
基于知识图谱的推荐系统基础
TransX_原理
TransE
最早的翻译距离模型,13年提出。
负采样,简单来说就是人为给规整的数据集加入噪声,增强泛化能力。也就是这里将h和t在一定范围内随机替换一个数值,减缓过拟合。

在one2one的应用场景中,TransE是有效果的,但是一旦出现one2N,N2one,N2N,就束手无策。
- 原理
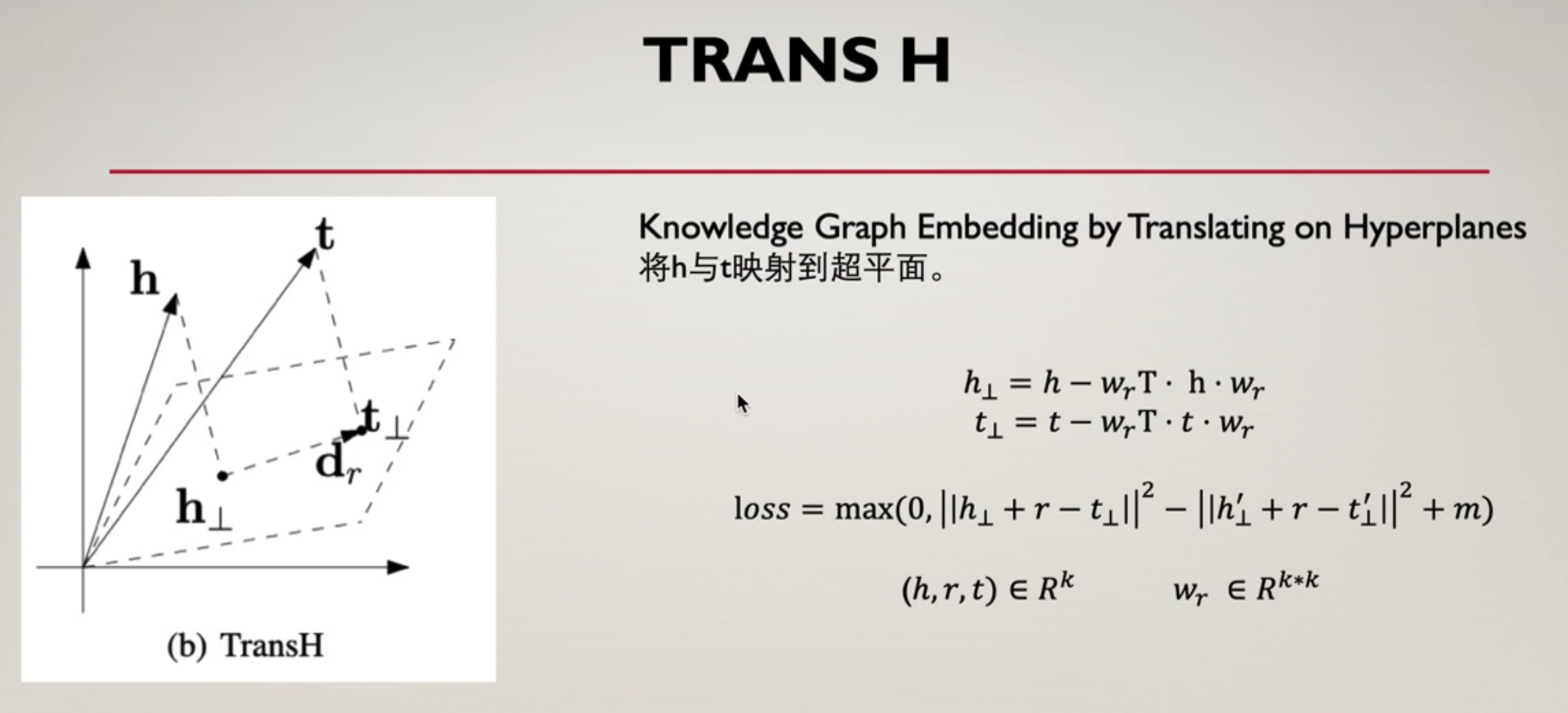
TransH 全称是 Knowledge Graph Embedding by Translating on Hyperplanes, 直译为在超平面上的知识图谱词嵌入。 