
PPDE指导计划
提交代码贡献
代码贡献流程-使用文档-PaddlePaddle深度学习平台
注意push得用手机热点
网不好,指令:
open ssl: git config –global http.sslVerify “false”
//取消http代理 git config –global –unset http.proxy
//取消https代理 git config –global –unset https.proxy
飞桨平台学习
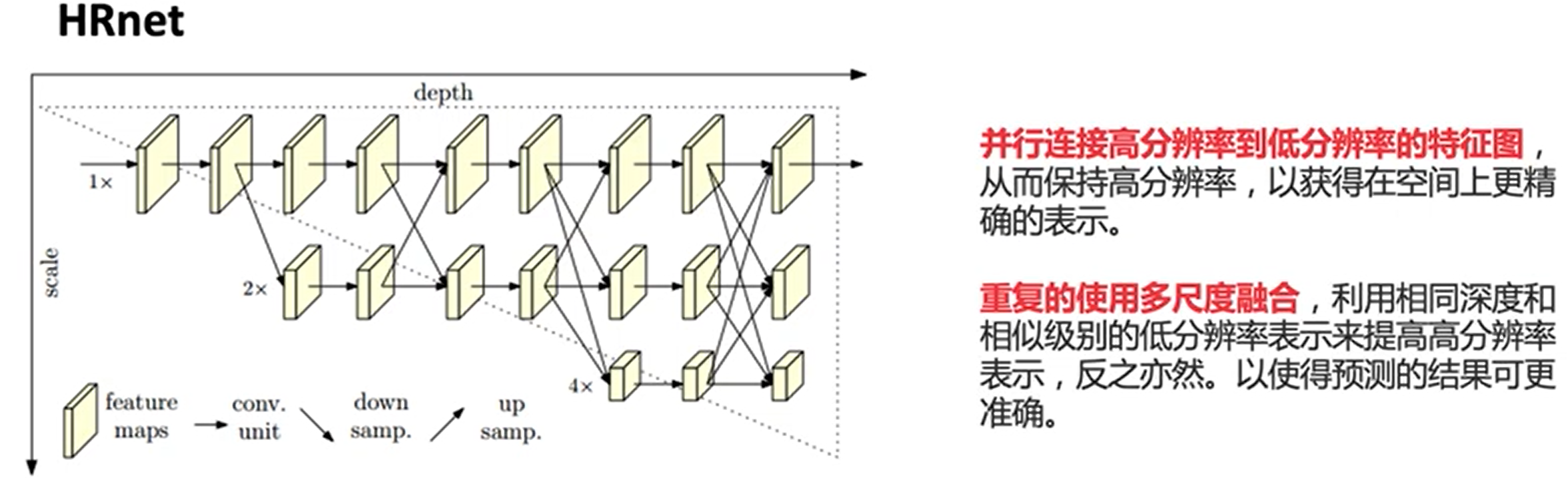
飞桨框架图

图像分割
什么是图像分割


PaddleSeg
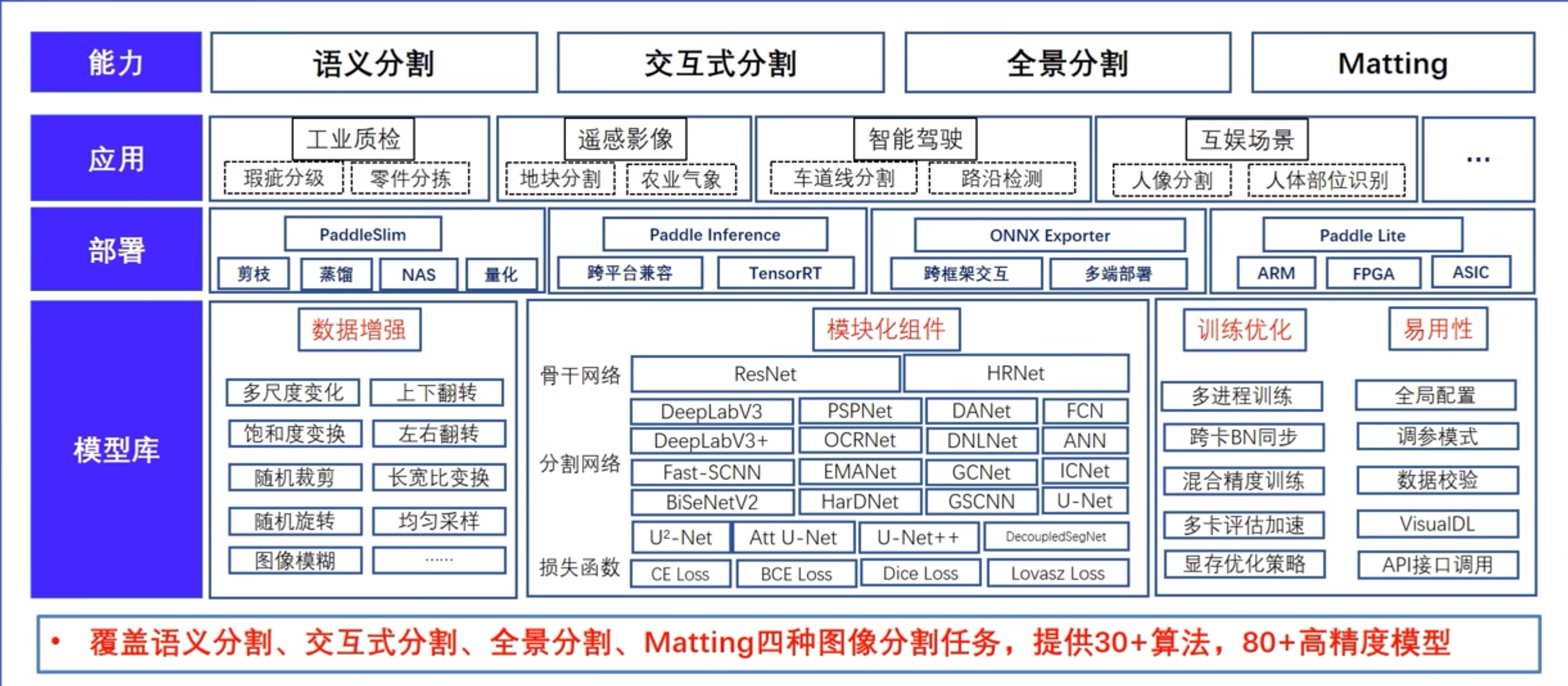
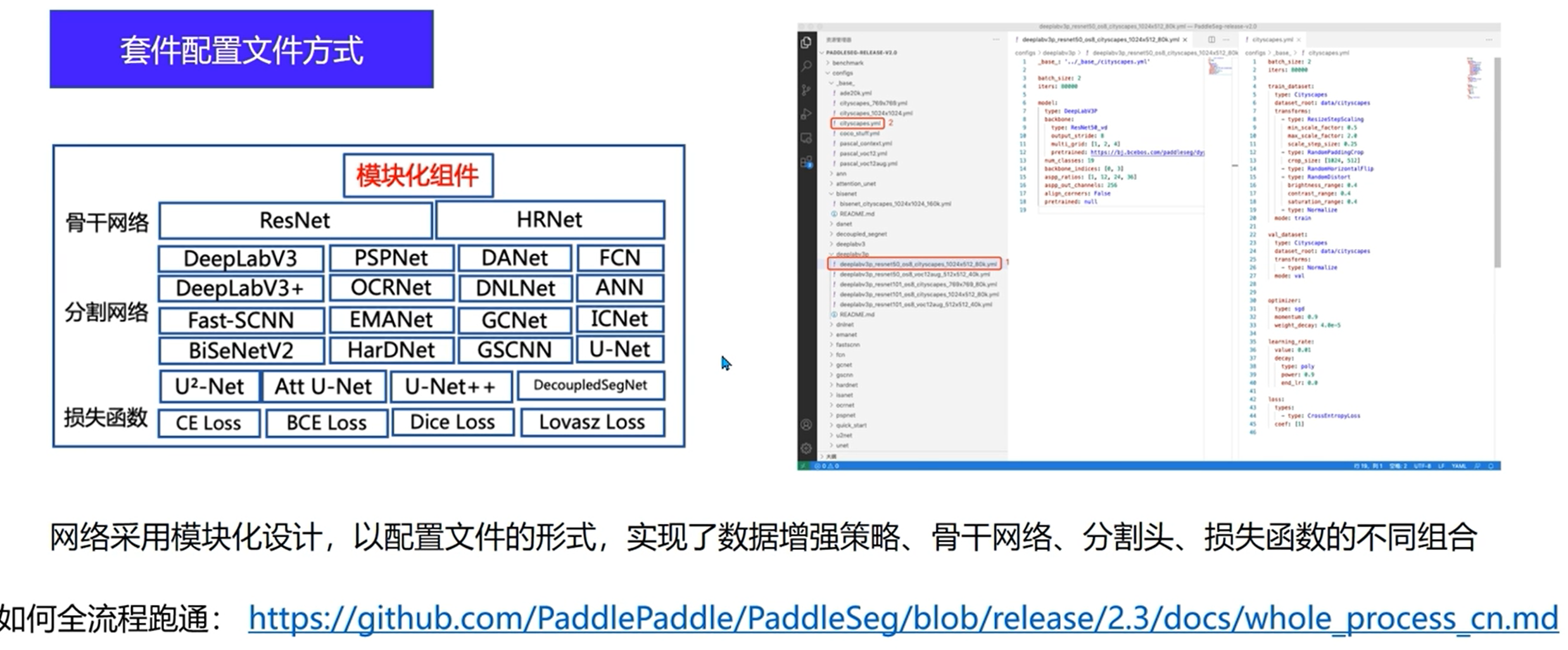
实现方式
更适合新手,直接调参即可
更佳灵活

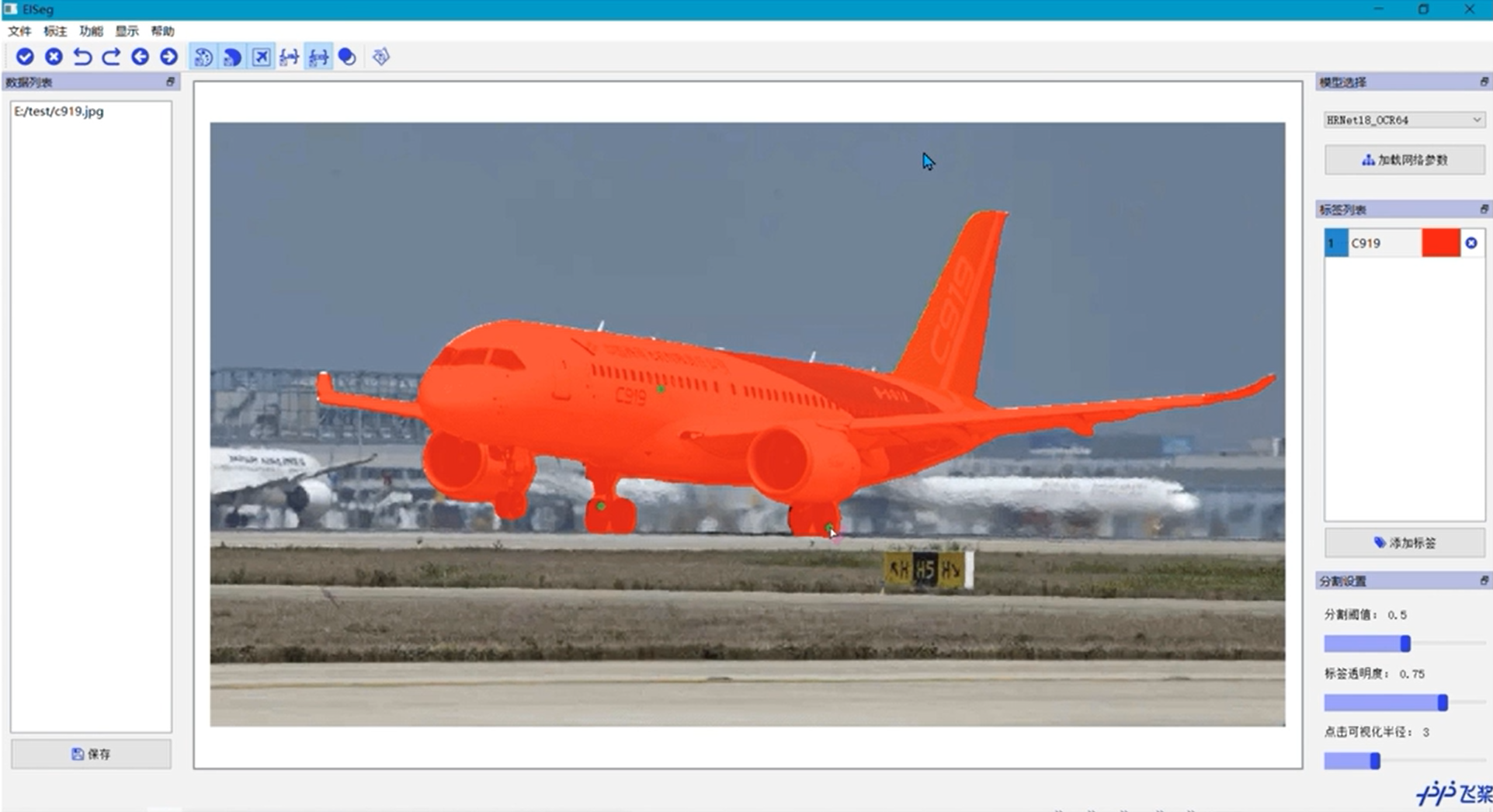
交互式数据分割EISeg
数据分割工具,现阶段大部分任务是数据驱动的。EISeg是交互式分隔工具,用户只需要画个框框,画个圈啥的,系统自动给我们算几个数据点把我们选中的数据提取出来


工具页面展示
抠图算法Matting
不止要求透明度,还要求分类


摇感
什么是摇感
从天空俯瞰世界!

摇感图像分割

实战
数据
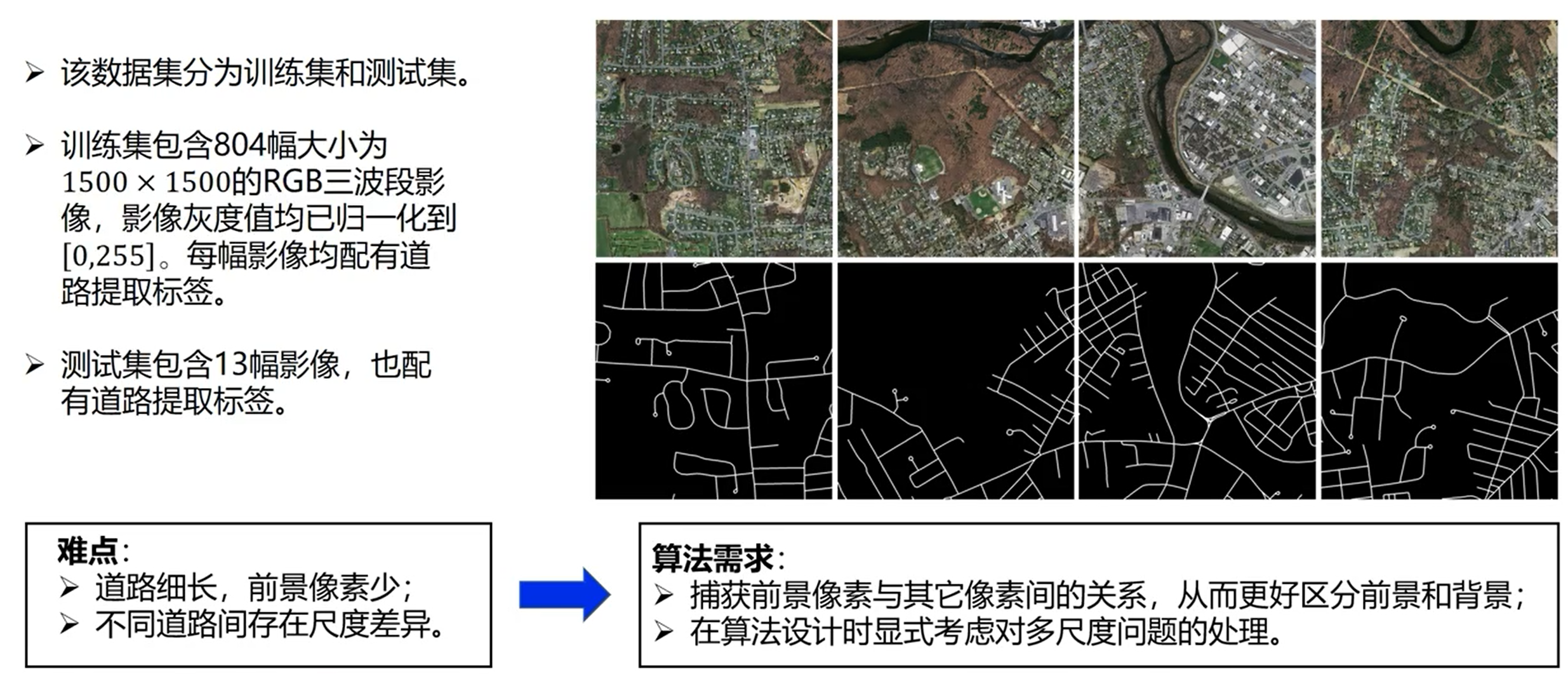
模型
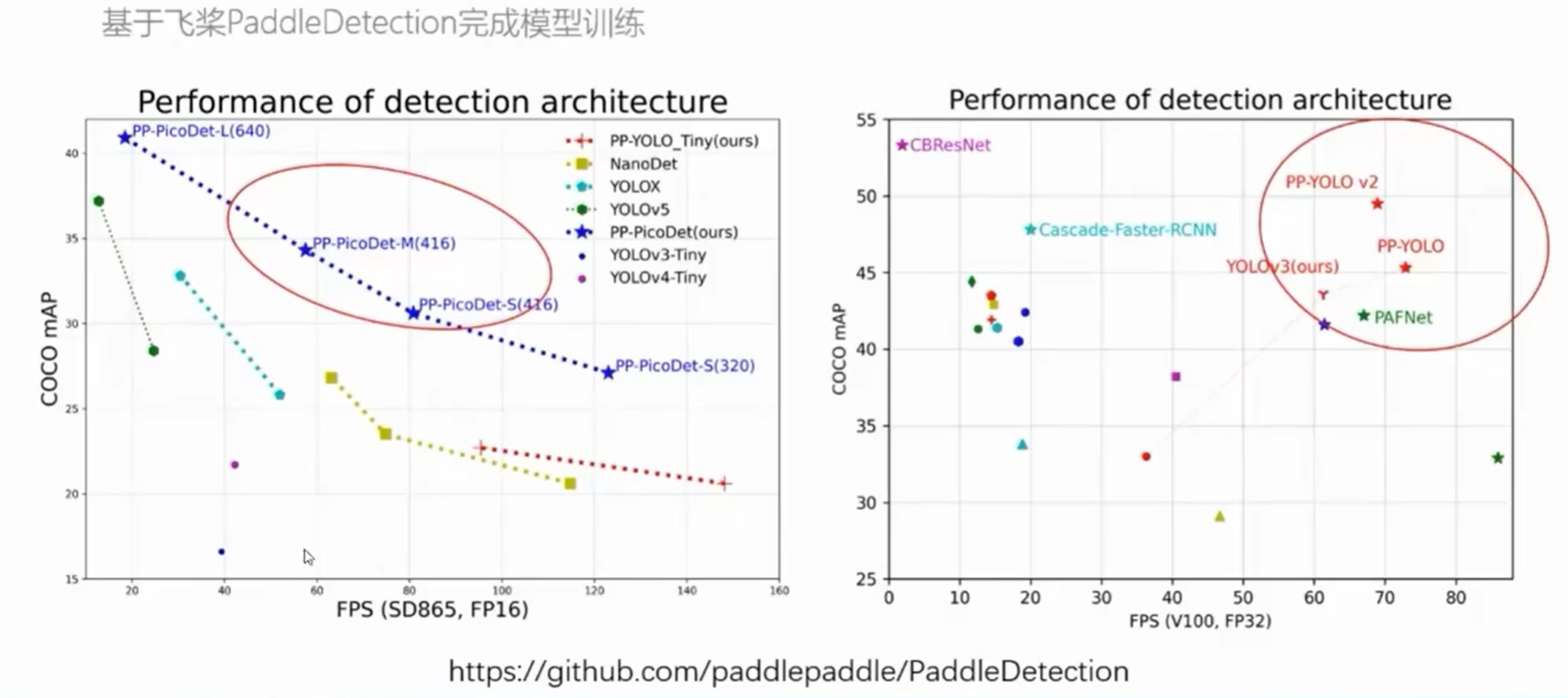
实战环节采用成熟的模型,DeepLab系列
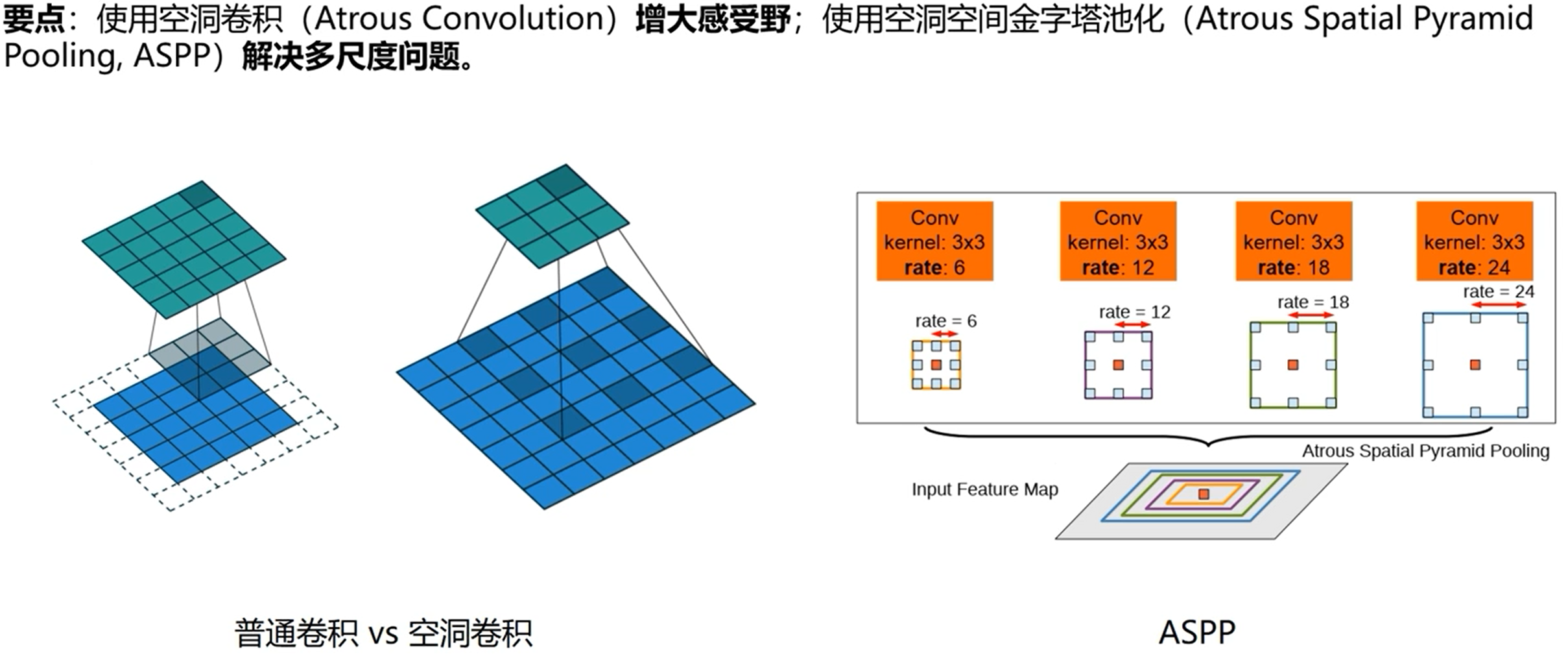
代码
!代表你将在notebook执行shell指令,如果不想看到下面克隆这些提示信息,可以直接用 > (/dev/null)或(2>&1)将输出信息定位到一个空的文件夹里,这个应用了shell 的重定位功能(redirect)
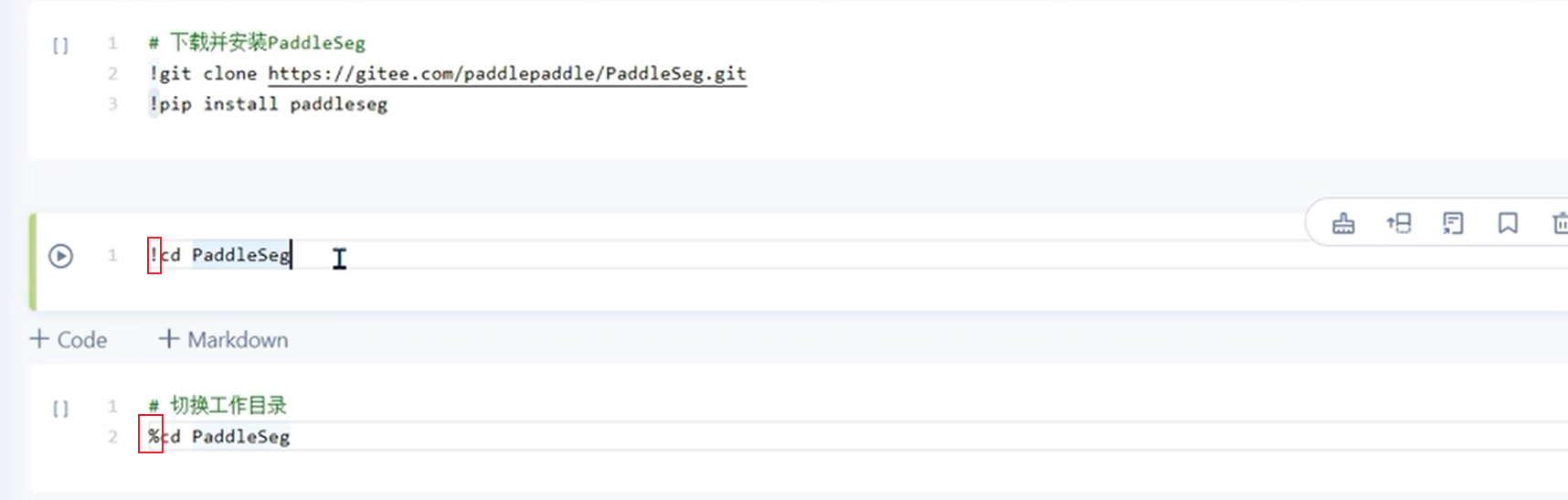
因为notebook会新开一个进程,你直接用!cd那么就是在shell终端进行操作,并不会作用在当前工作目录,因此用%cd(一个魔法指令)会更好。
这里-oq中,o代表这下一次你重复执行指令会覆盖这一次的,q(quiet)代表不输出内容,和前面重定向一个意思; -d代表你解压到那个目录(direct)

