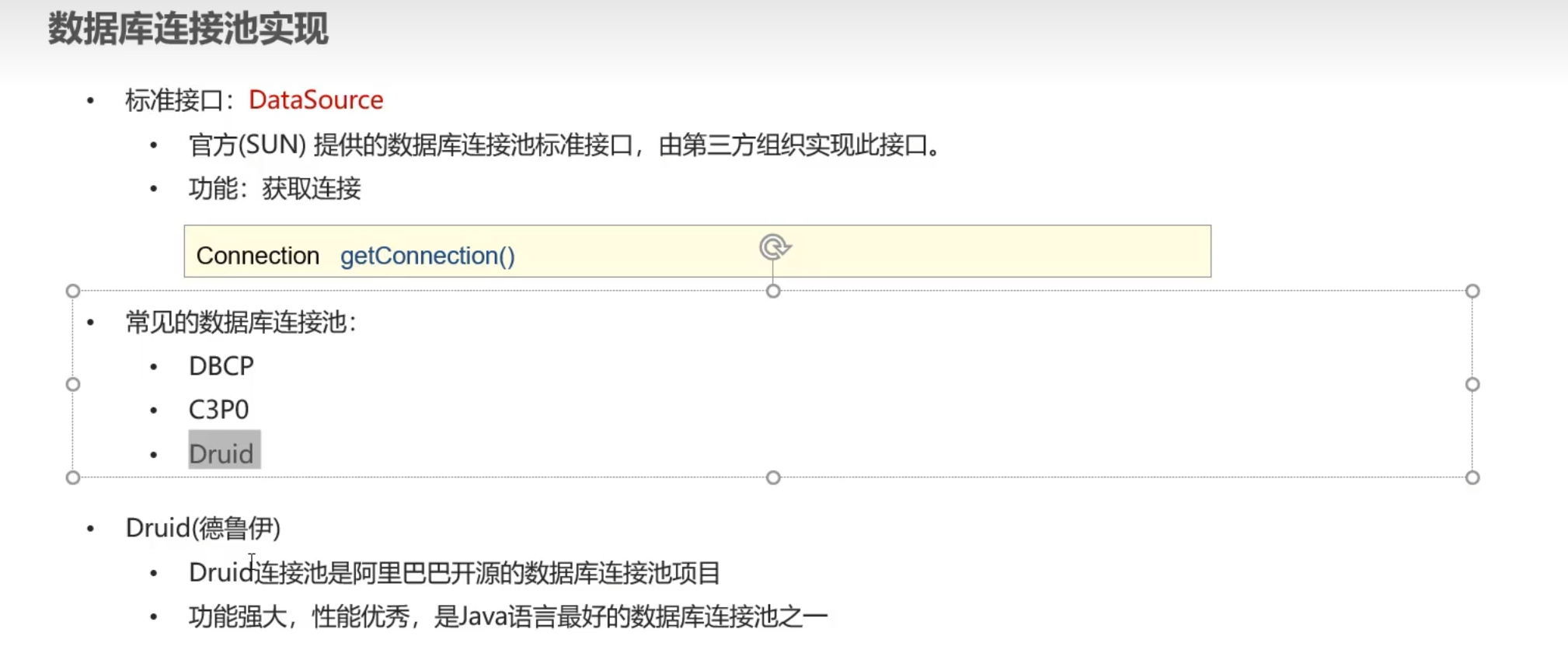
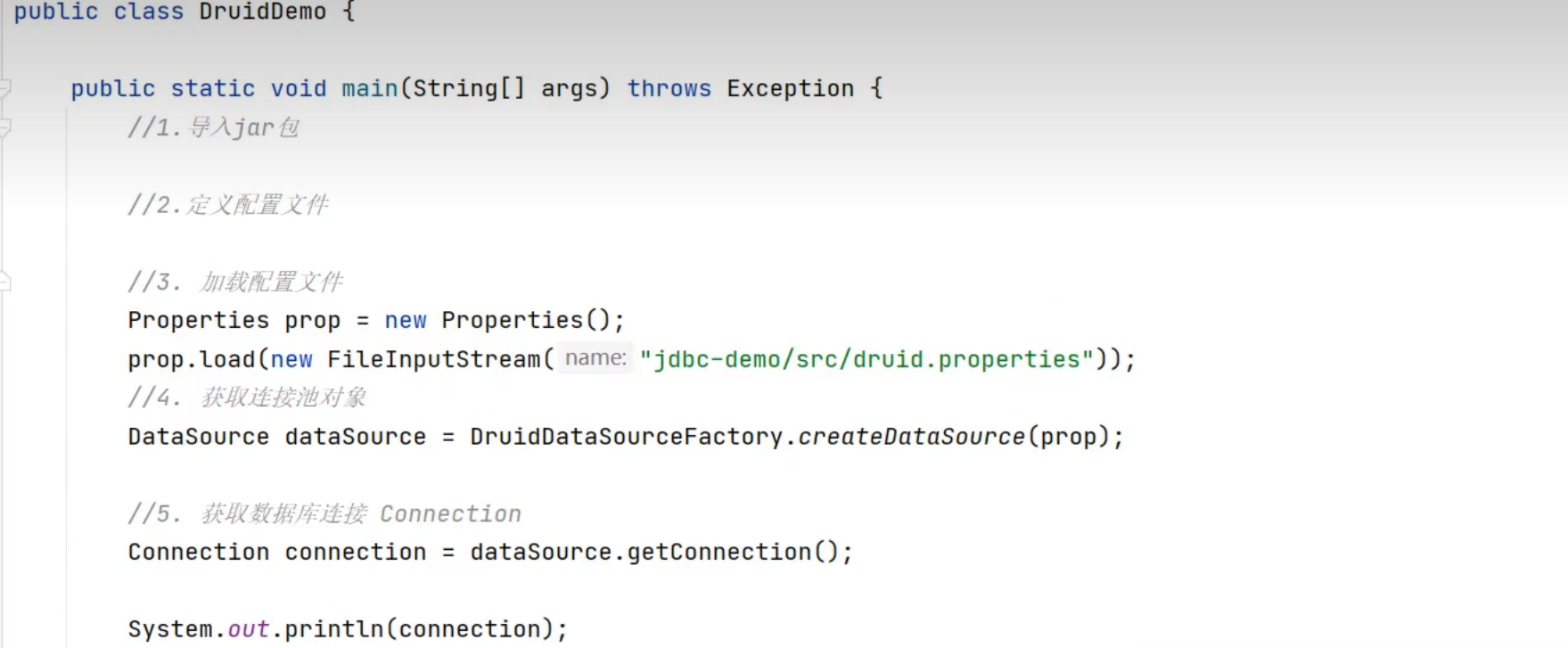
使用框架
增删改查
大部分内容固定,不固定的特殊标识
1 |
|
 微信
微信 支付宝
支付宝