由于 TransE 在 对多, 多对一, 多对多关系时或者自反关系上效果不是很好, 所以 TransH 被提出。
自反关系: 指 head 和 tail 相同, 例如:
(曹操 欣赏 曹操) 这是自反关系, (曹操 欣赏 司马懿) 这不是自反关系。
一对一:指同一组 head, relation 只会对应一个 tail。例如:
(司马懿 妻子 张春华),(诸葛亮 妻子 黄月英)
一对多:指同一组 head, relation 会对应多个不同的 tail。例如:
(司马懿 小妾 柏灵筠),(司马懿 小妾 静姝)
多对一:指多个 head 会对应同一组 relation, tail。例如:
(司马师 父亲 司马懿), (司马昭 父亲 司马懿)
多对多:指多组 head, relation 对应多个 tail。例如:
(司马懿 懂得 孙子兵法),(司马懿 懂得 三略),(司马懿 懂得 六韬)k
(诸芶亮 懂得 孙子兵法),(诸葛亮 懂得 三略),(诸葛亮 懂得 六韬)
(周公瑾 懂得 孙子兵法),(周公瑾 懂得 三略),(周公瑾 懂得 六韬)
如果还是很模糊, 我们来看下面这张图来区别一对一与多对多的关系。
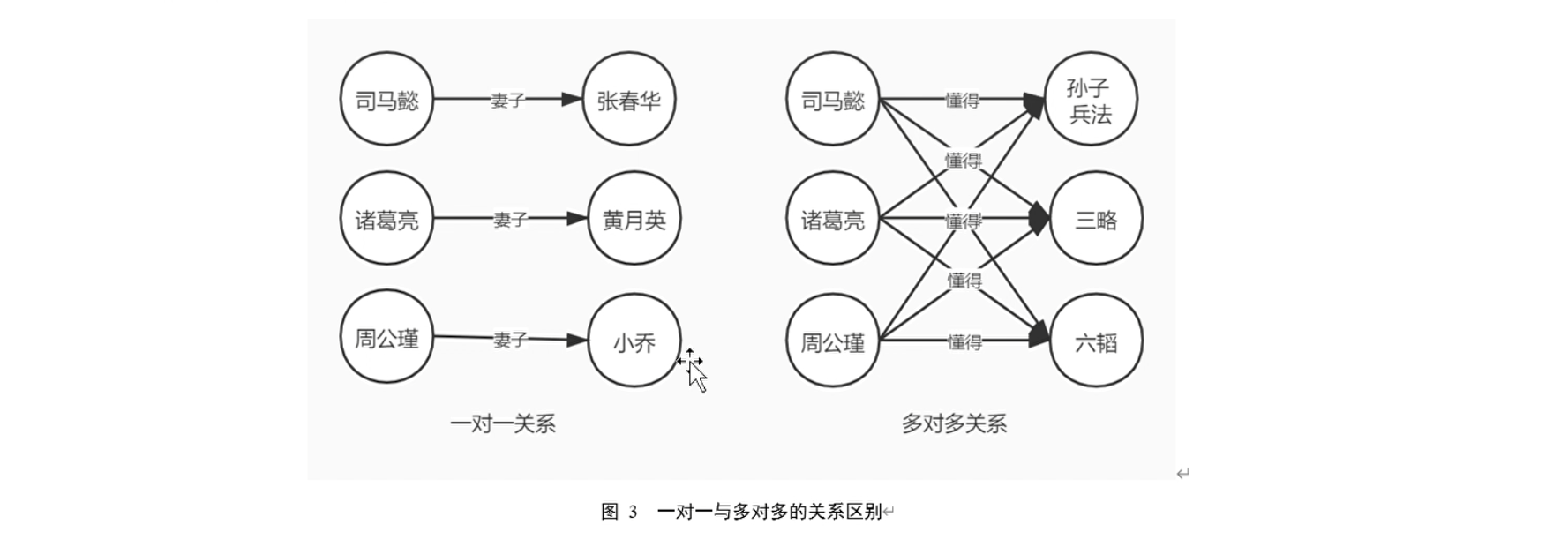