这里py是运行脚本,所以也不是直接在notebook运行,而是在shell

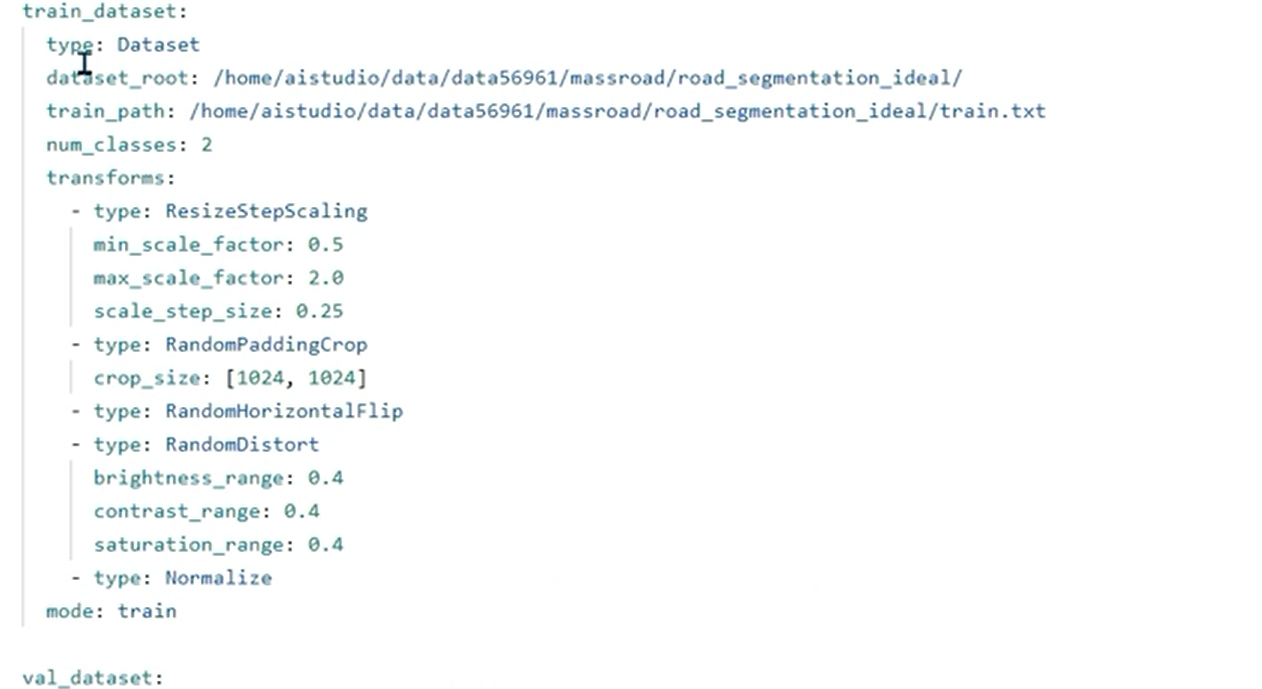
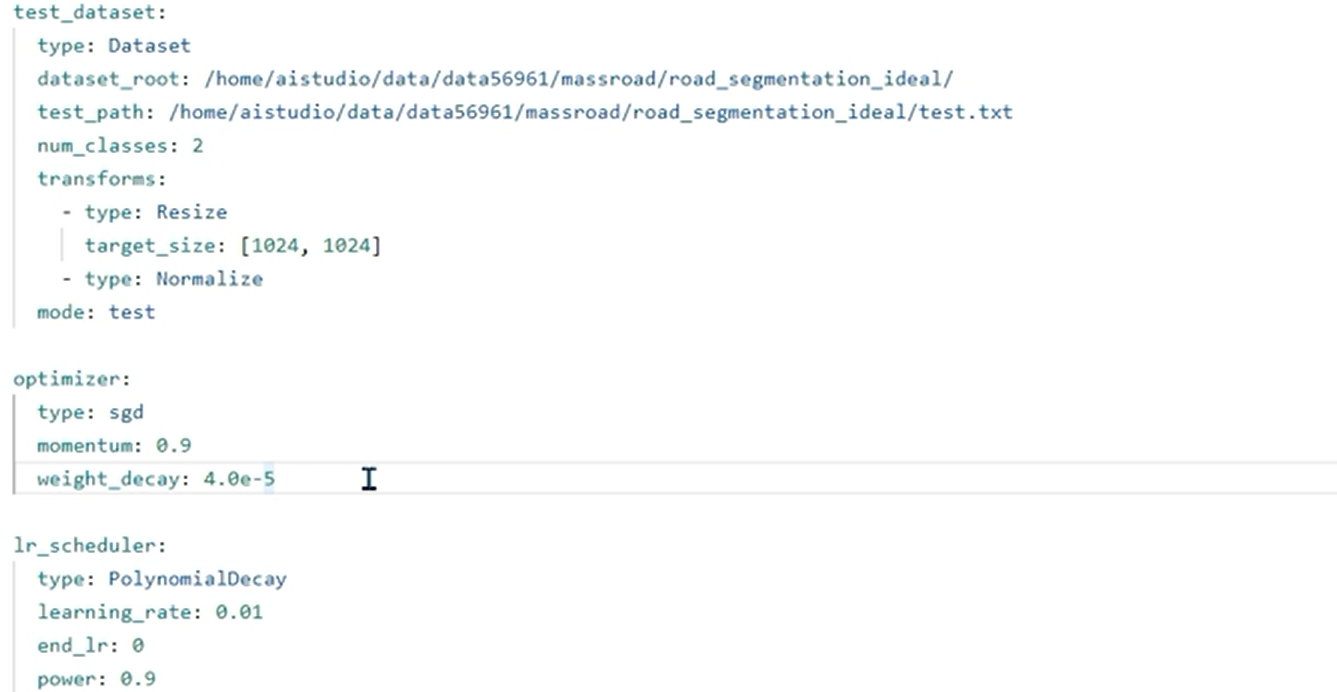
yml,简单的标记语言,帮助我们的算法进行一些配置
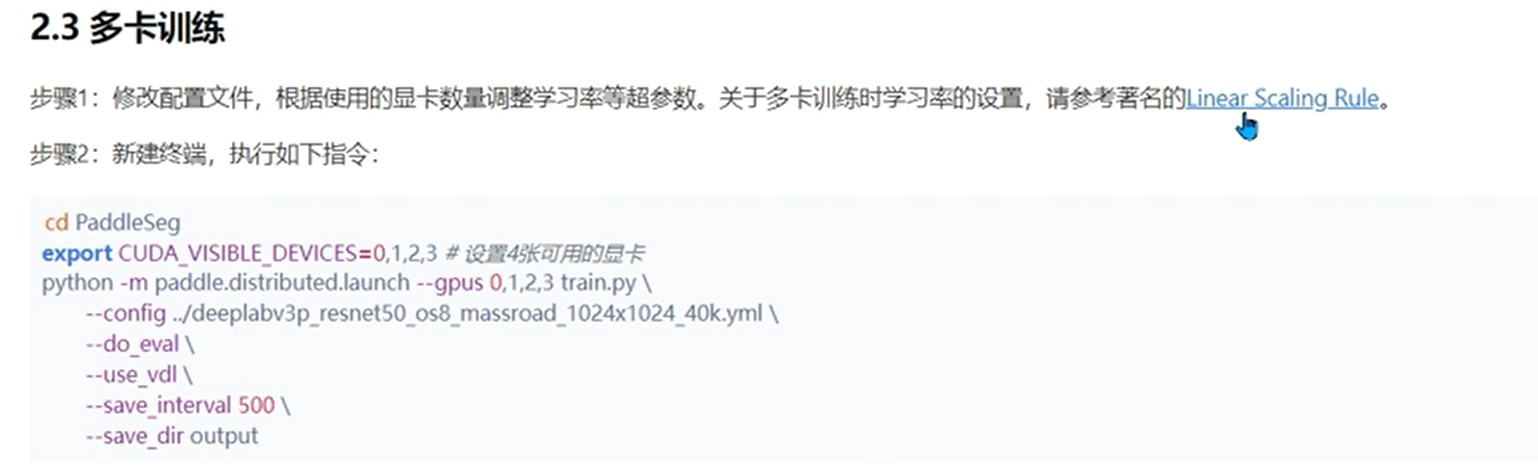
打开yml
一些参数介绍:
1 | batch_size: 设置越大模型收敛越快,不一定收敛到一个比较好的点,设置的越小,训练的过程中可能震荡的比较厉害,也不一定收敛的比刚才更差,要结合数据进行调整 |
train.txt
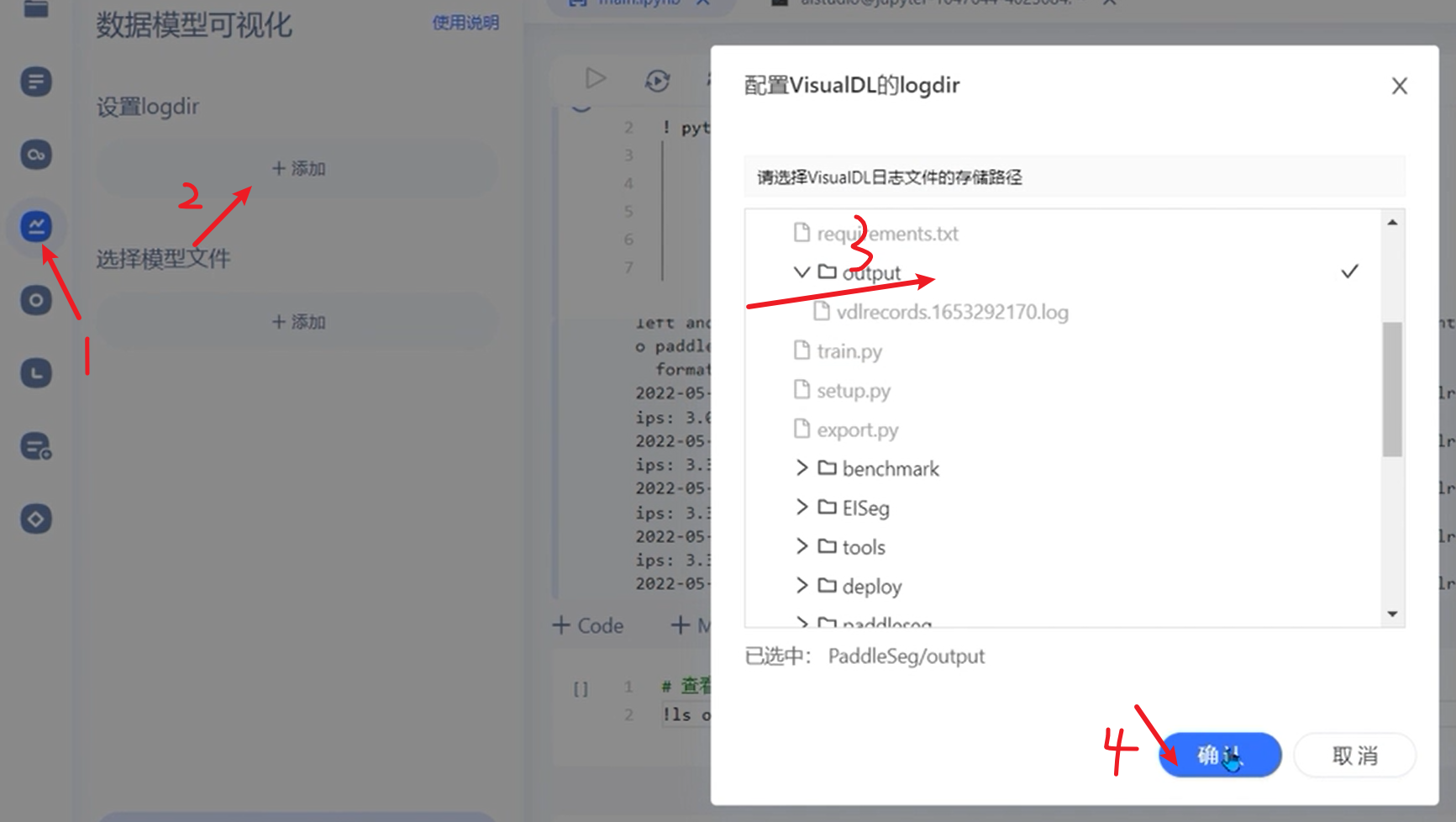
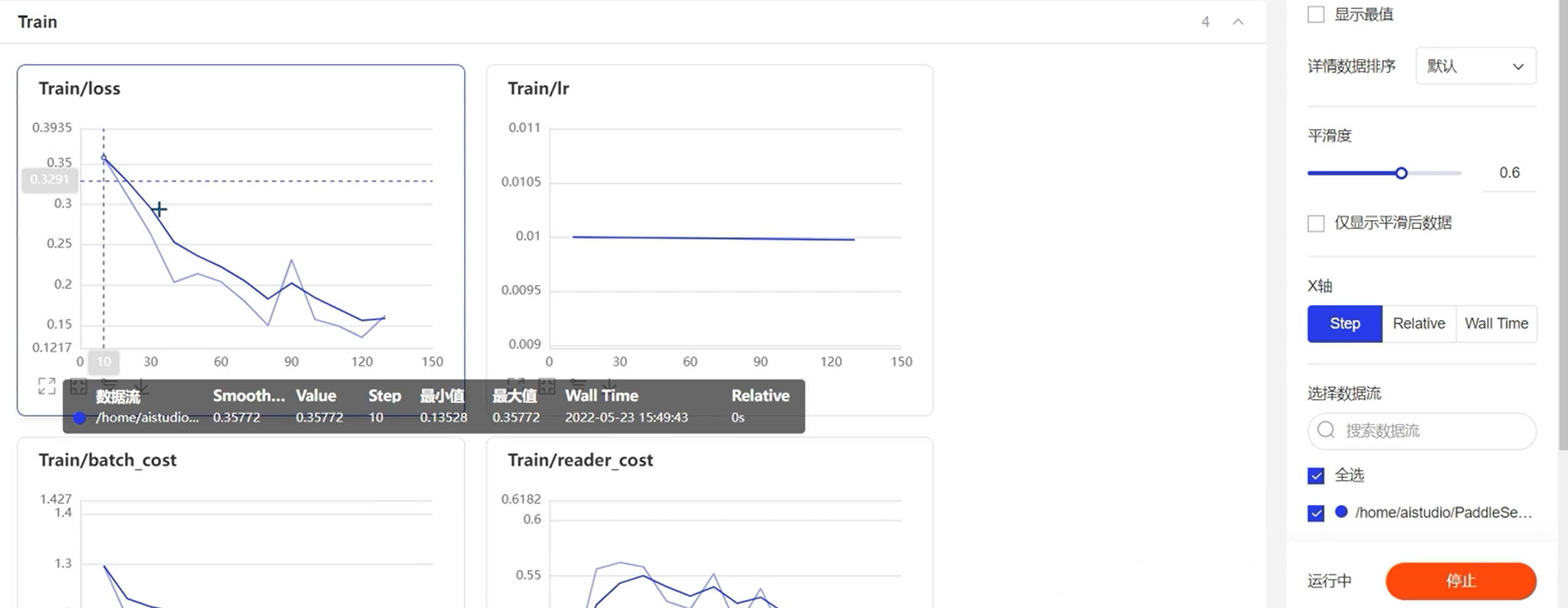
可视化方案
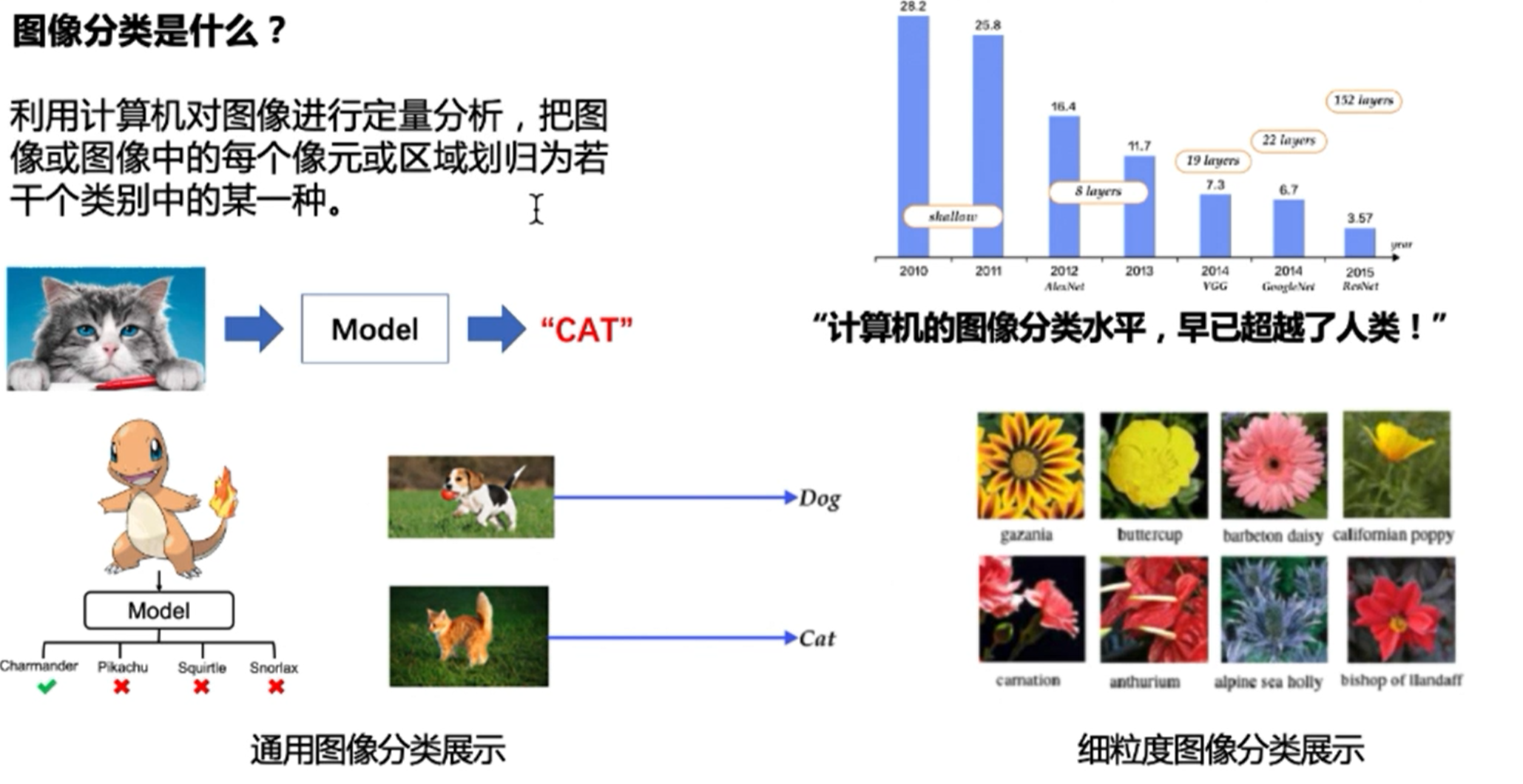
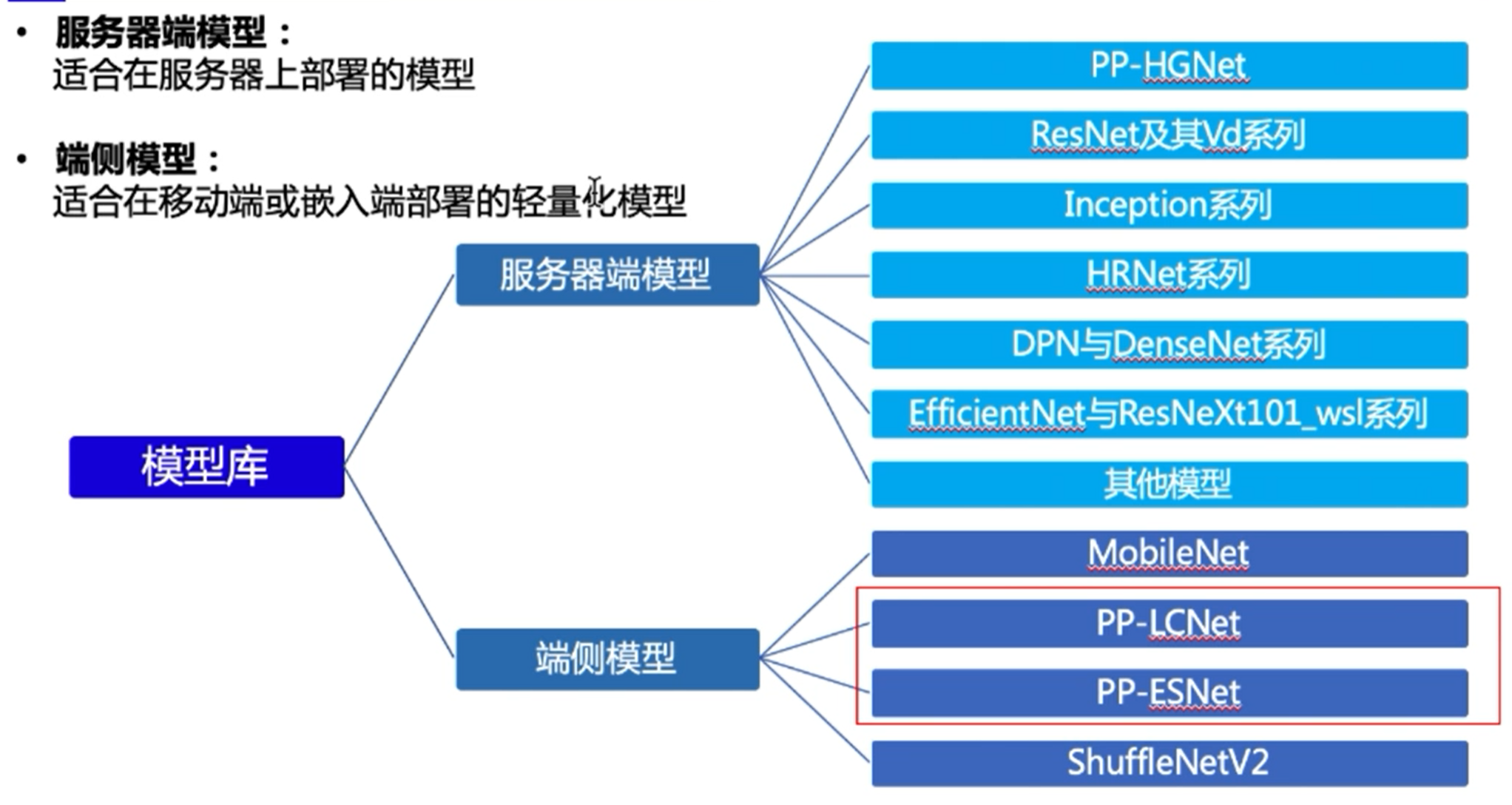
图像分类
PaddleClas