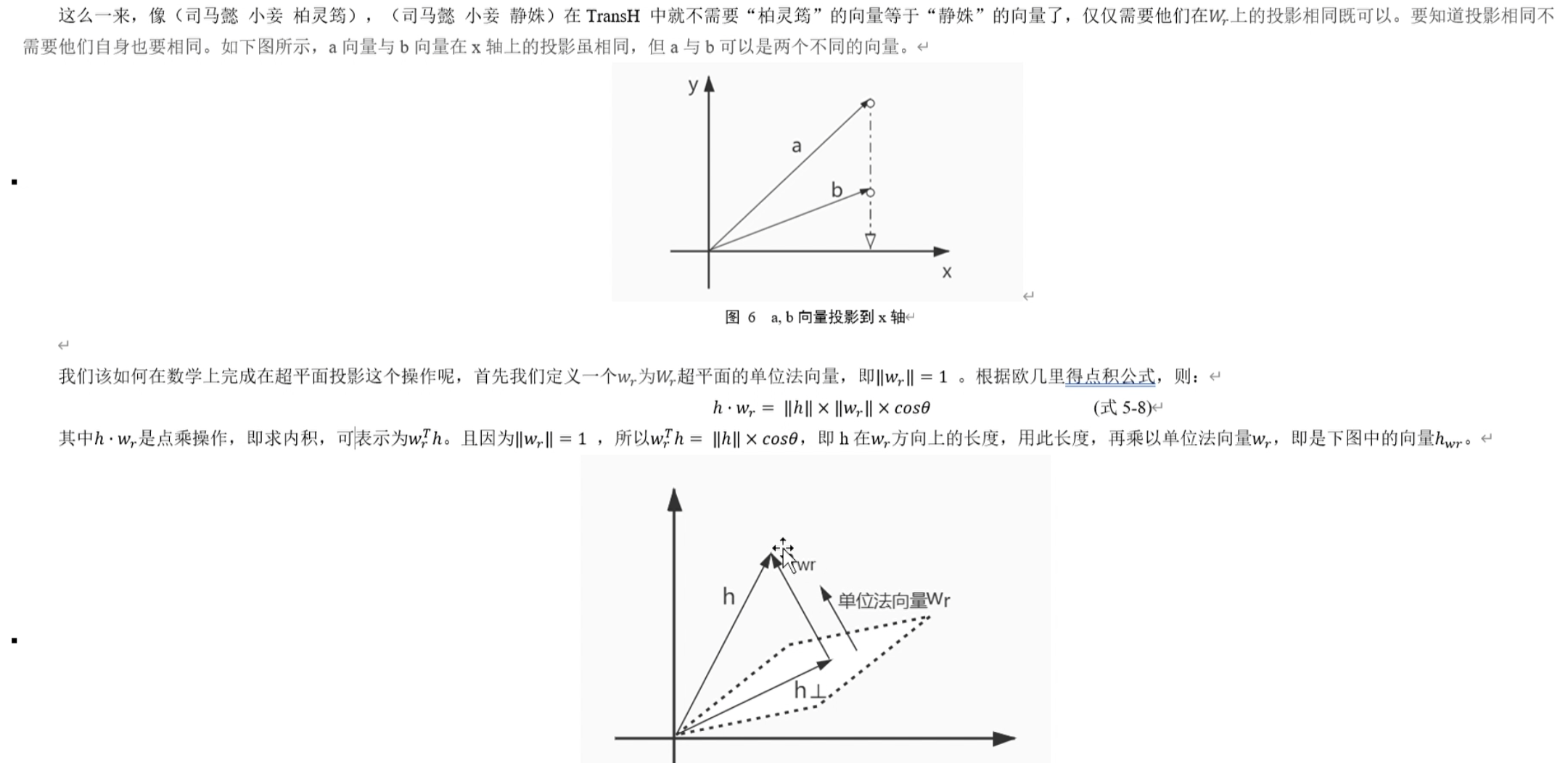
为什么TansE会在一对多等关系上效果不好,比如我们看两组关系,(司马懿小妾柏灵筠),(司马懿小妾静姝)。因为两组关系中都存在实体“司马懿”和关系“小妾”,那么如果只简单考虑h+r=t,那么“柏灵筠”=“司马懿+小妾”和“静姝”=“司马懿”+“小妾”,所以“柏灵筠”=“静姝”,很显然,这并不是我们想要的结果。
再比如自反关系,(曹接 欣赏 曹操),“曹操” + “欣赏” = 曹操,所以“欣赏” = 0。如果你非要说如果存在自反关系,relation就该为0,那么轮到计算(曹操 欣赏 司马懿)时,如果将“欣赏‘=0代入,则会产生“曹操”=“司马懿”的结果。当然TransE在实际迭代中也不会这样,原因是因为(曹操 欣赏 司马懿)这类的数据大概率会在训练集中占大多数,而(曹操 欣赏 曹操)会被它当作噪音数据一样的存在,所以会影响效果。
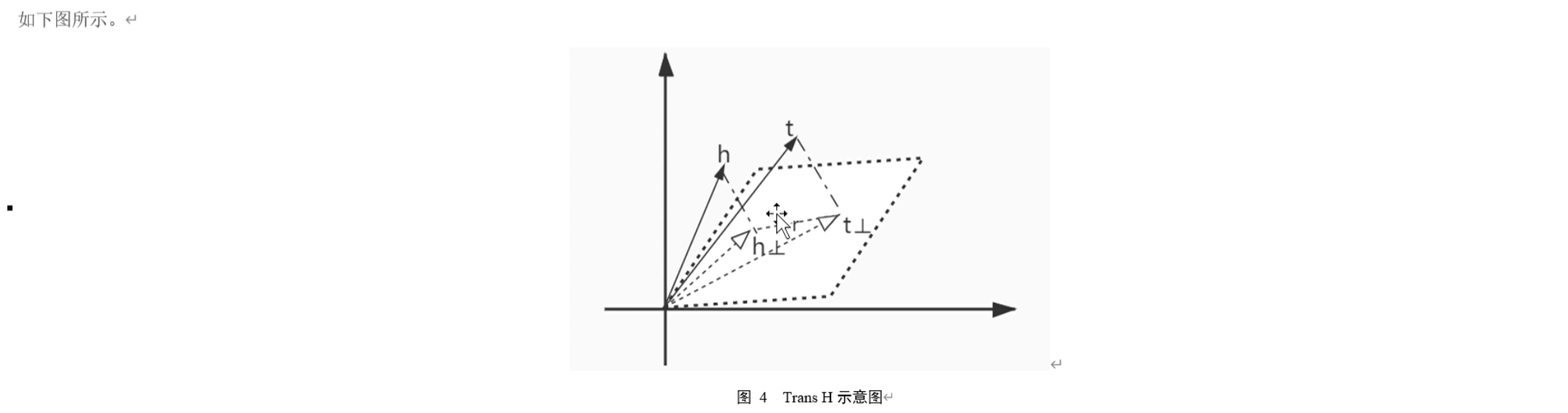
为了解决上述问题,2014年TransH模型被提出。中心思想就是对每个关系定义一个超平面Wr。而h1与t1,作为 h和t 在超平面上的投影,将h1与t1,代替h, t满足:
$$
||h_ {1} +r- t_ {1} ||_ {2} =0