为何要构建Baseline


数据处理方式
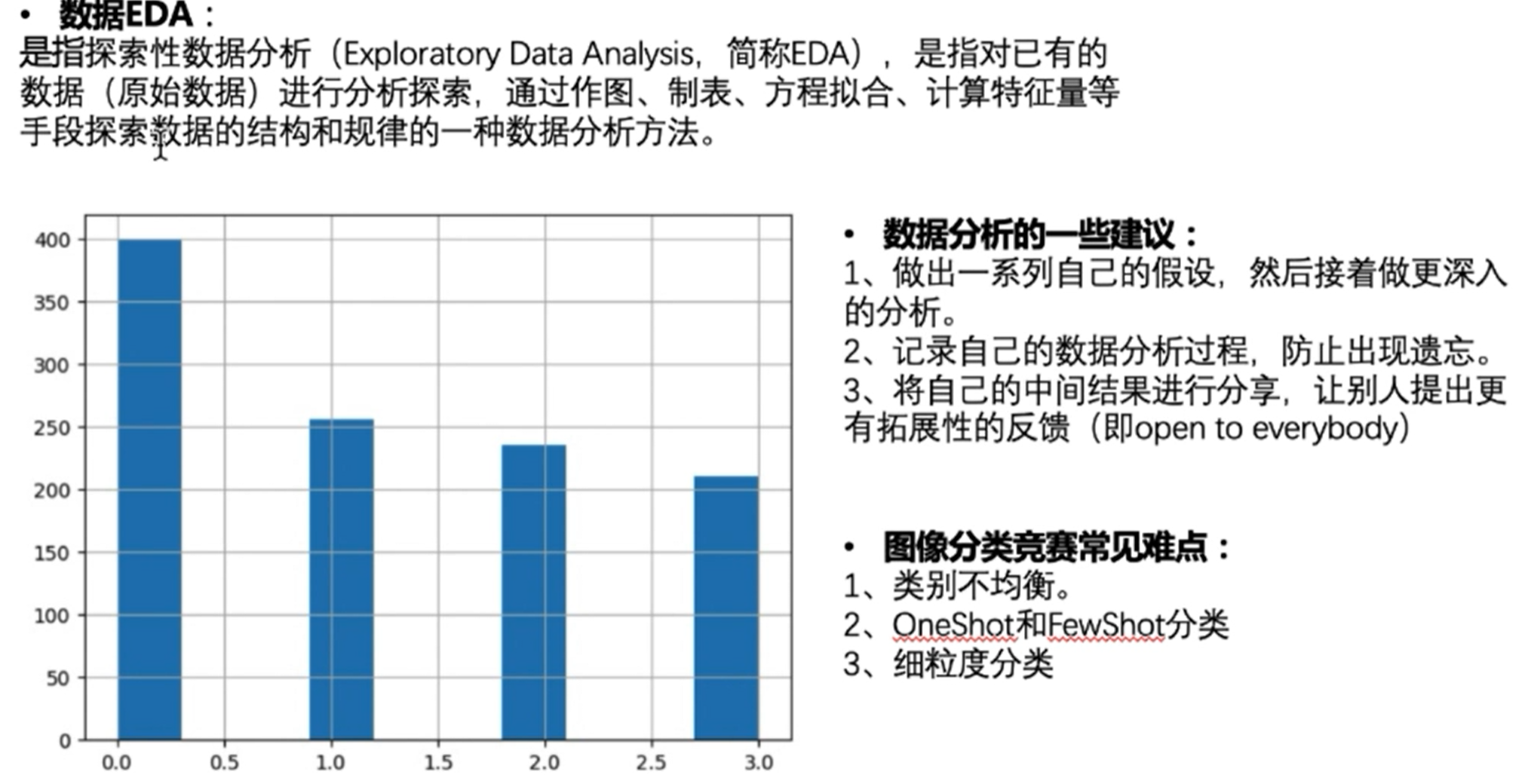
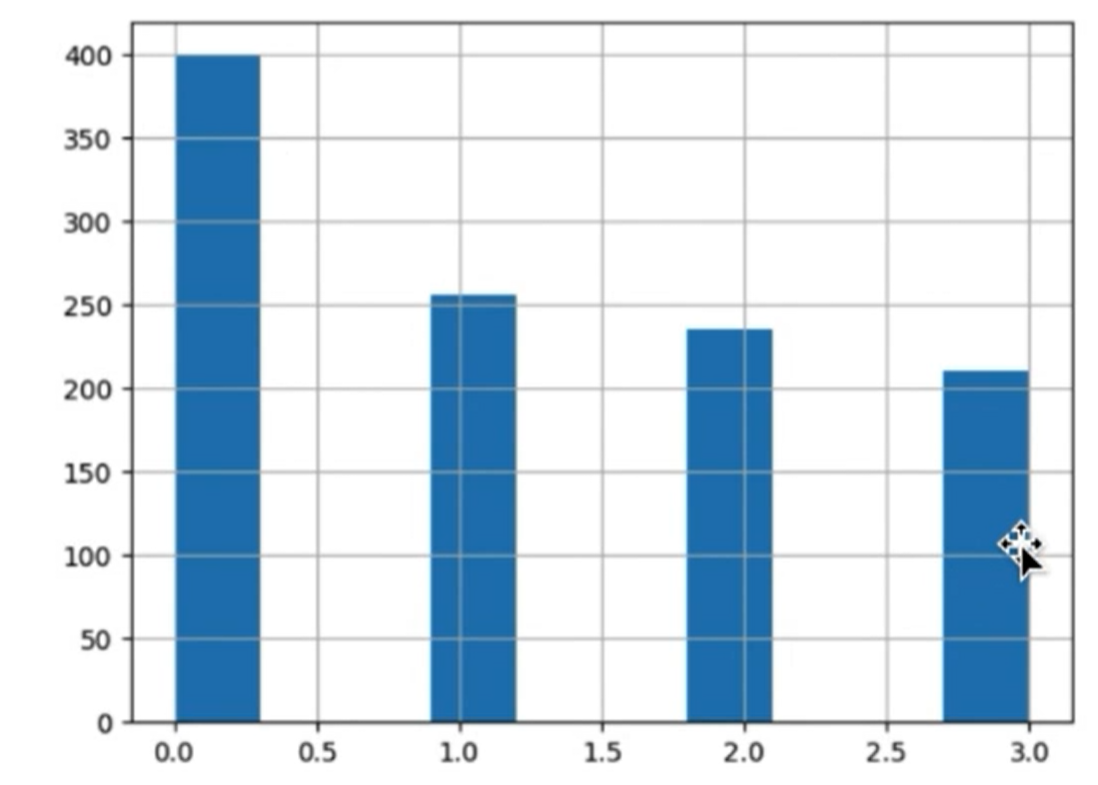
1、过采样
也就是把样本重复添加进训练集,例如这里最高的类别有400个样本,那么就把剩下三个类别,用已有样本重复投入训练的方式扩容到数据集里,凑成1600个样本
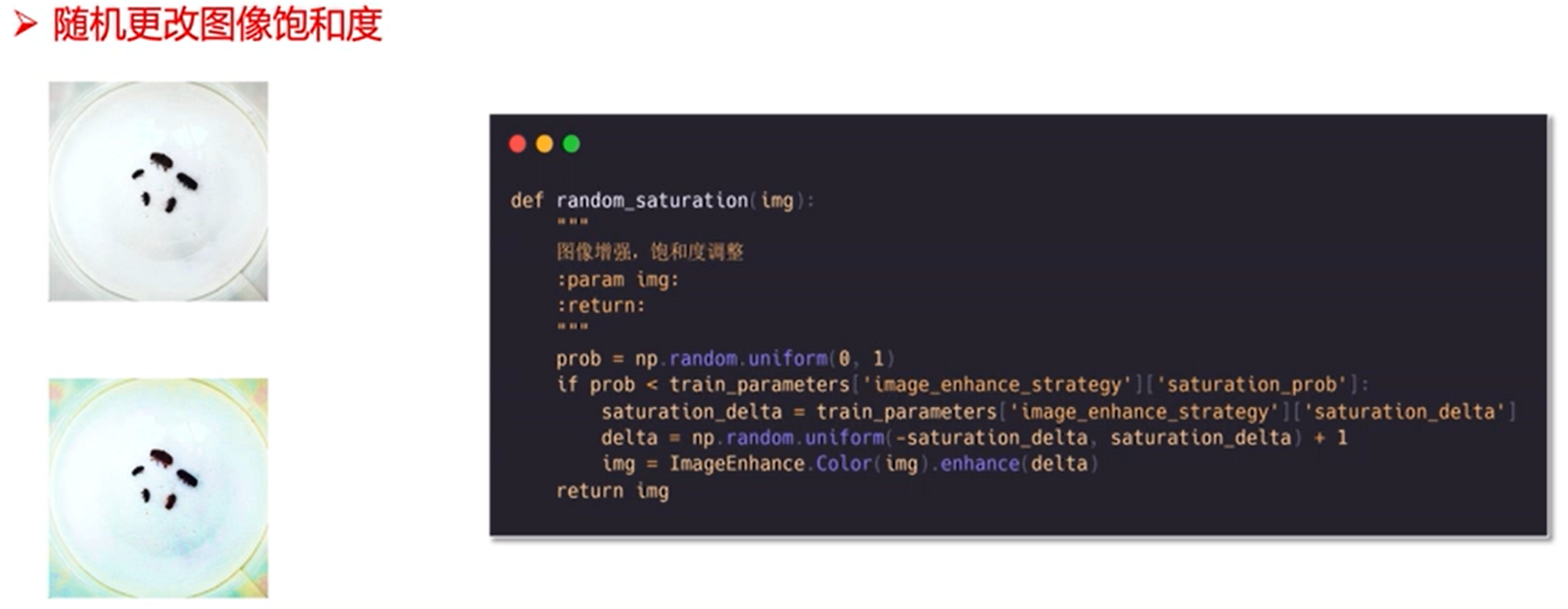
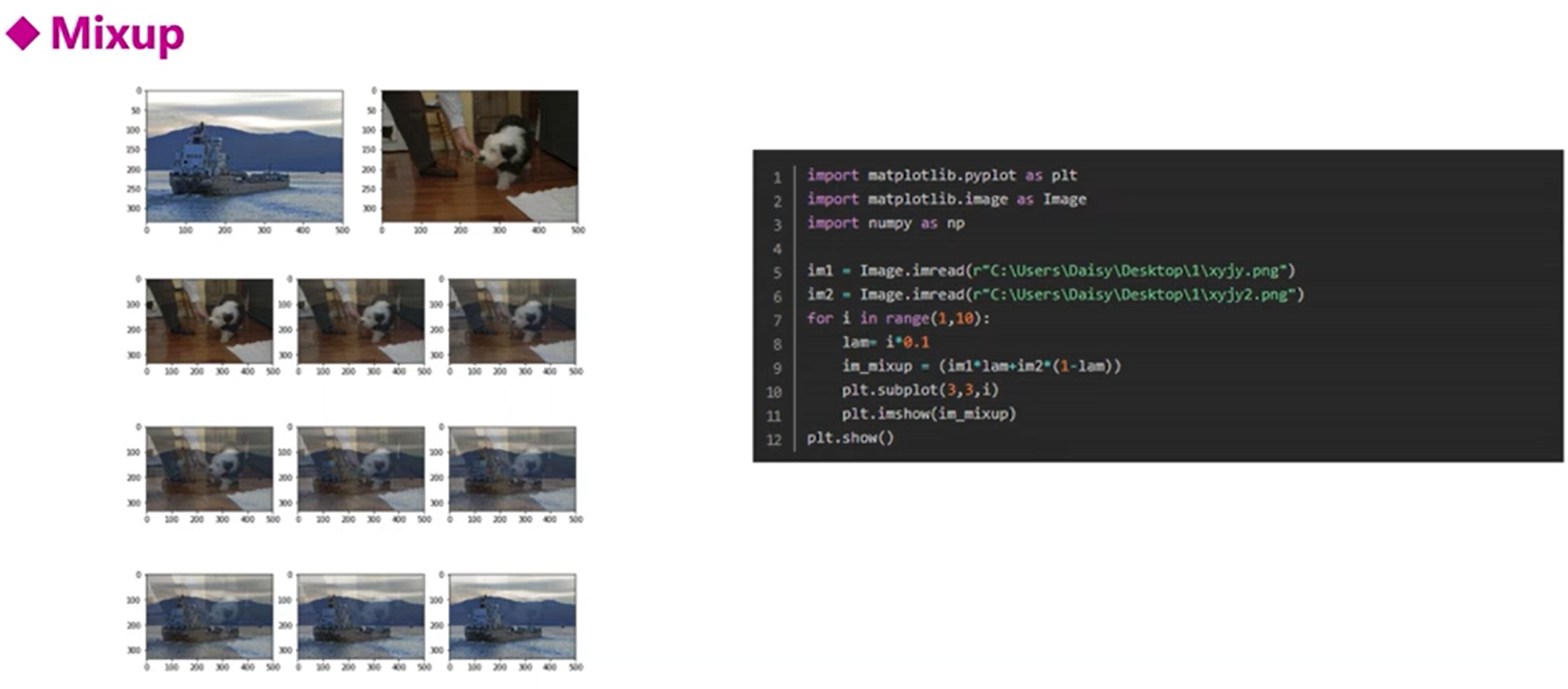
2、数据扩增
就是加大数据集,增强泛化能力
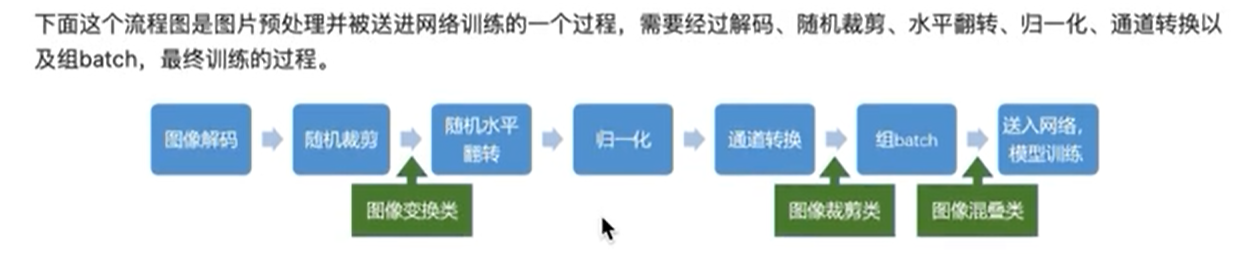
图像增广流程




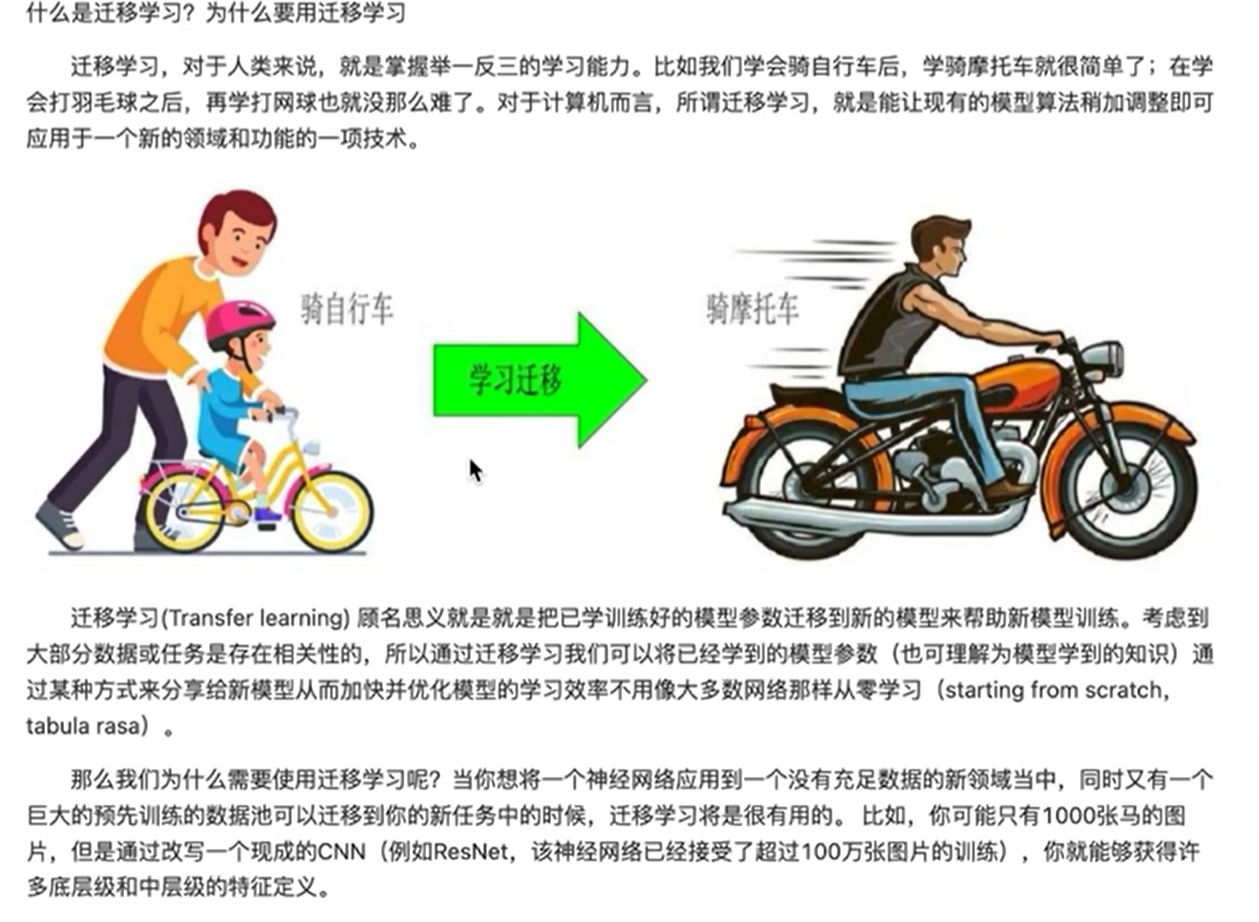
迁移学习
标签平滑


建议


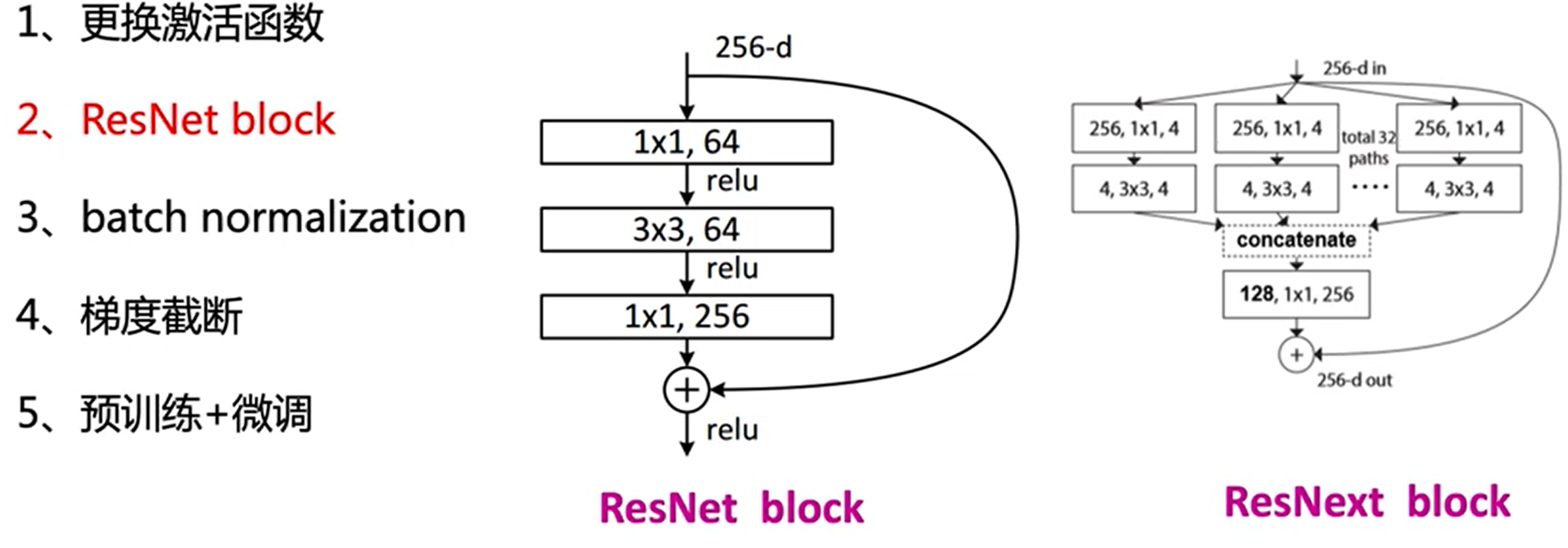
模型改进

深度、宽度与分辨率
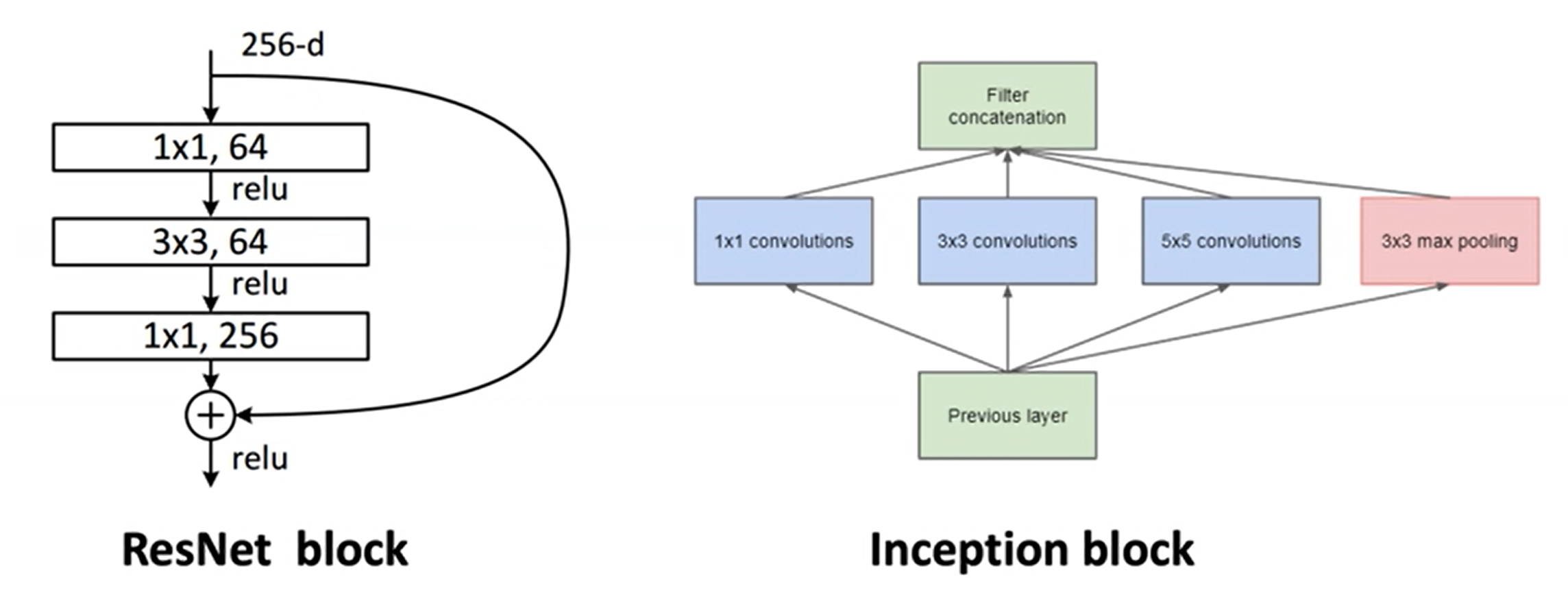
调优方法

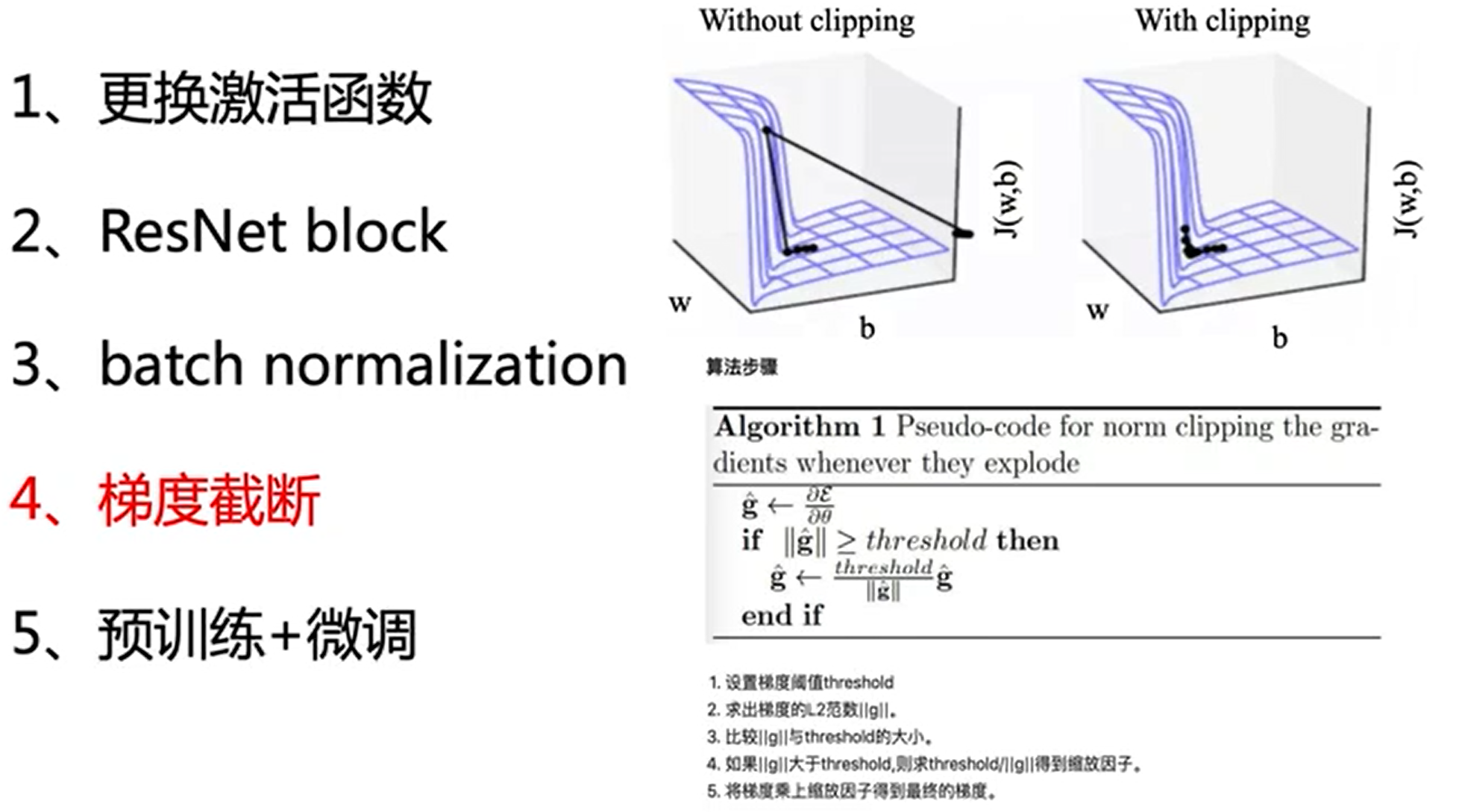
防止梯度消失与爆炸


过拟合问题
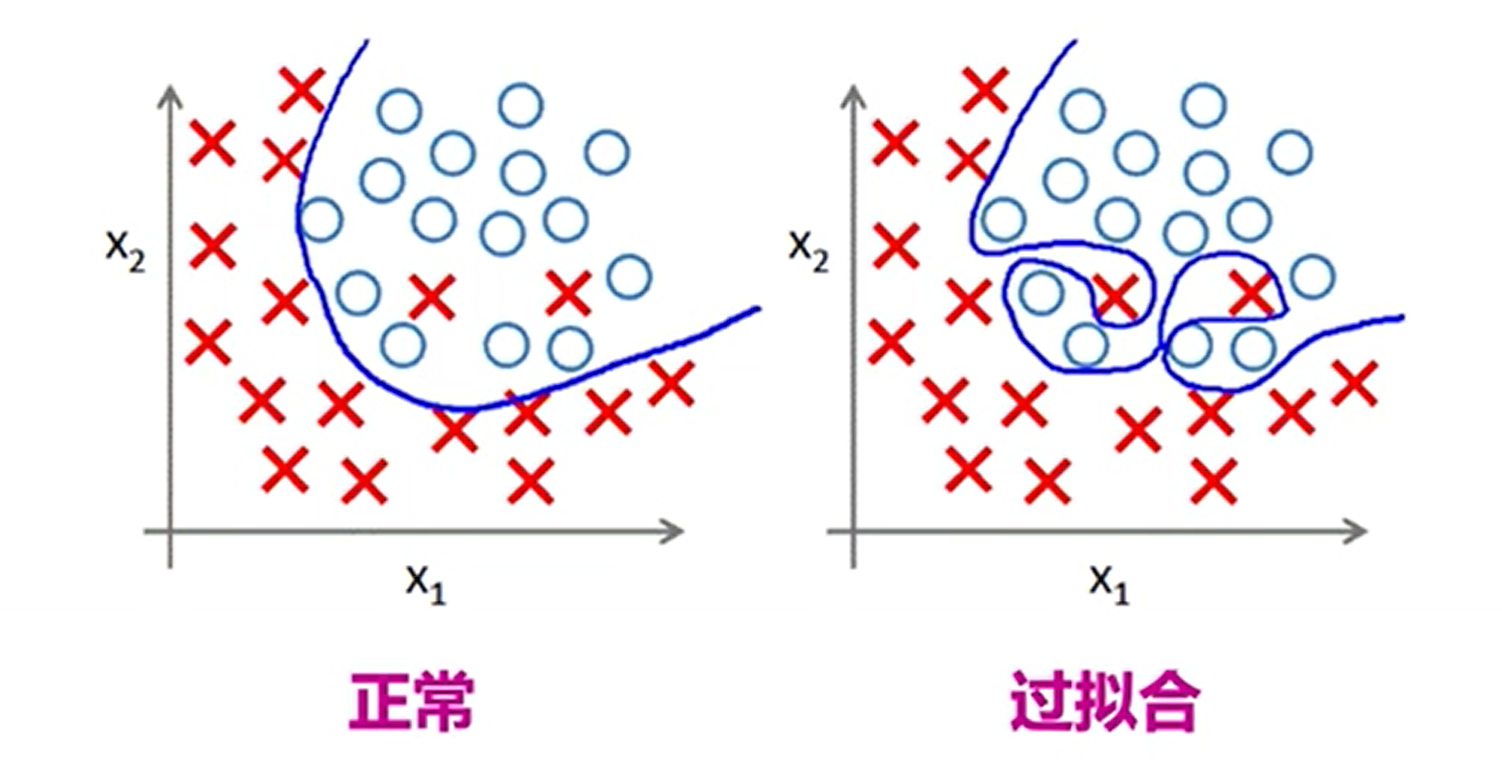

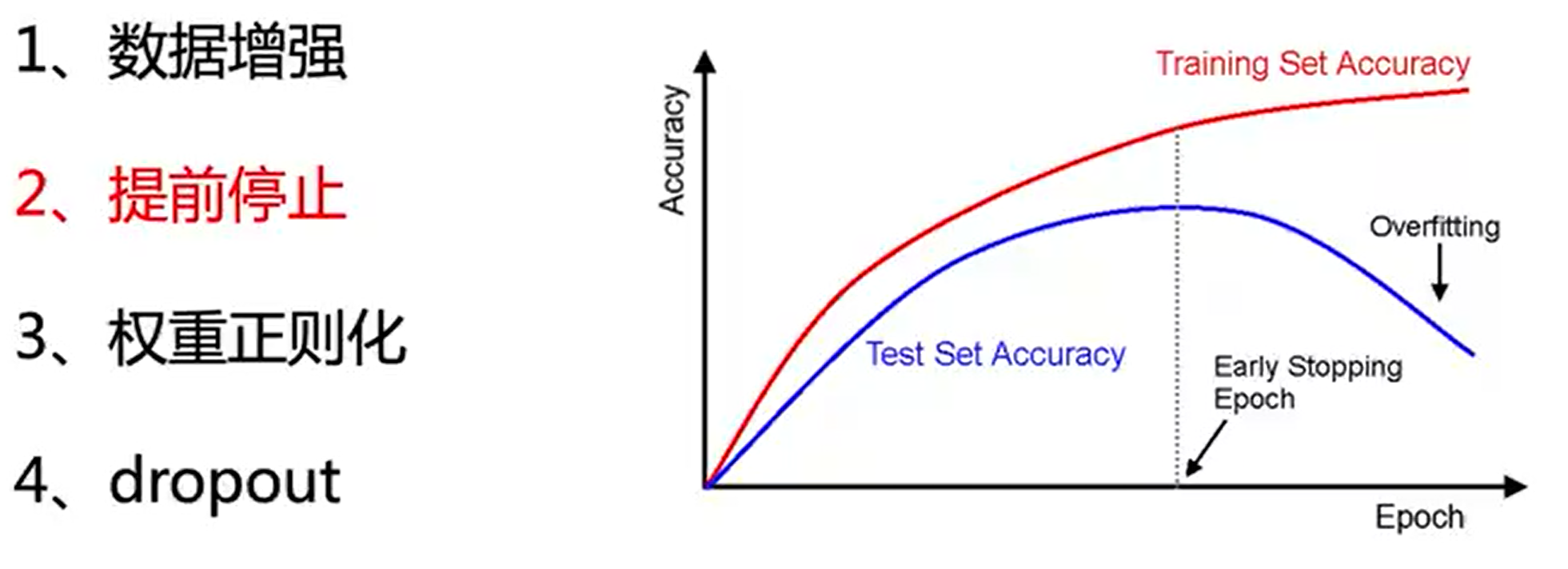
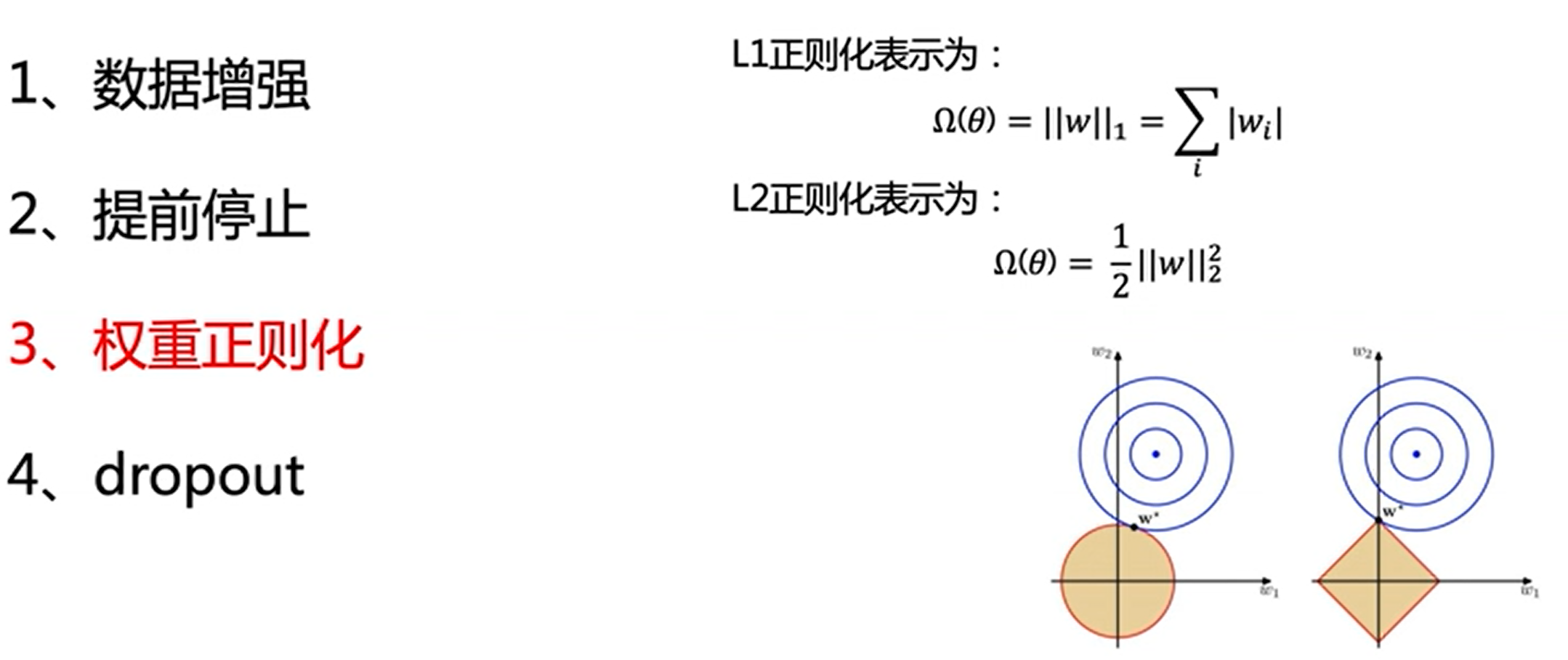
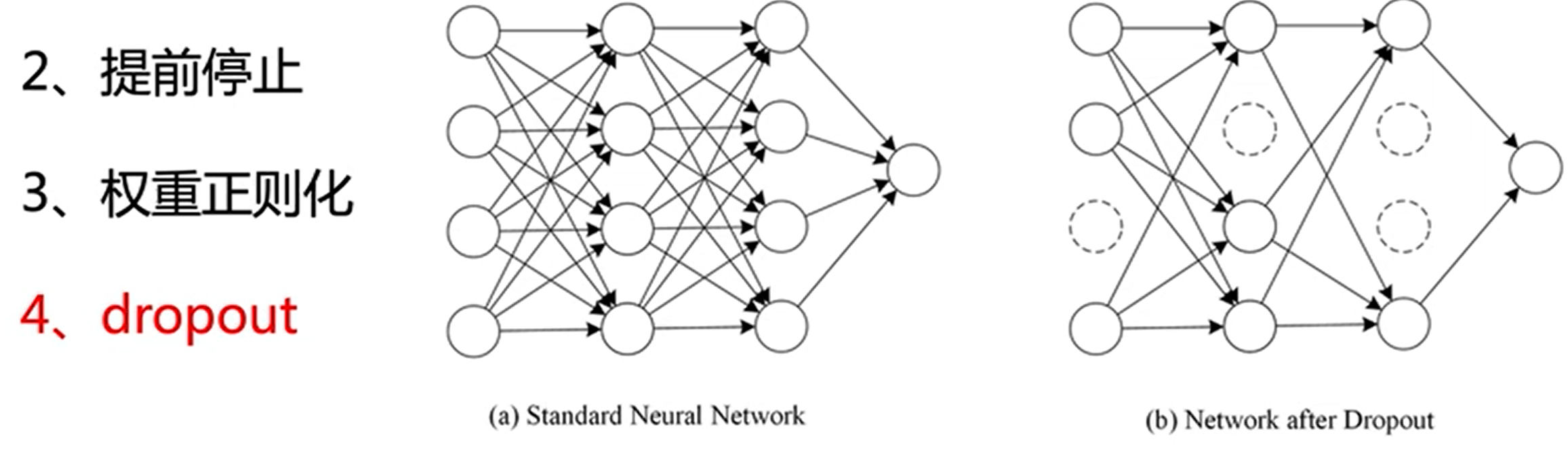
每次随机的让某些结点失活,让网络模型在训练过程中,更容易发挥一些变化
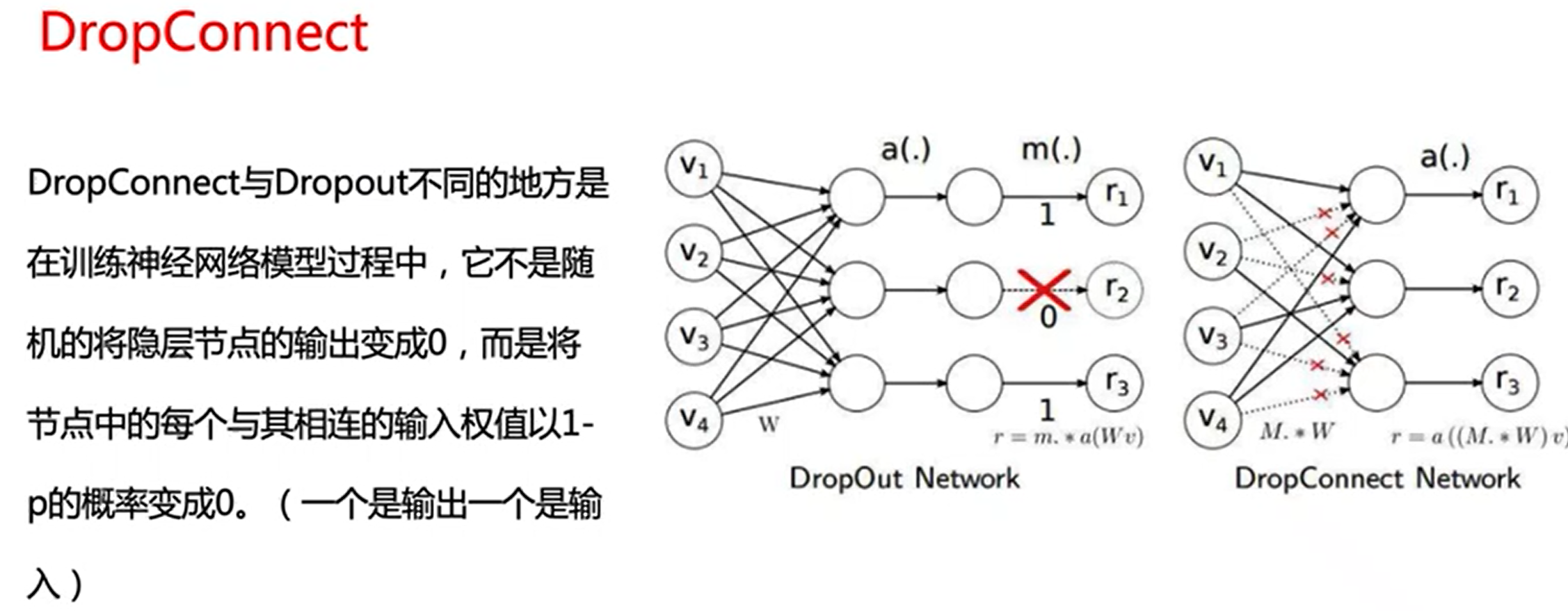
DropConnect是随机失活掉一些链接
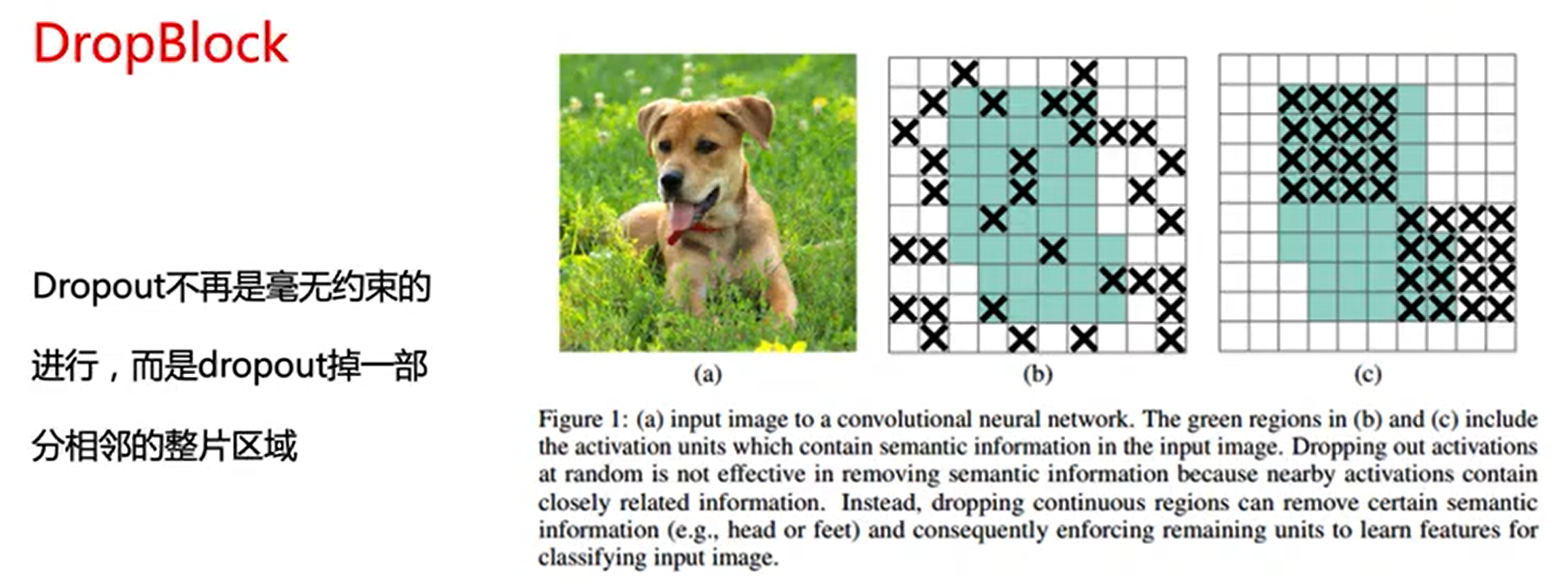
DropBlock是随机失火了一些区域
调参其他方法