$$
超平面与法向量
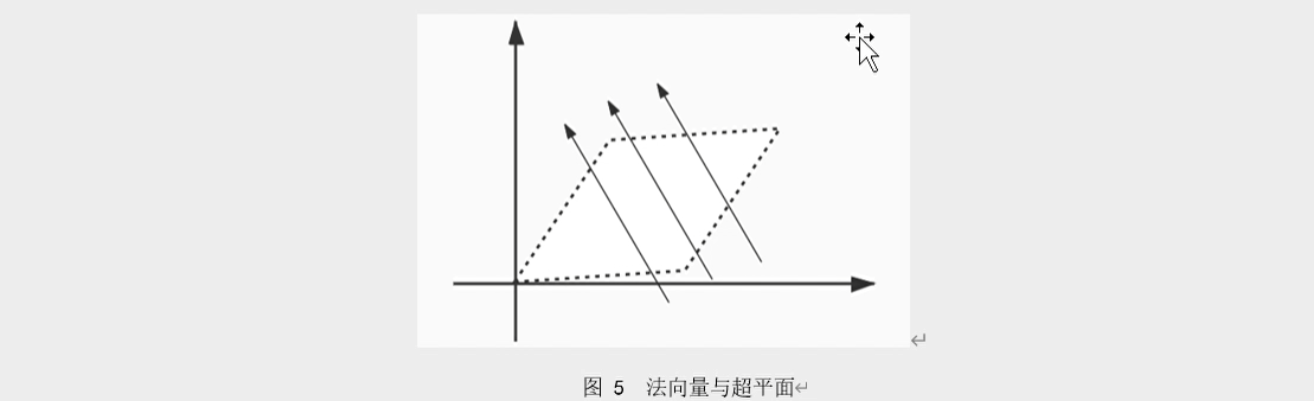
超平面就是指分割n维空间的维度为n—1维度的子空间。比如一个二维的平面可以把三维空间分成不可相交的两部分,那么一个三维的空间理论上可把四维的空间分为两部分,所以我们干脆就可以把负责分割空间的这个子空间统称为“超平面”,“平面”可视作“二维超平面”,线可视作为“一维超平面”。
法向量就是正交于超平面的向量,通俗点说就是垂直,如下图所示,所以一个超平面可对应无数个法向量。如果法向量的L2范数等于1,则称为单位法向量。

TransH