开源社区

发现bug,为社区做出贡献。
如何创作好的开源项目
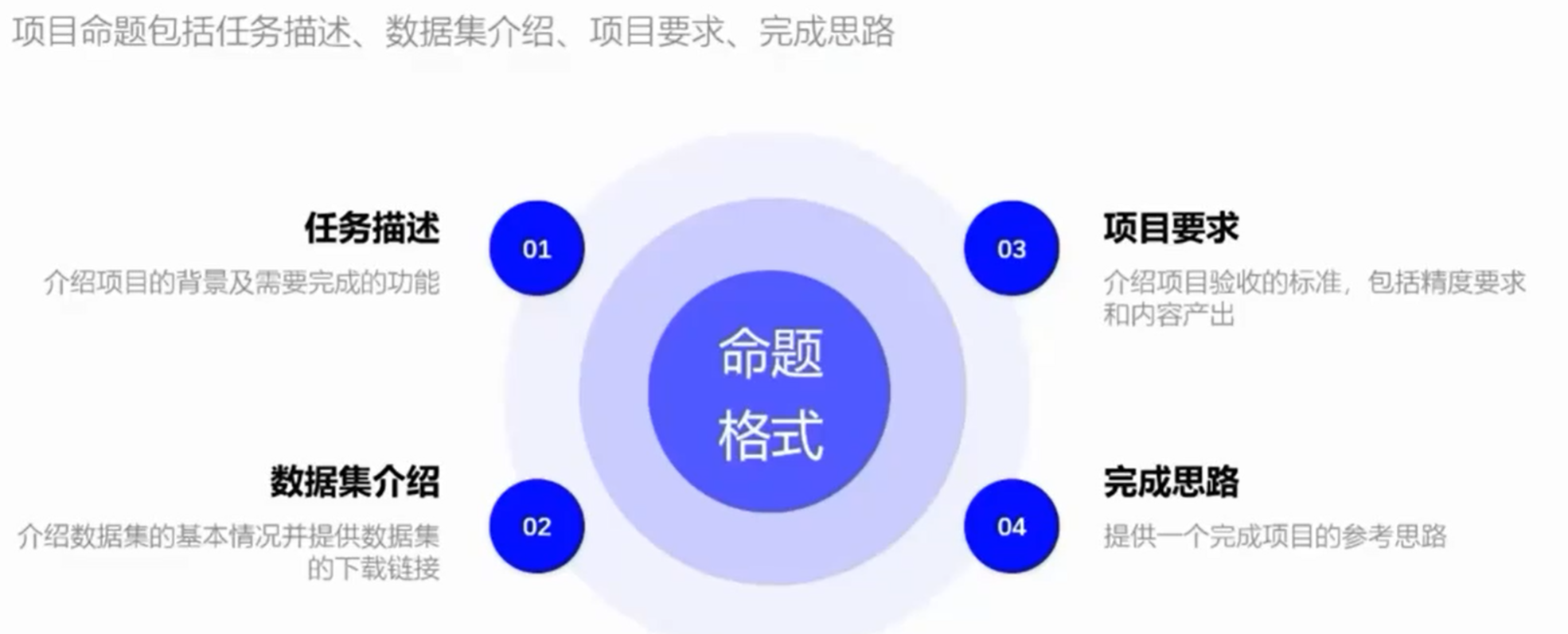
例子一
任务描述


数据集介绍

验收标准

例子二
赛题描述


介绍数据集

验收标准

模型选择思路
例子三

背景

数据集介绍


验收标准

实现思路

例子四

背景

数据集

验收标准

NLP
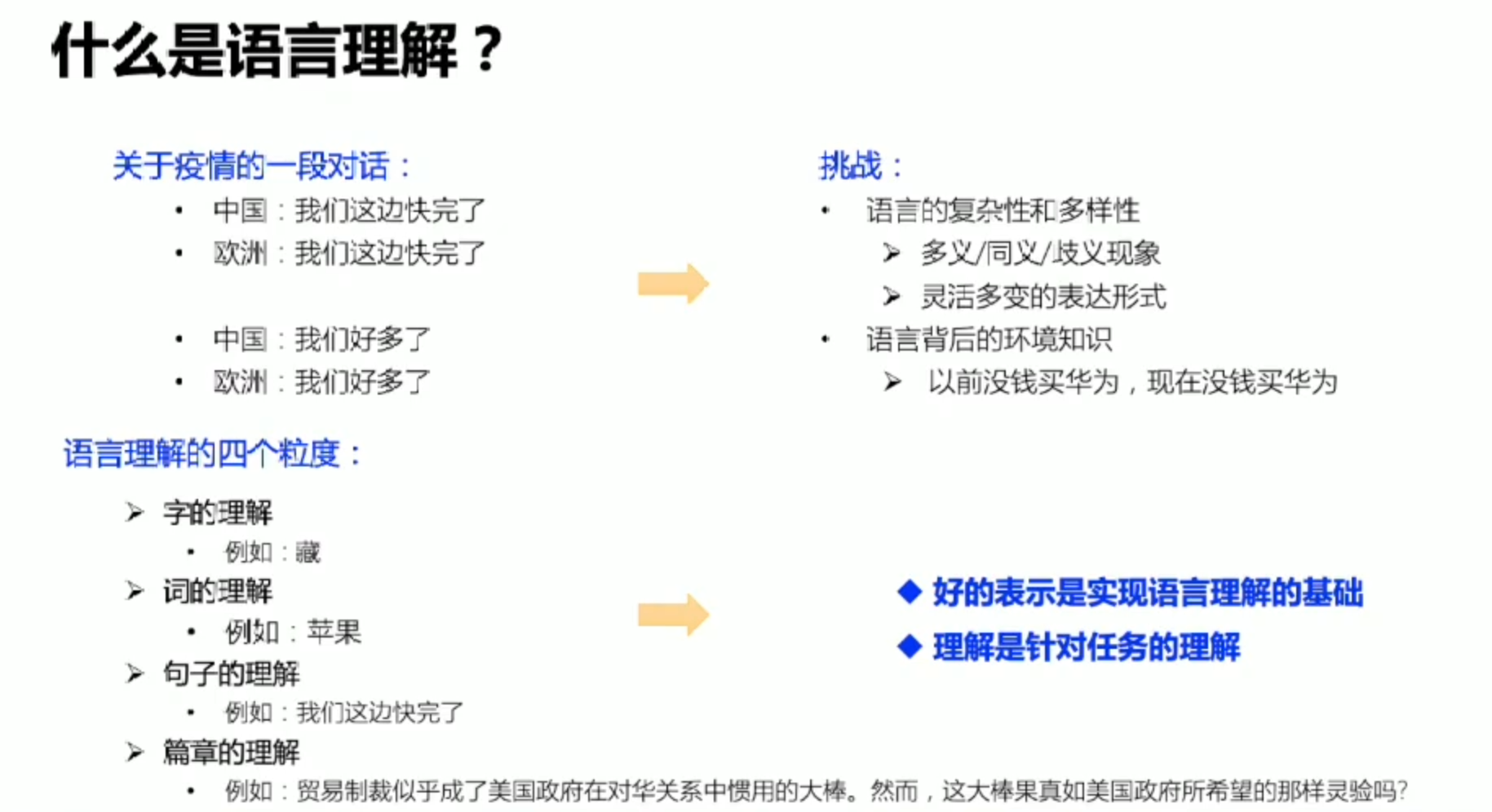
什么是自然语言处理

nlp有什么用
常见应用场景
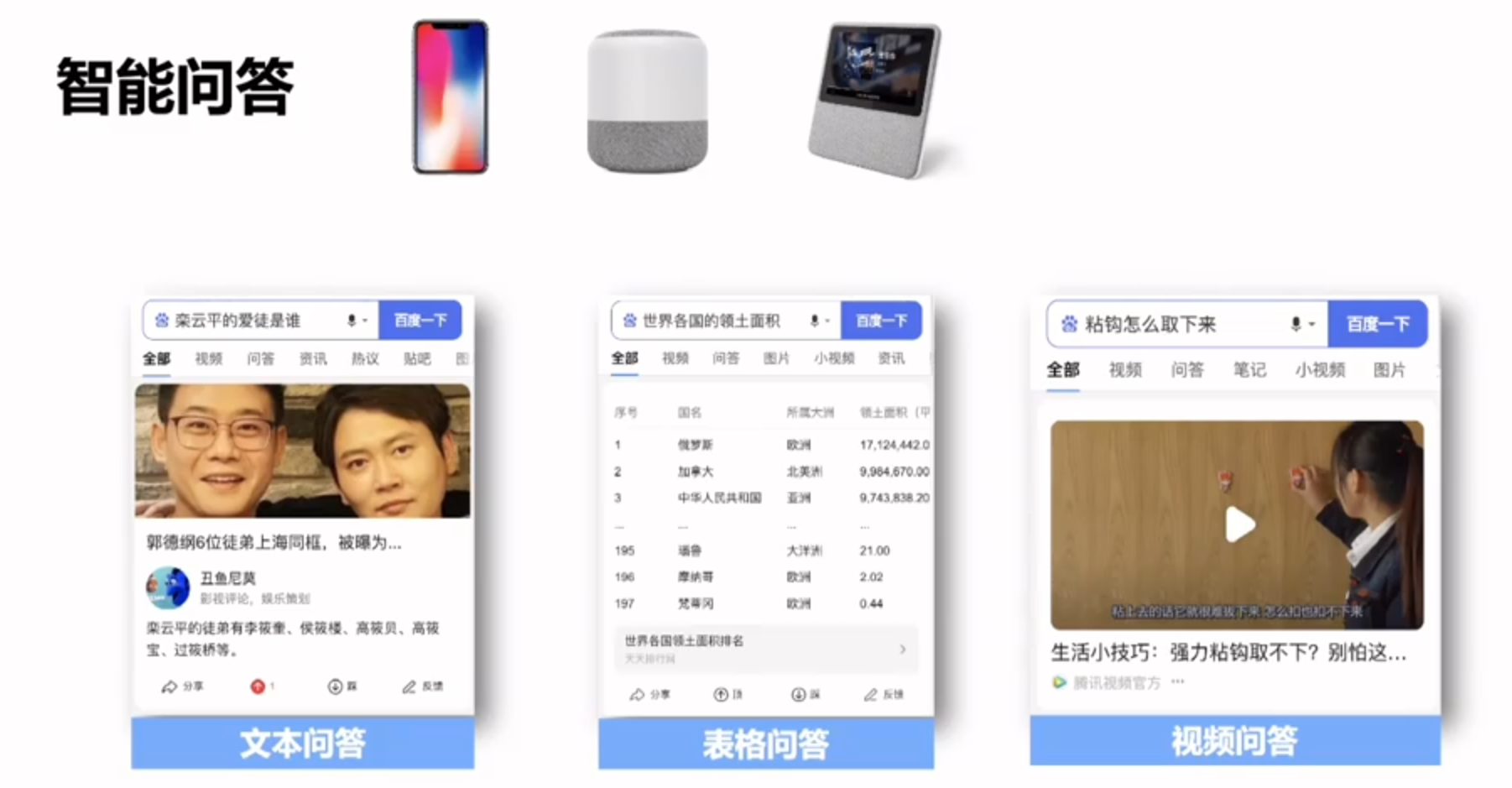

自然语言处理的挑战

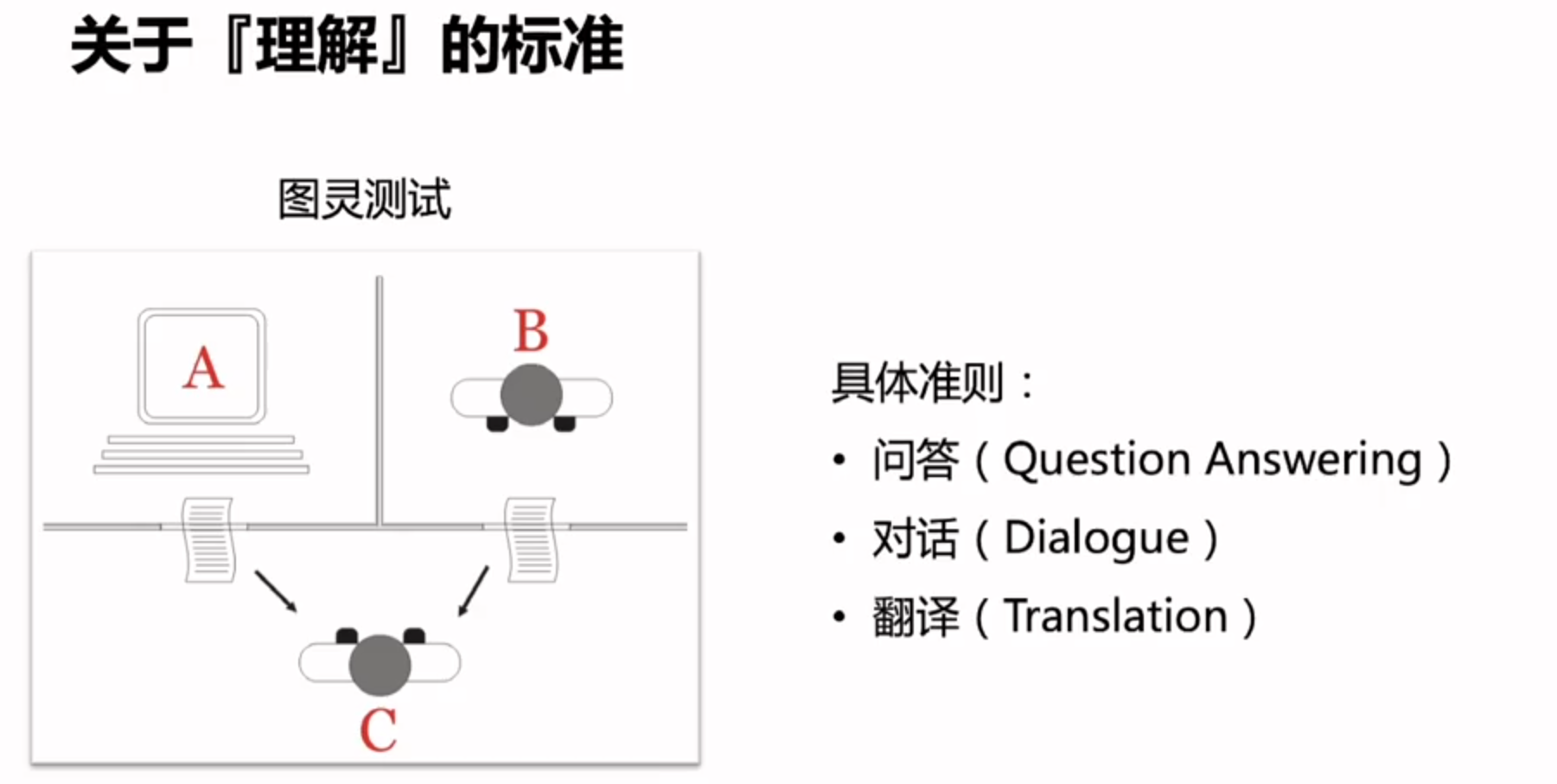
什么叫做图灵测试呢?
用对话来举例:当A和B同时给人类C发送一段回答,人类C都已经无法分辨这段话到底来自于人还是机器,我们就说计算机通过了图灵测试
翻译的角度:人类C发送了一段中文,计算机A和人类B都返回了一段英文的翻译,人类C已经无法分辨这段文字来自于人类还是计算机,我们就说翻译的场景下,机器通过了图灵测试。
发展历程
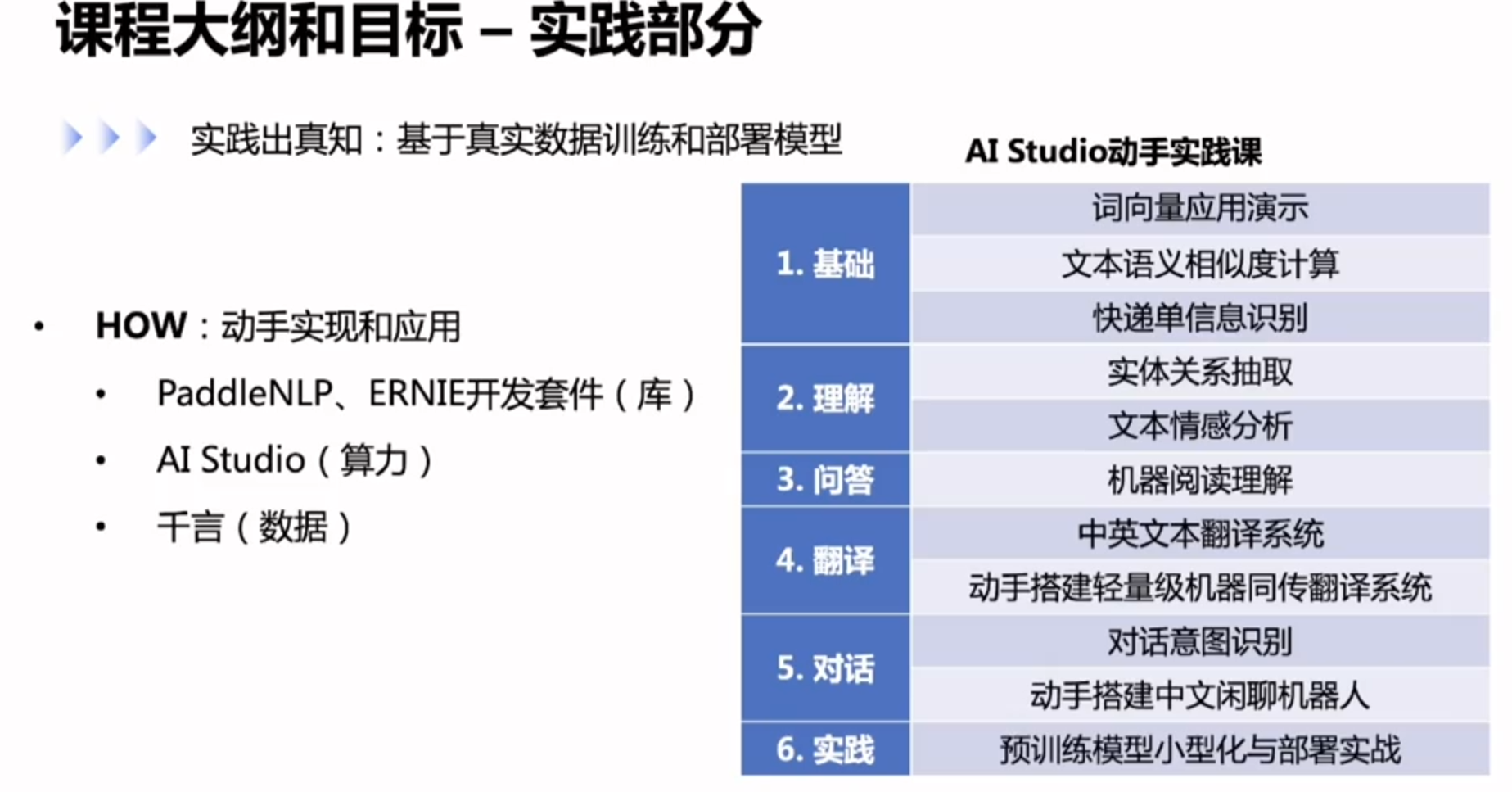
课程大纲