投影到超平面,与TransE唯一的差别就是做了向量的映射,具体的映射方法就是用一个矩阵,这里我觉得类似于RNN的线性变换层,就用这一个k * k 维的矩阵,先用该矩阵Wr的转置乘以原本的h,t,再用h,t与Wr相乘,最后用h-该数,完成转换。本质上公式的样貌和TransE别无二致,只不过利用变换将其映射到别的维度
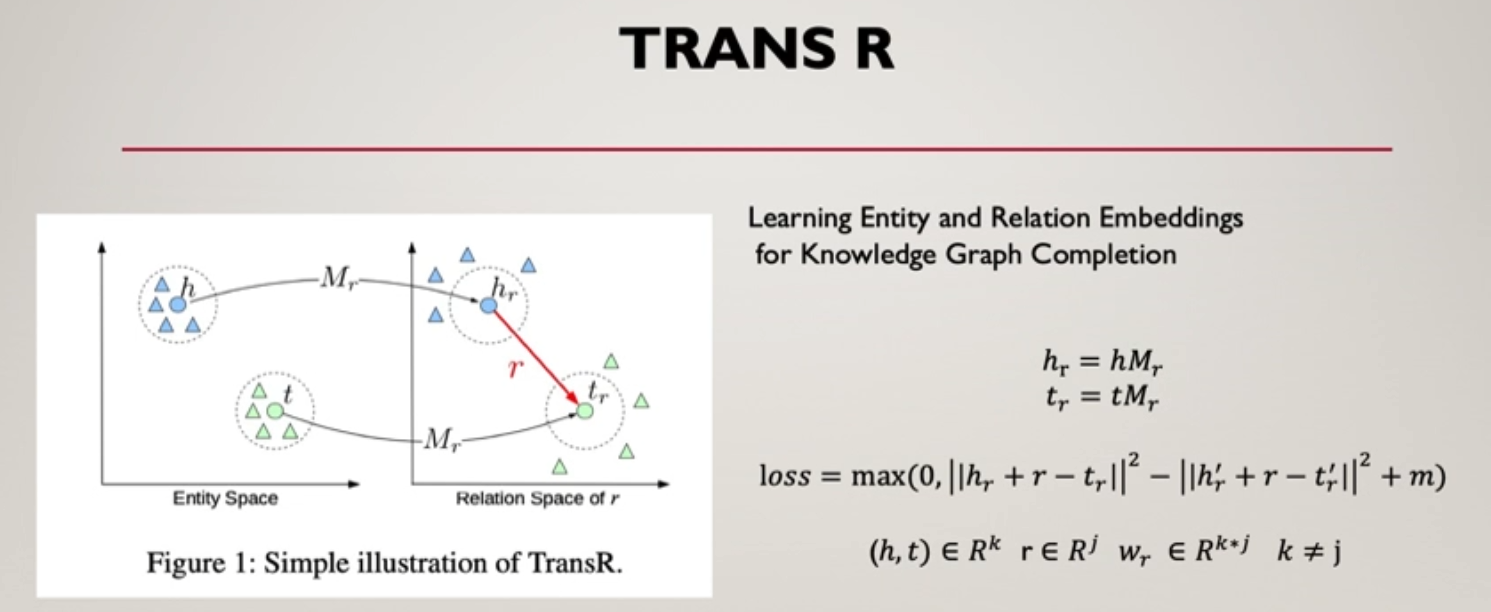
TransR
R的含义是relation space
本质上就是原来的h,t同时乘上一个相同居住,也是替换,反正就是绷不住了,感觉都很简单
CKE简要原理