前预训练时代的自监督学习

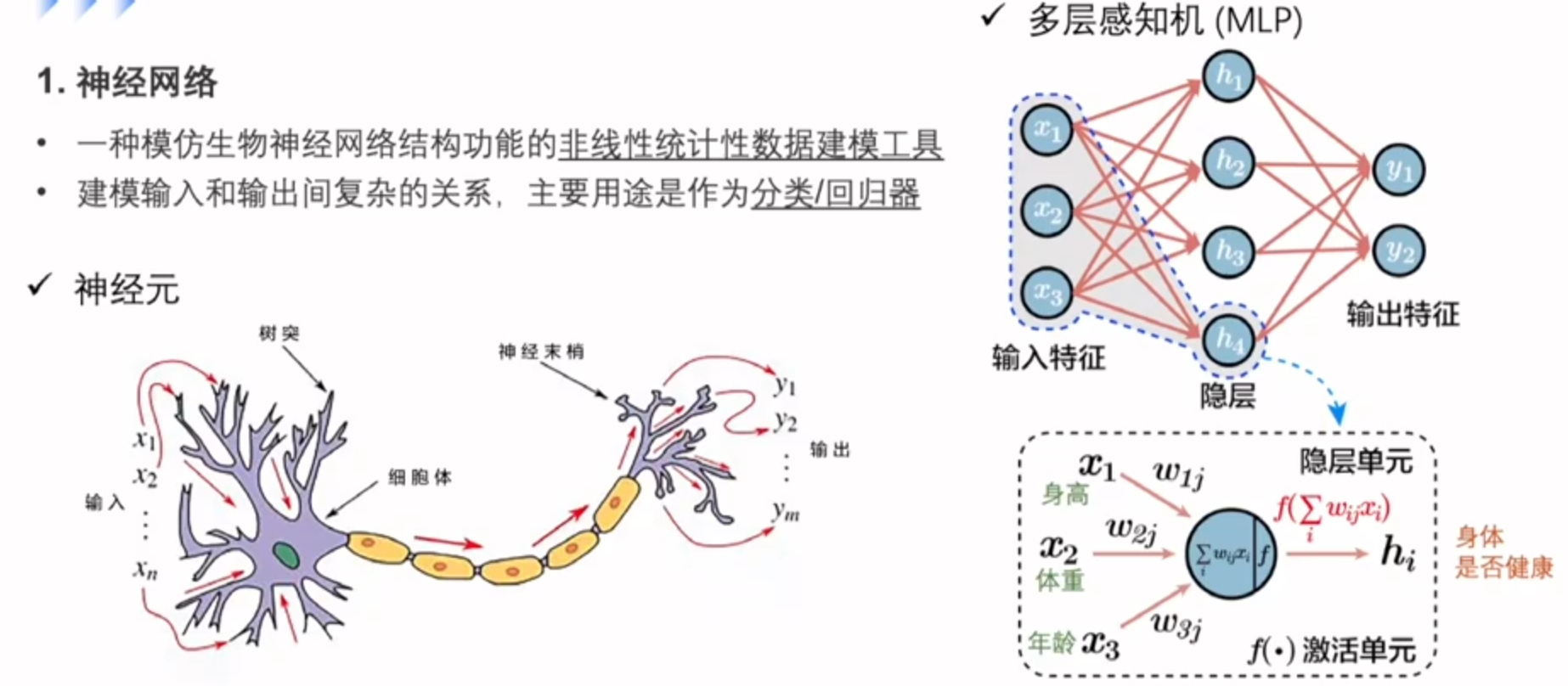
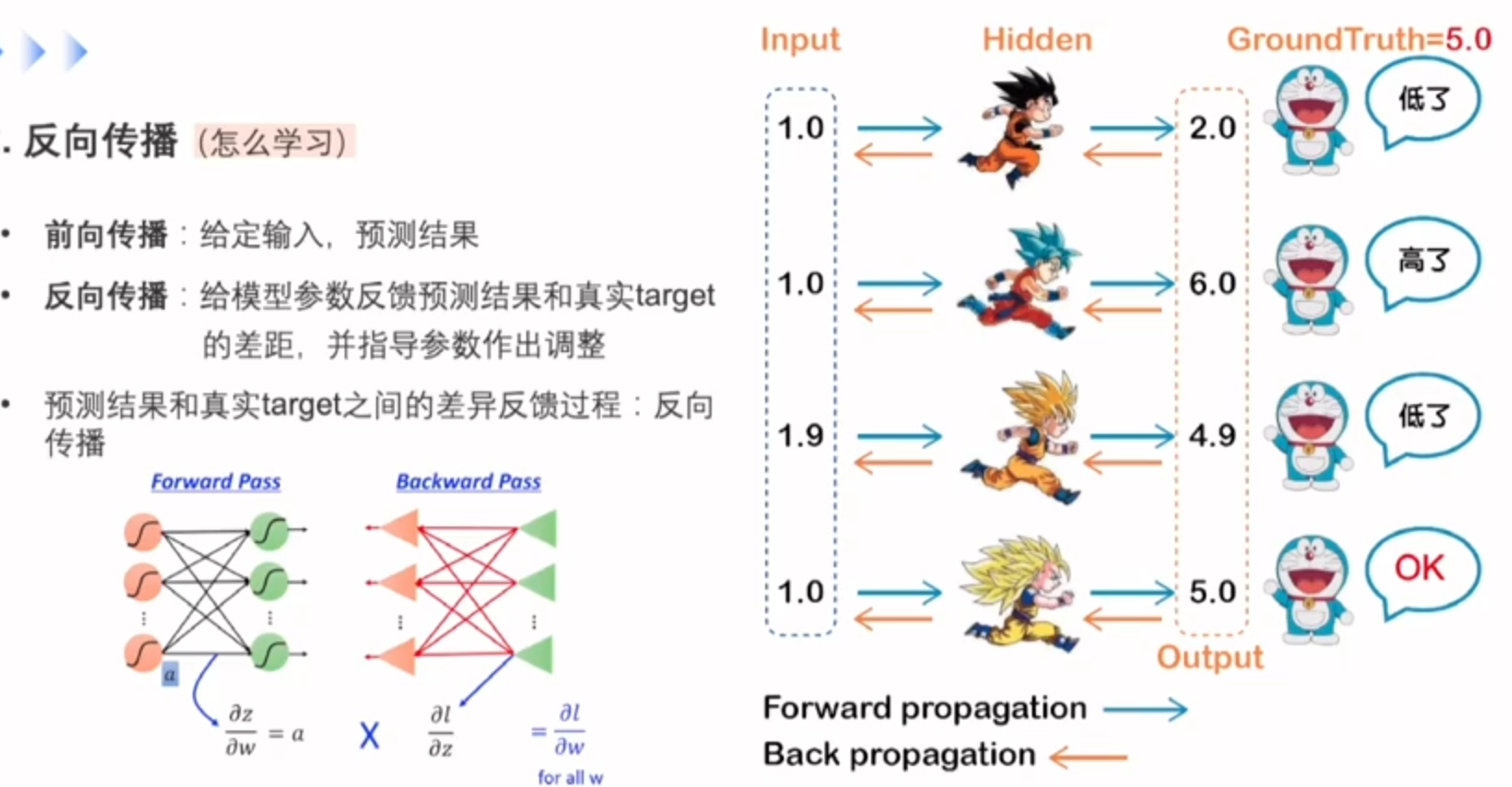
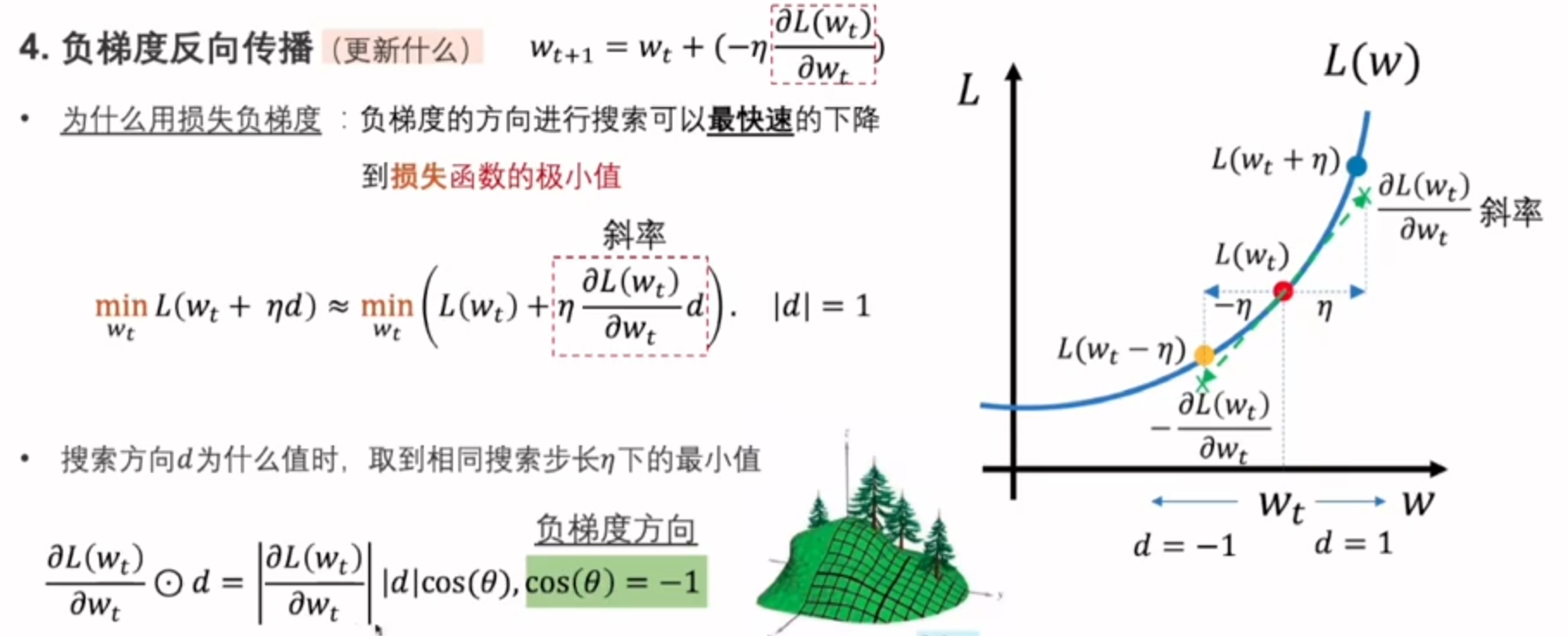
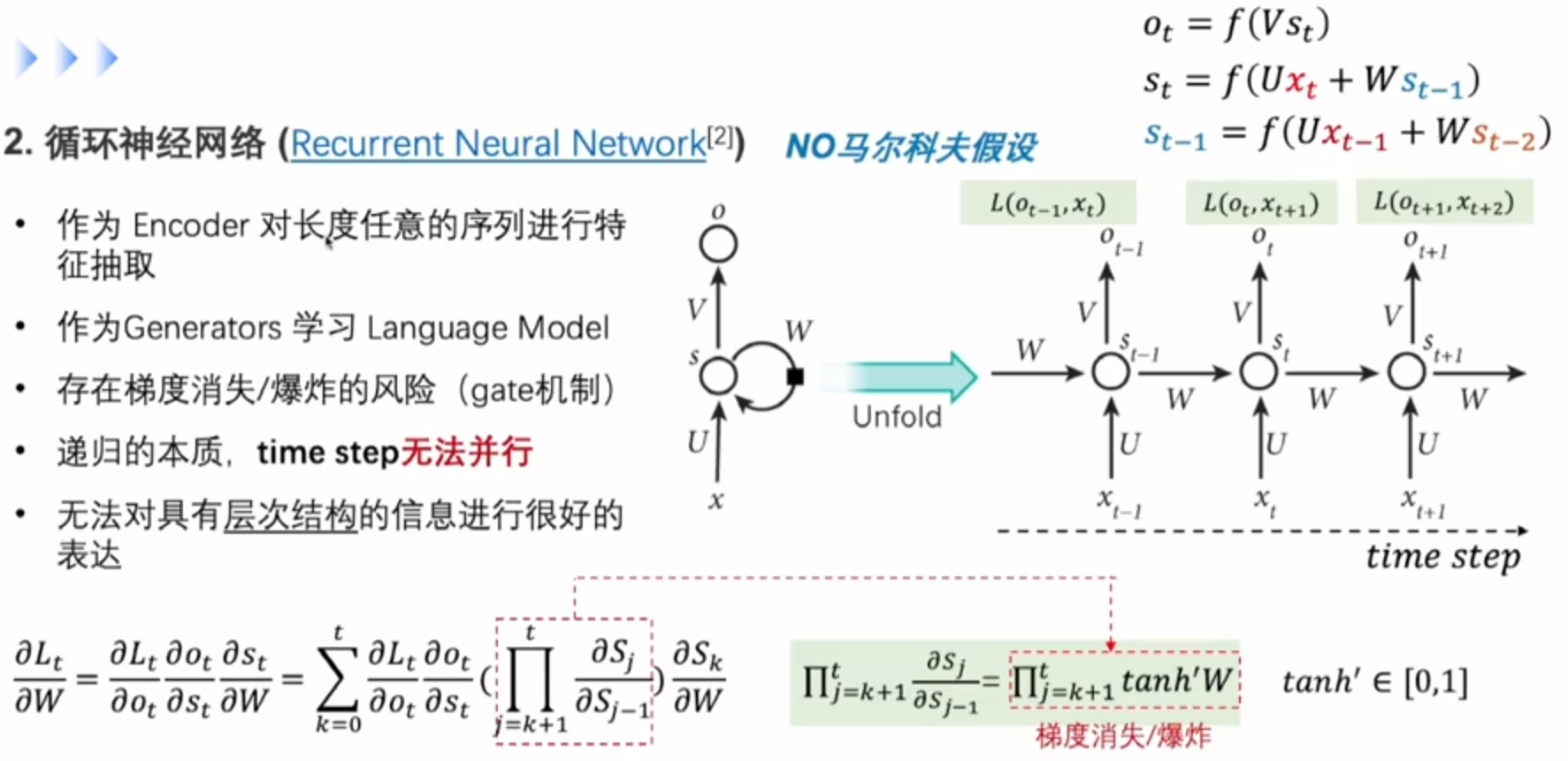
神经网络

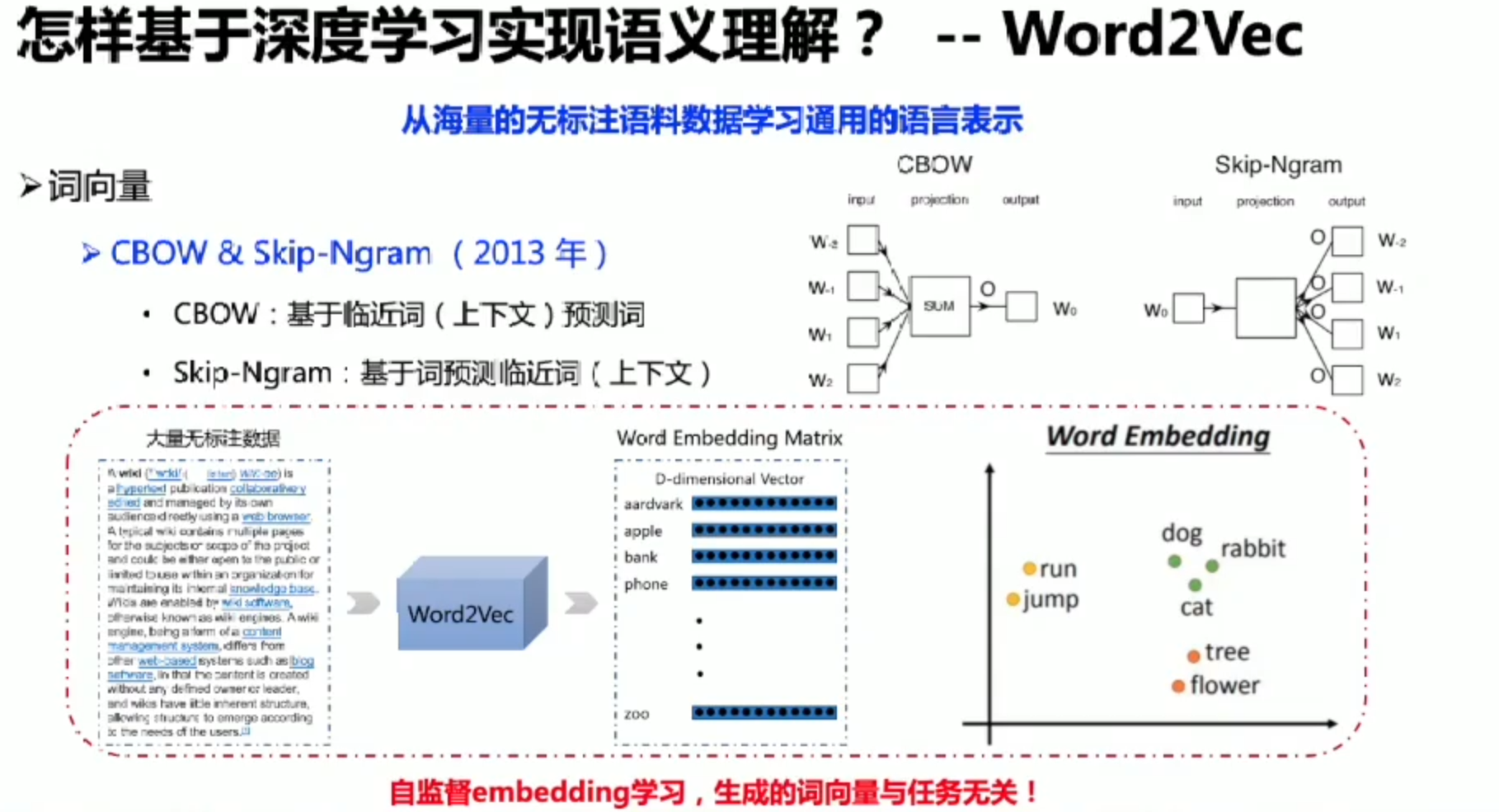
自监督词表示学习
one hot没法更好的反应词与词之间的关系,可以用到Embedding这种编码方式
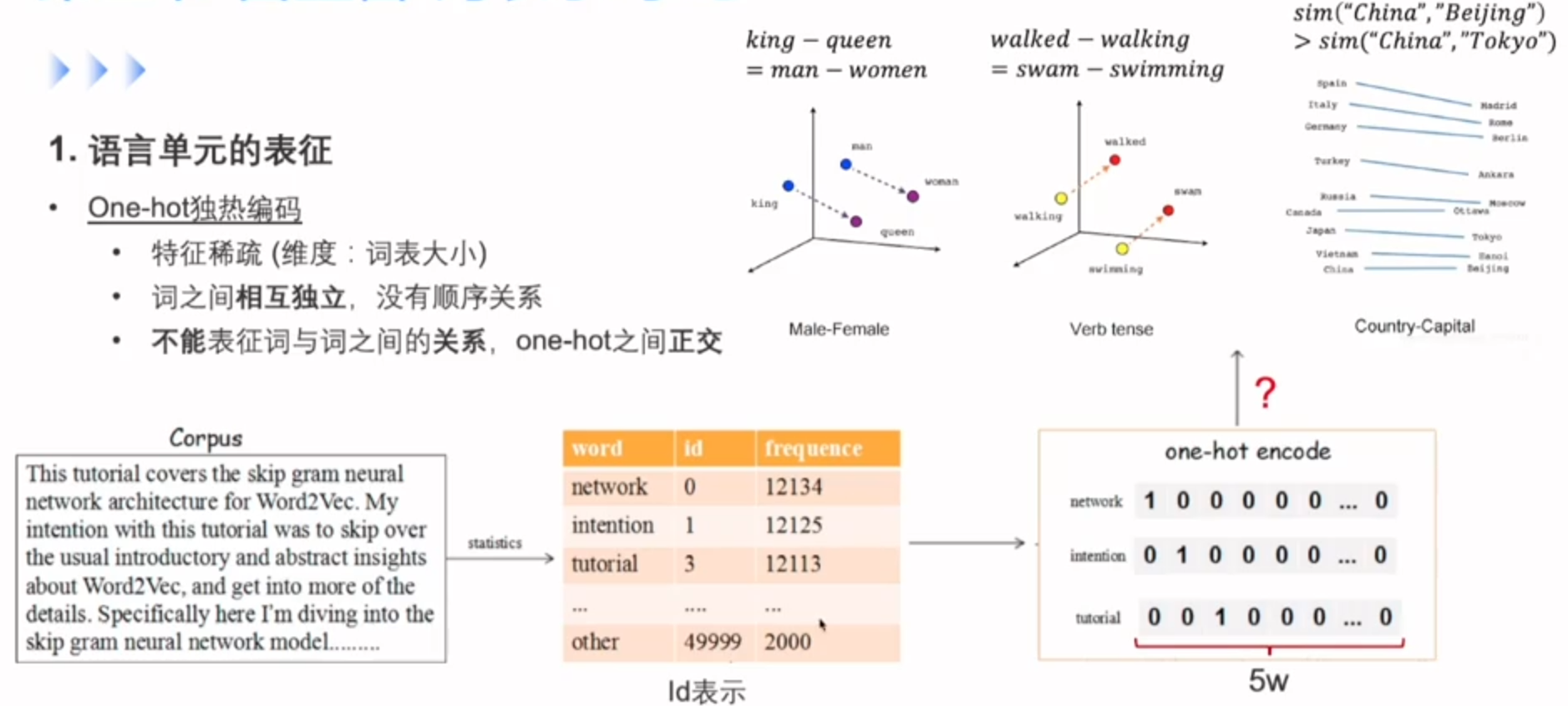
最开始的Embedding层为随机初始化,通过后面Word2Vec去学到了真实的词向量
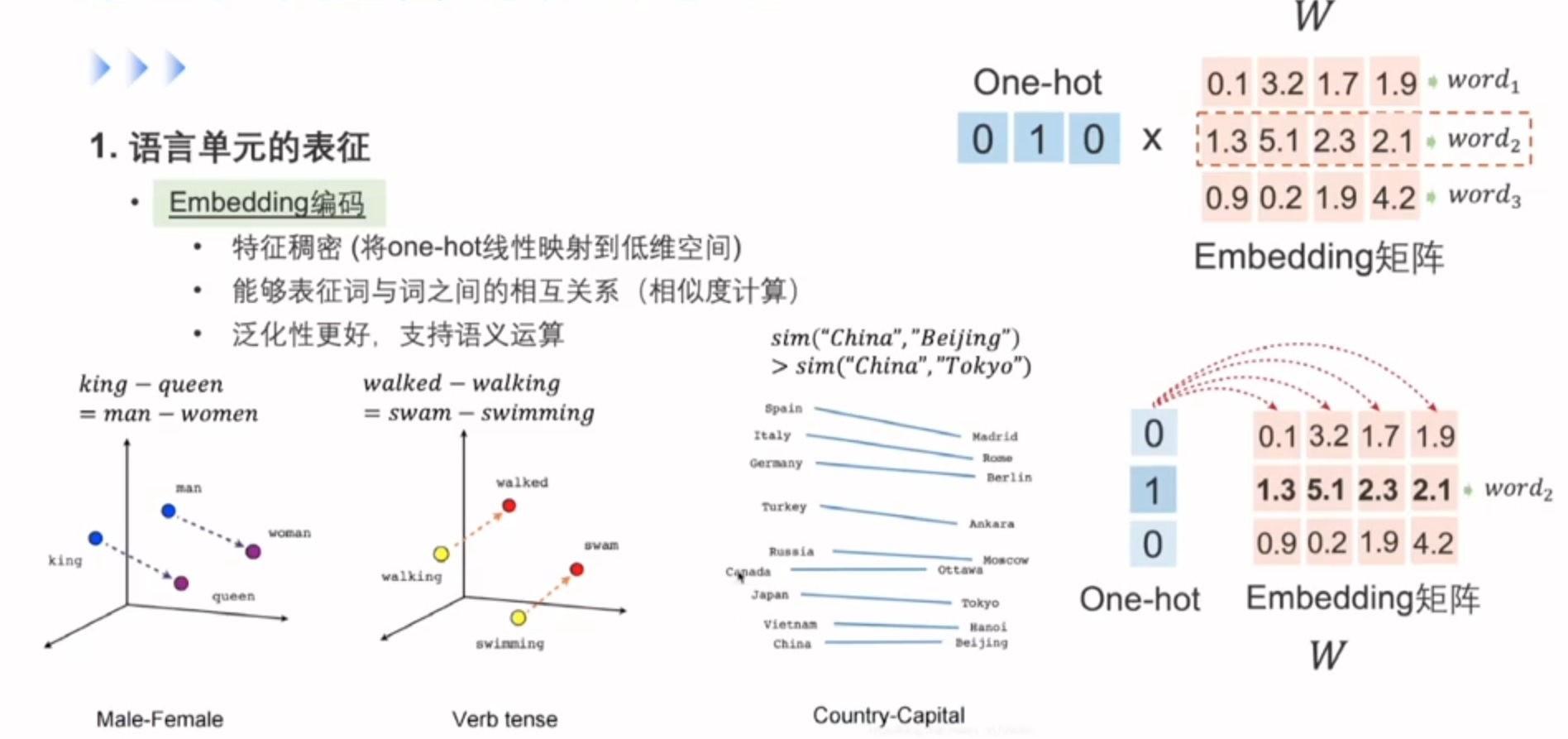
Embedding就是ont-hot的一种线性映射,那么如何去学习Embedding呢?

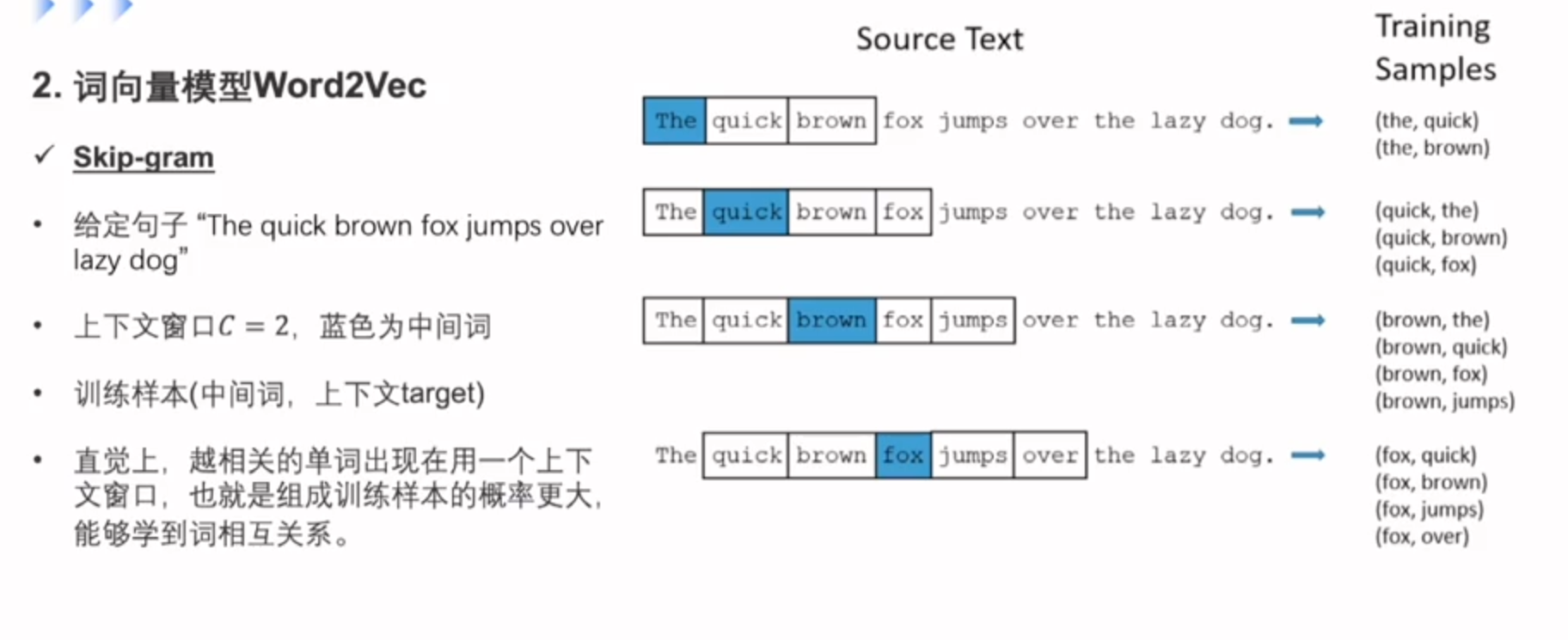
Word2Vec能拿到上下文的信息对词做预测。
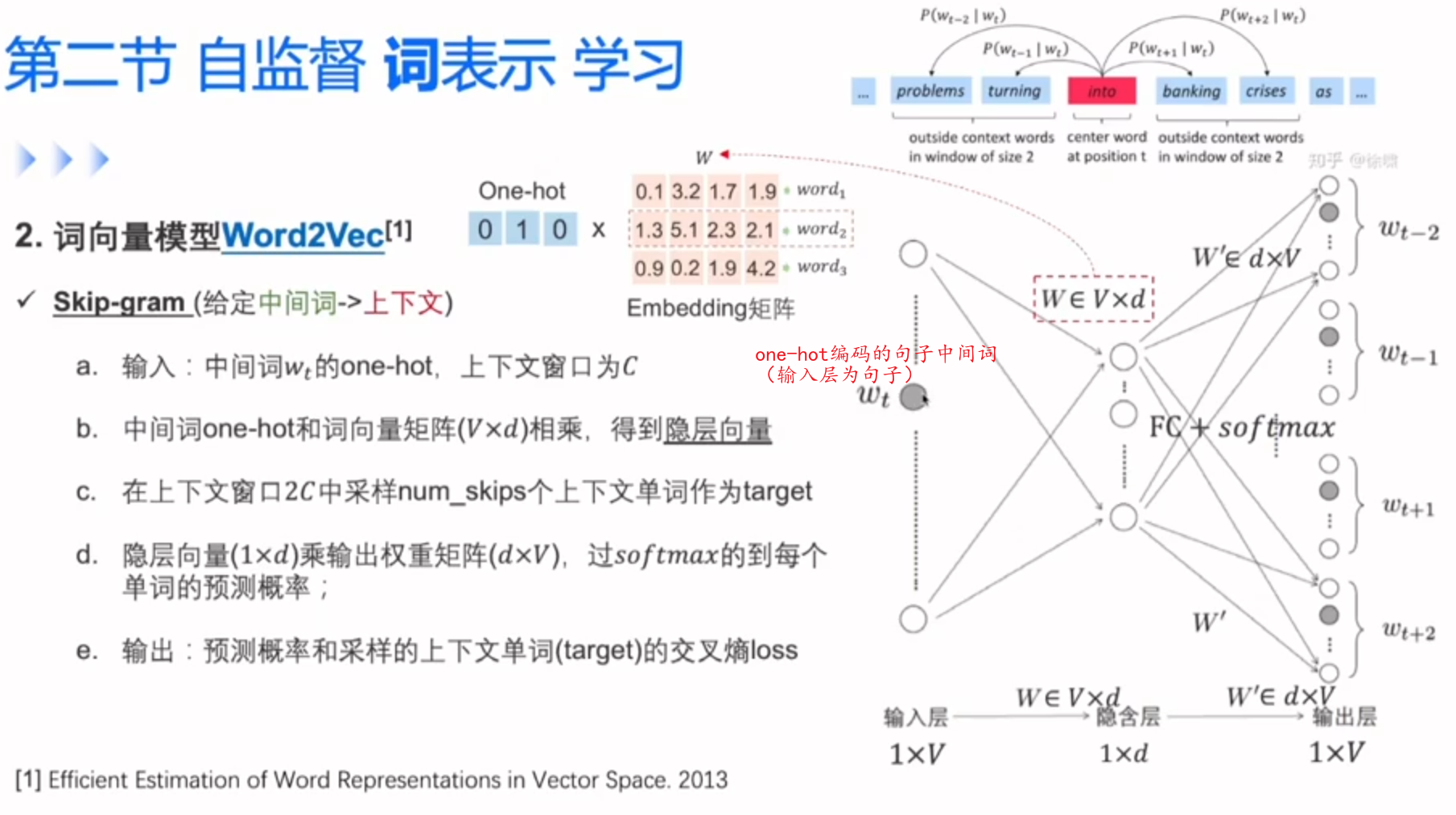
中间的隐层就是词向量
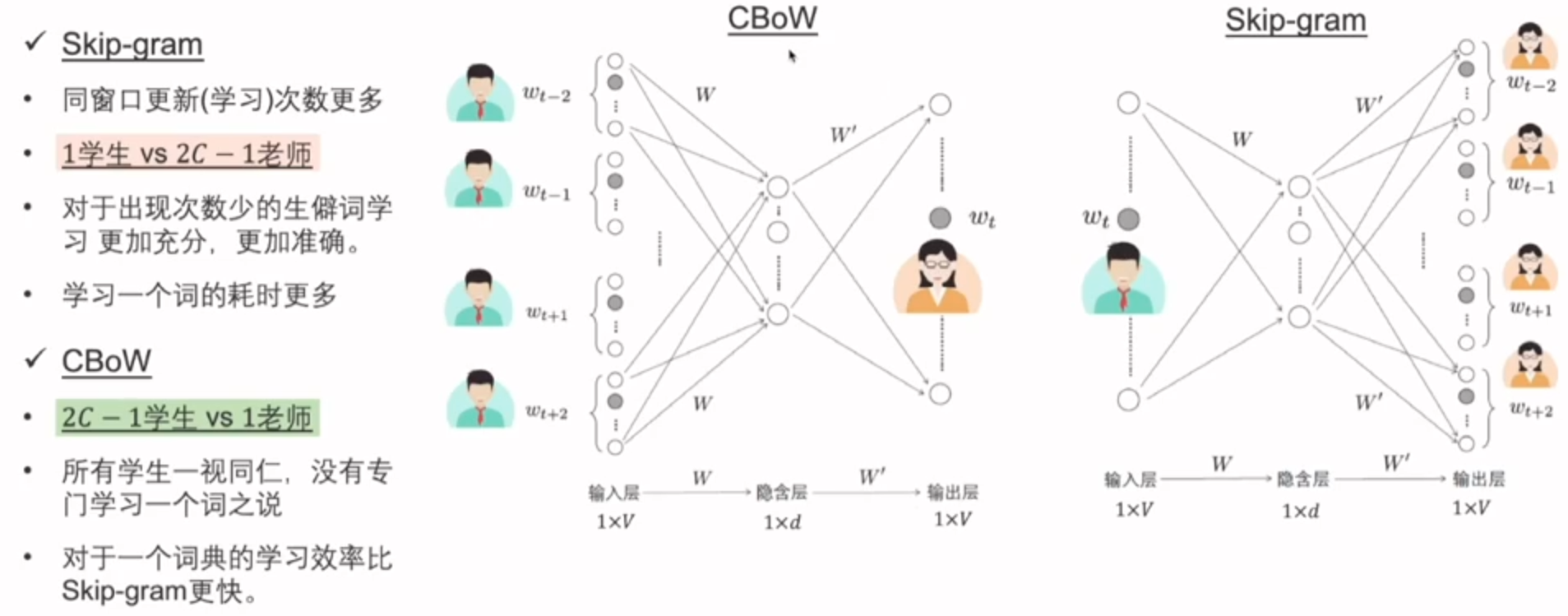
CBoW,最大化中间词的概率
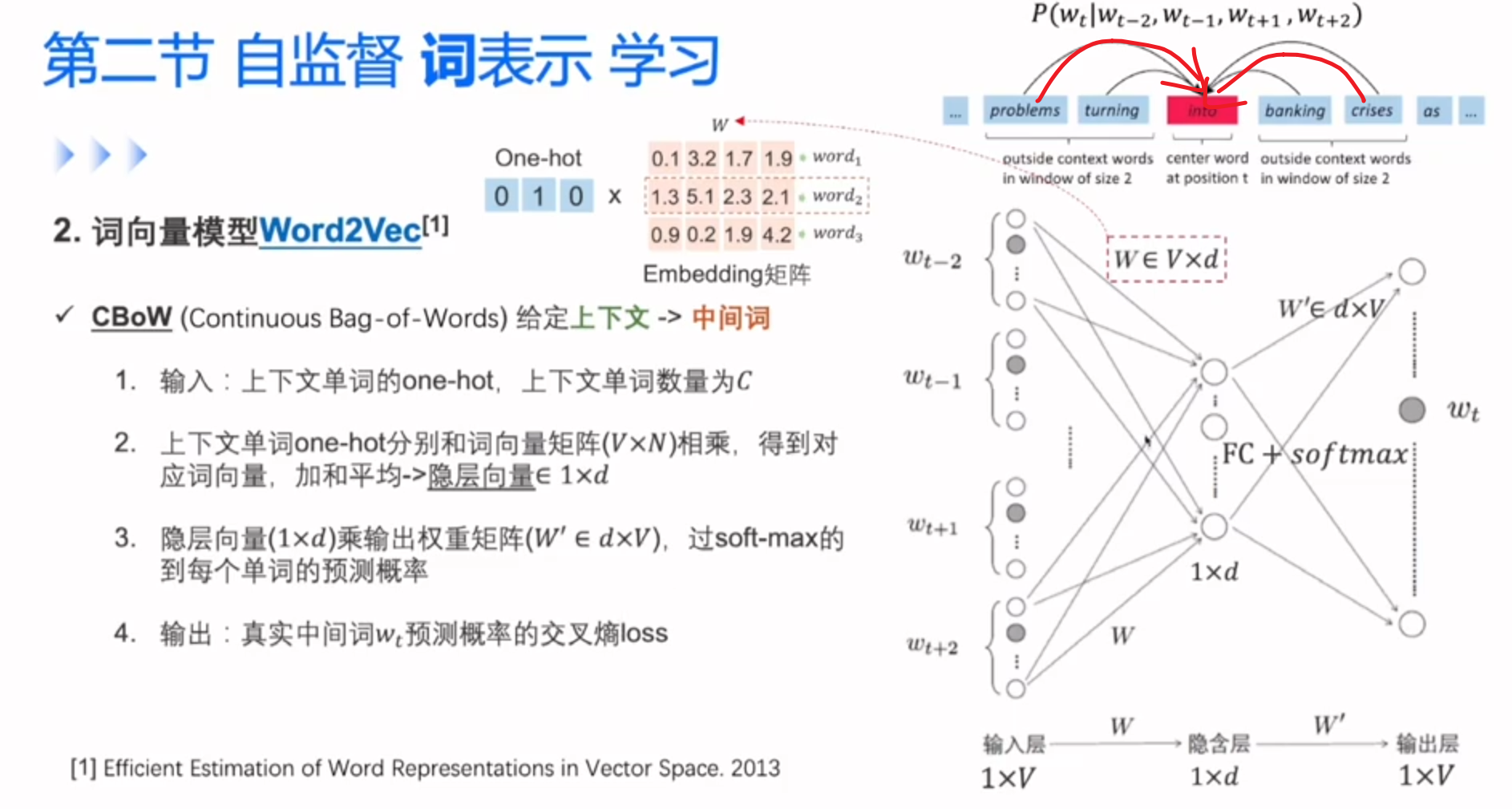
Skip-gram与CBoW的比较
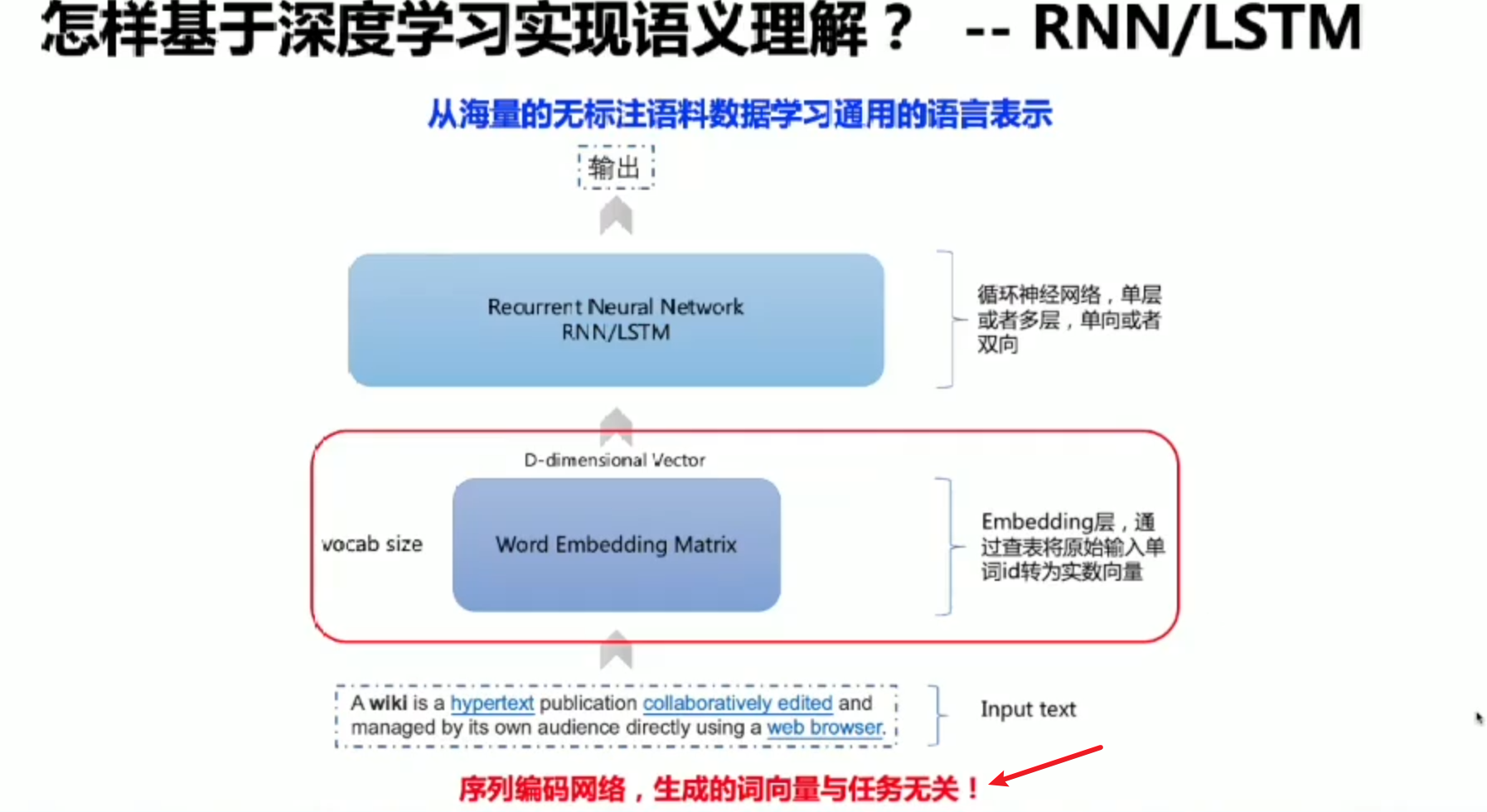
句子编码神经网络
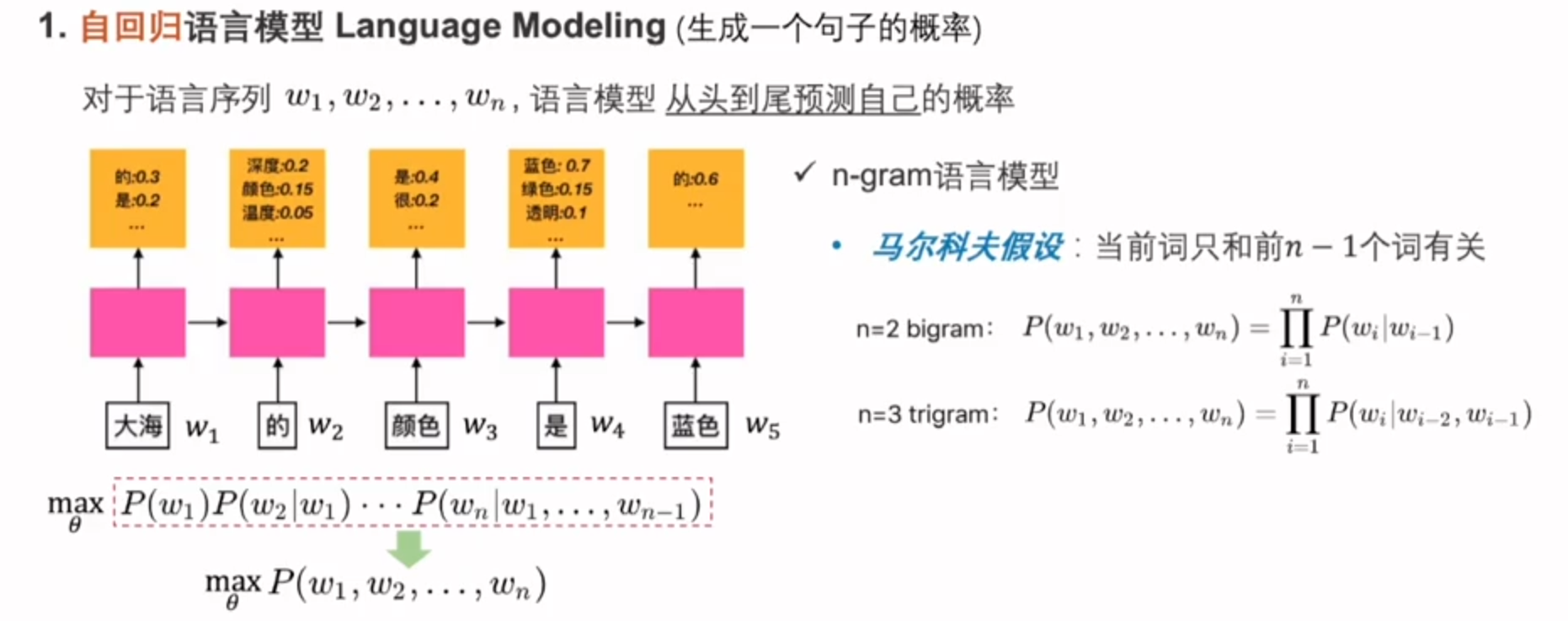
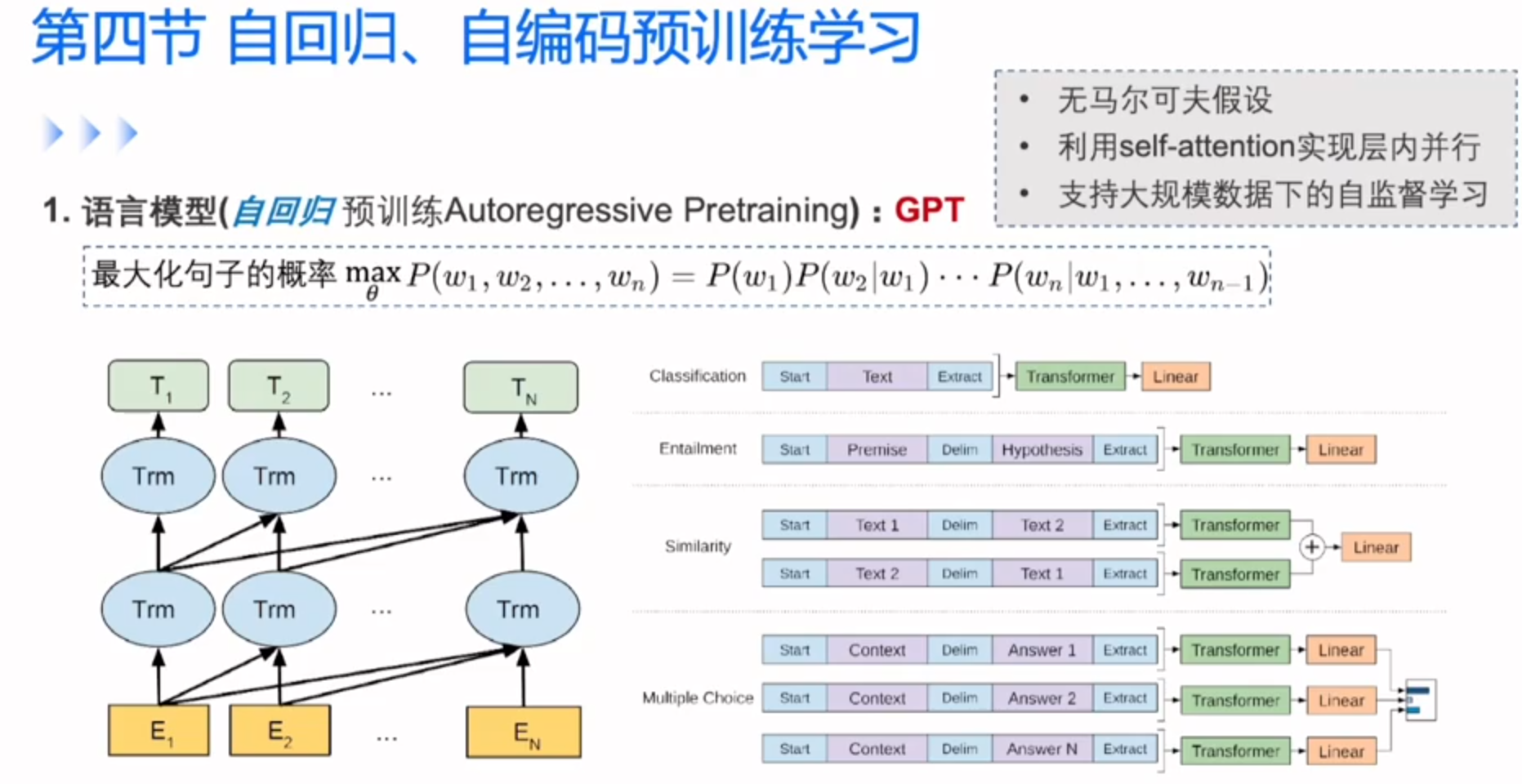
自回归只拿到上文的信息
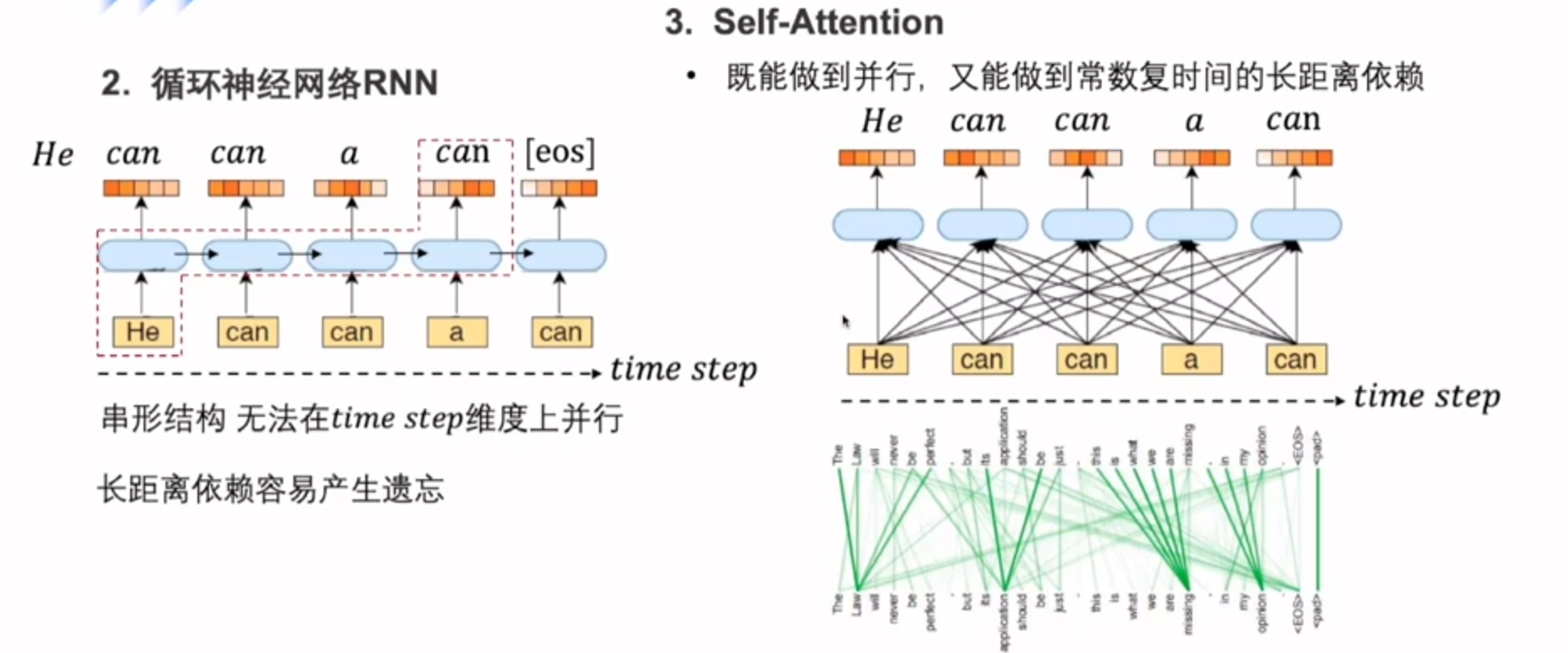
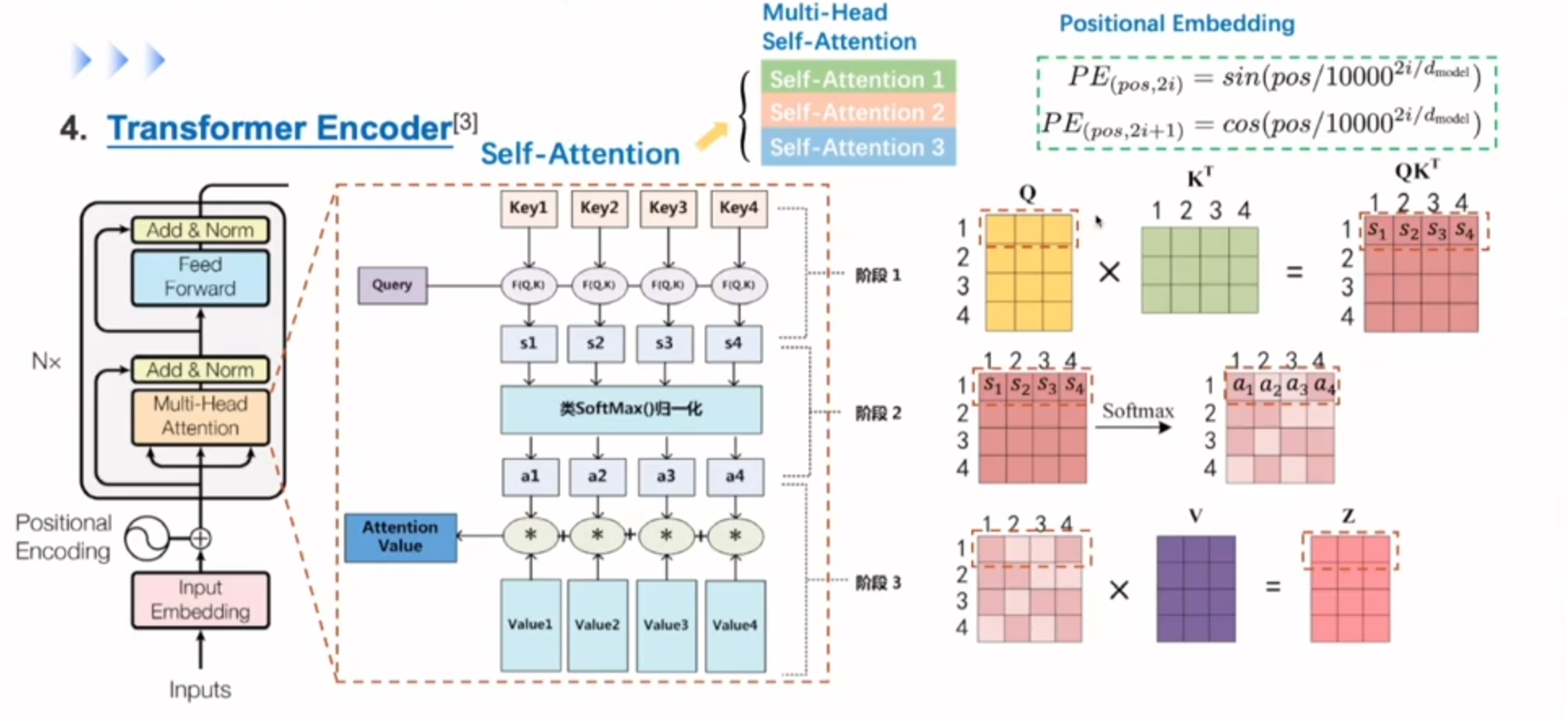
重点再次介绍self-Attention
假设只有四个单词