CKE不能称作一个算法,算是一种思想

传统的LFM(线性调频)就是我们以前常用的模型。
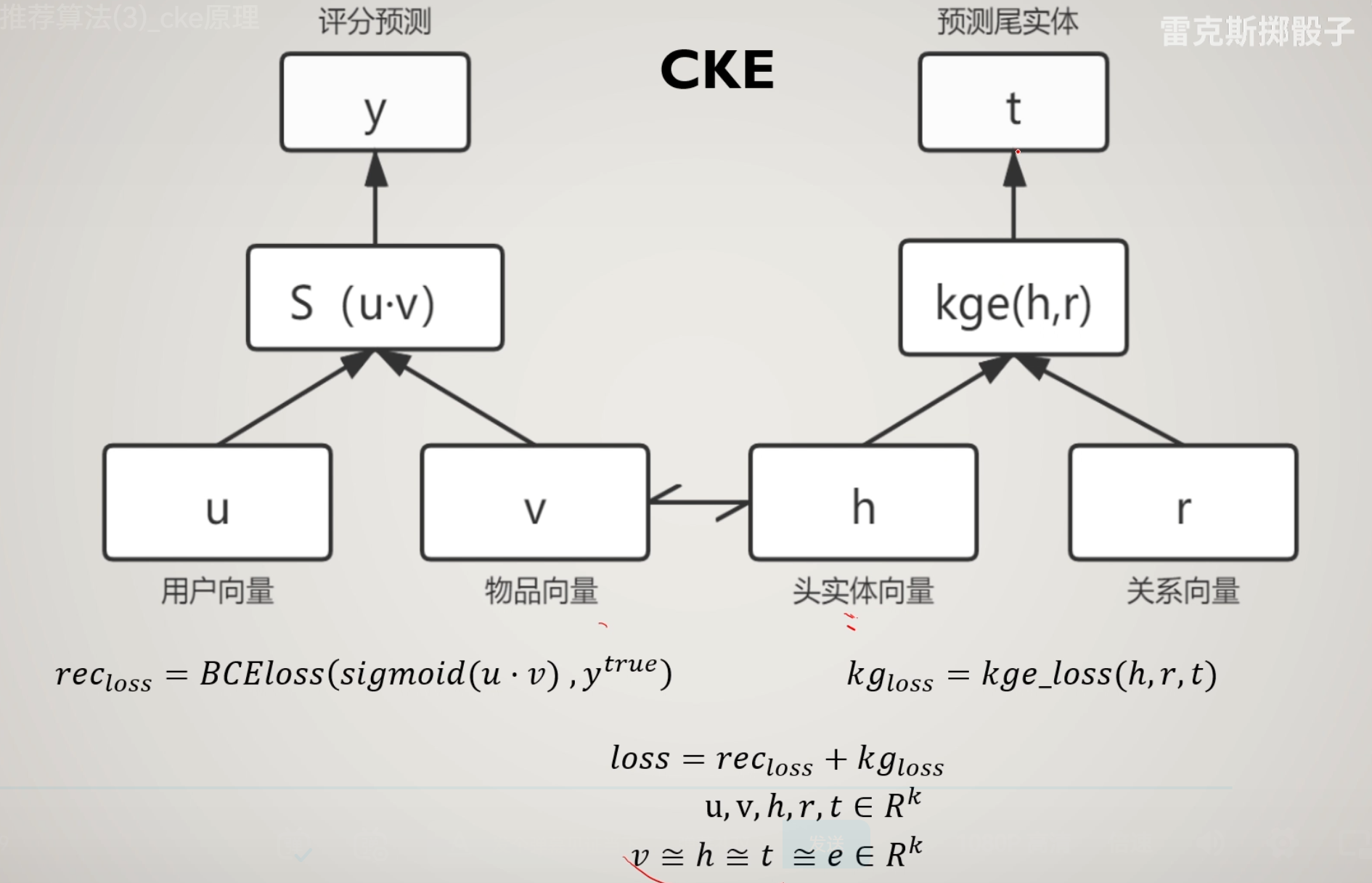
物品向量,头实体向量,尾实体向量是等价的概念,但是并不是说是相同的东西,意思只是可以在每一批次时,两边一起迭代,同时训练。甚至可以加一些隐层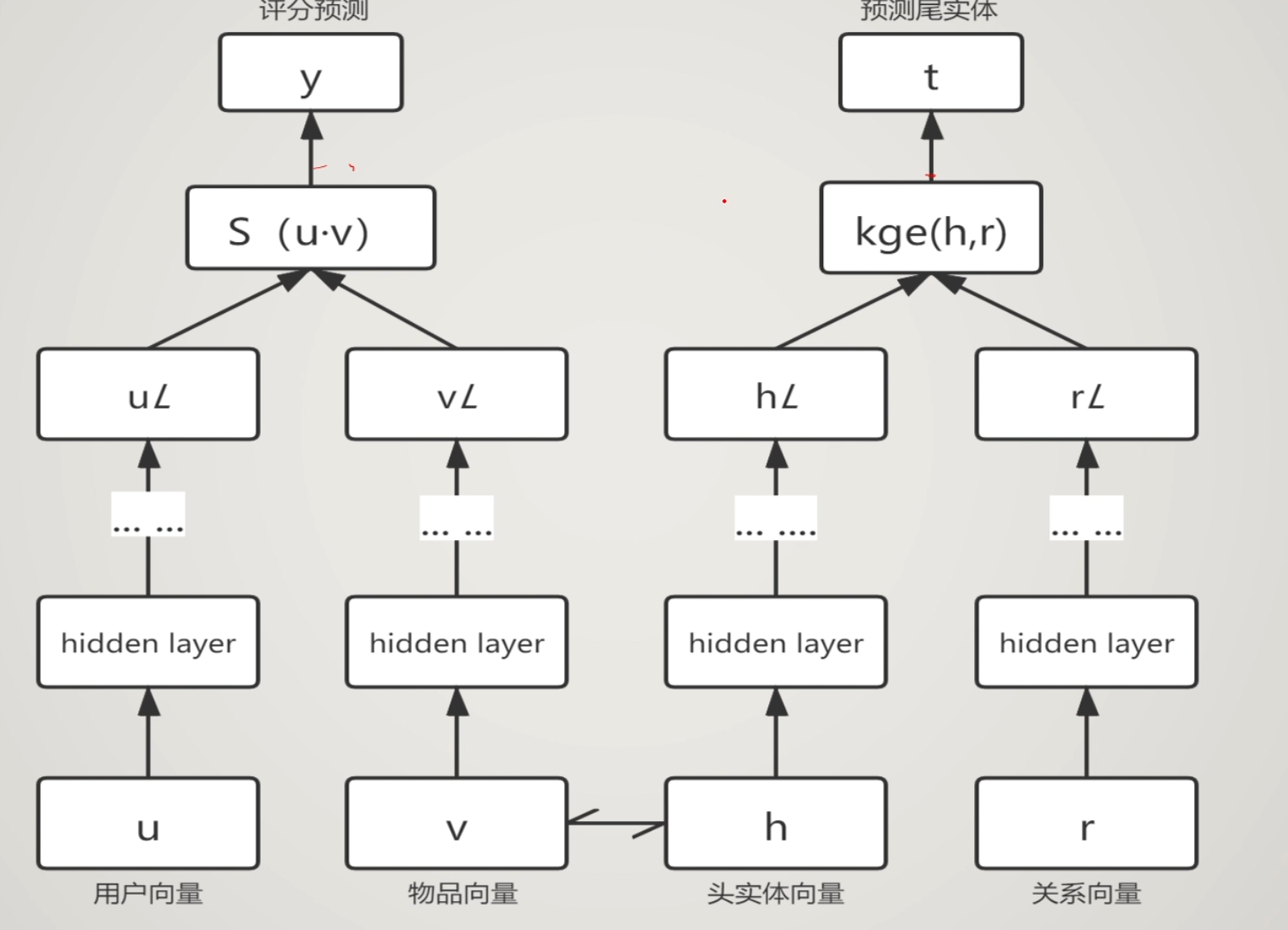
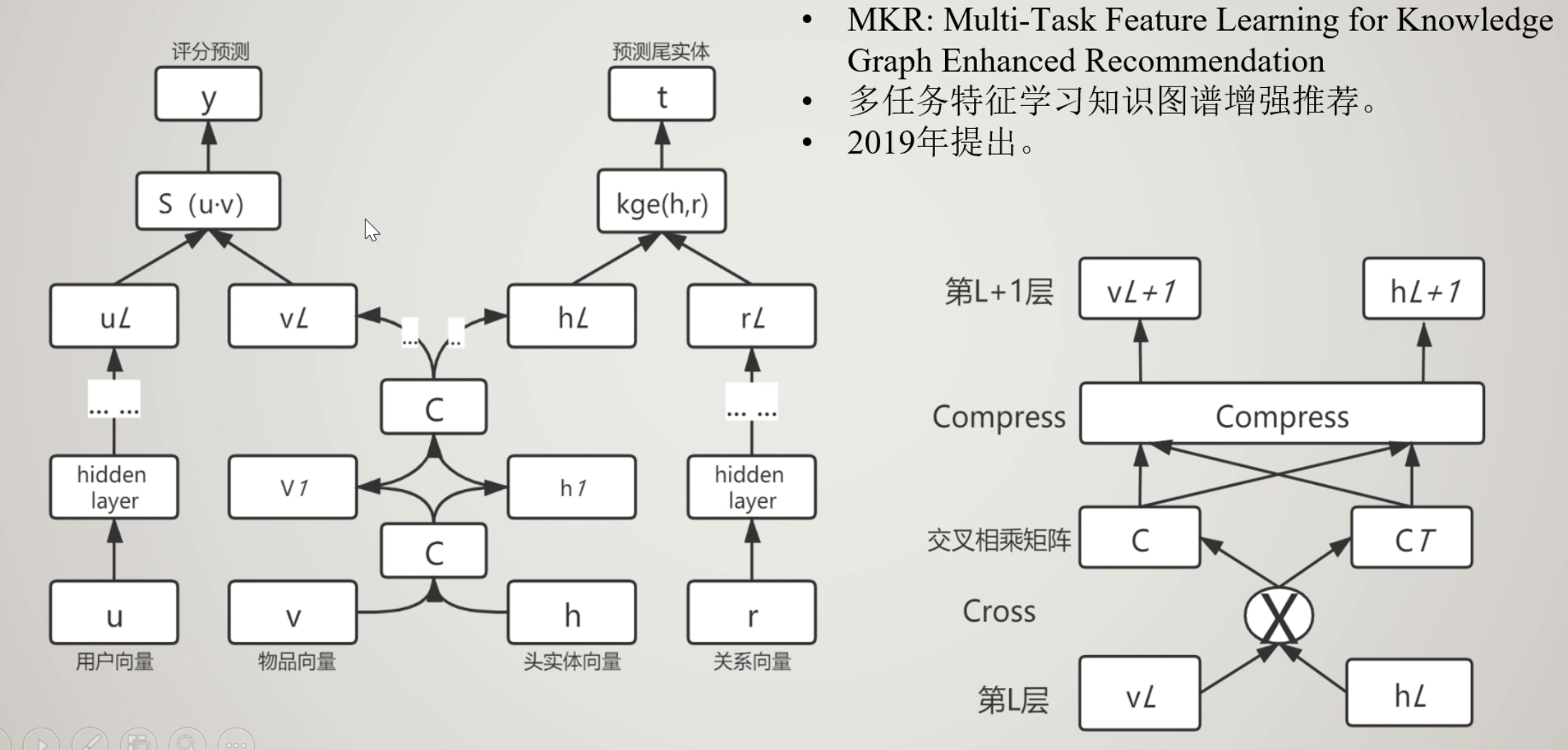
MKR
在CKE基础上,加入MKR C单元


点积相似度

 微信
微信 支付宝
支付宝