Q的第一行会和K向量分别计算内积,得到四个Score,后对四个Score做Softmax(归一化),就可以得到一个0-1的概率分布
拿到注意力的权重之和,会对输入句子里面的value向量分别做一个加权,融合整个句子序列的特征得到Z向量(更新的单词表示)
transformer中就是采用多头注意力机制,就是把每个注意力的结果不断叠加,这样会形成多个子空间,让模型去关注语言信息模型信息不同的方面的部分,让模型对句子有个多视角的理解。
但self-attention并不会对同一个单词在句子的不同位置有相关的癖好啥的,为了更精准的去表示句子信息,对输入加入一个位置信号,也就是右上角的positionail embedding
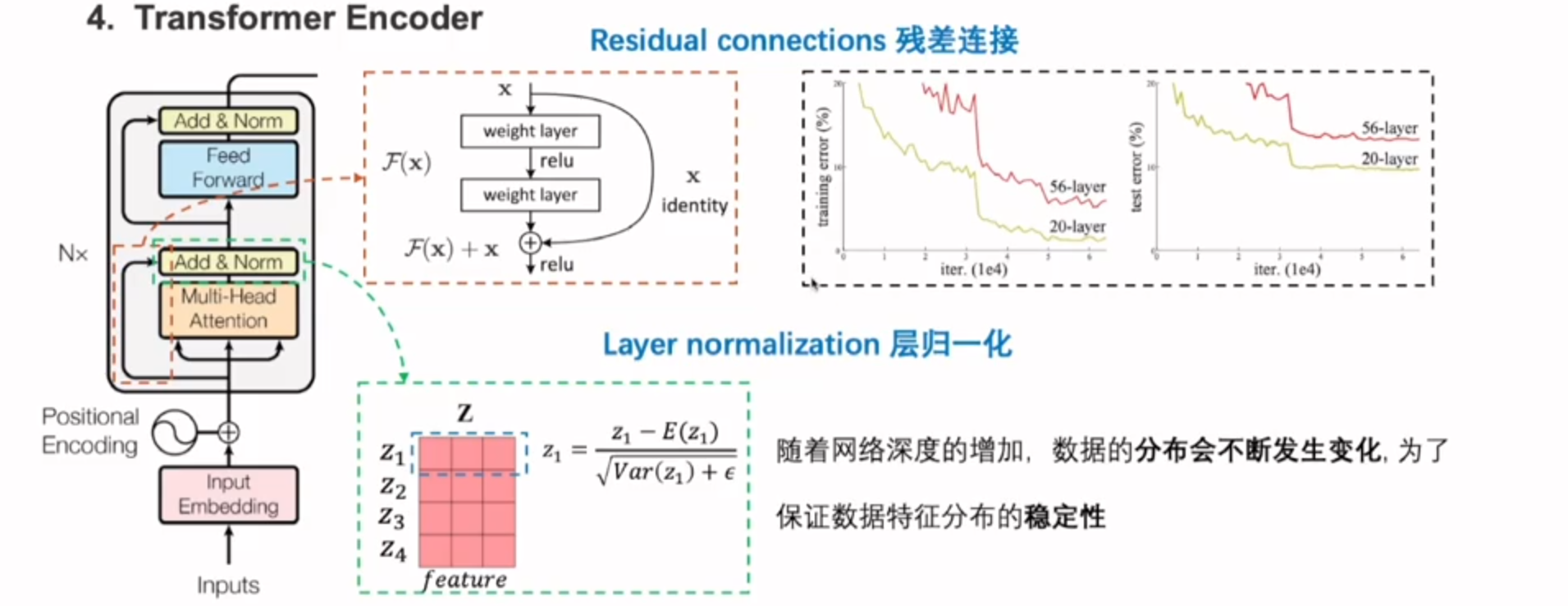
残差连接
包含映射(经过relu)和直链接(跳连接)部分
这样的话梯度就多了一个常数项x,很好的缓解了梯度消失的问题
做完残差再做归一化,保证分布的统一,数据的稳定性
自回归预训练学习
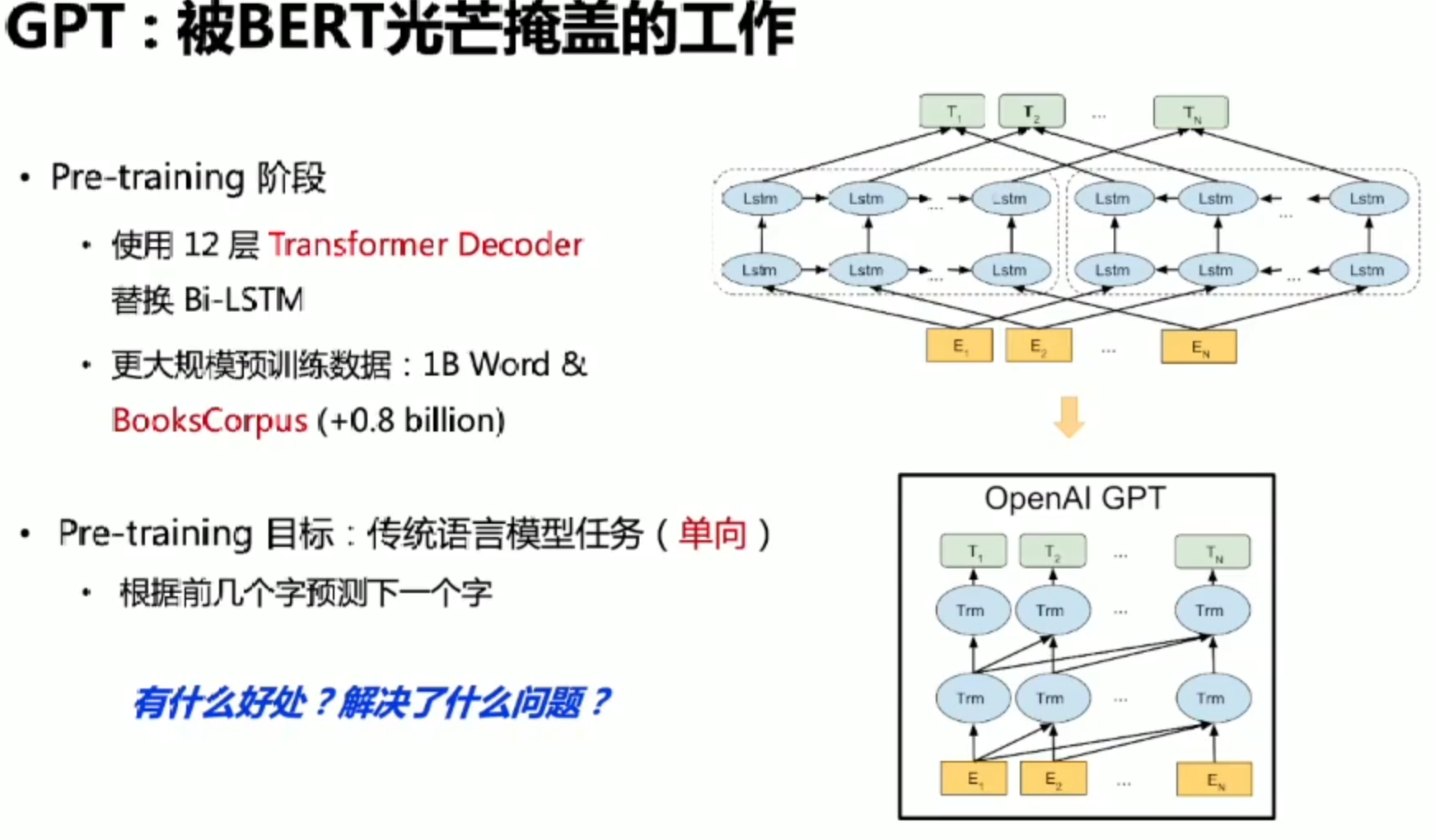
GPT就是transformer在大规模语言数据上来学习的语言模型
每个单词只能看到上文的单词,句子表示能力更强?
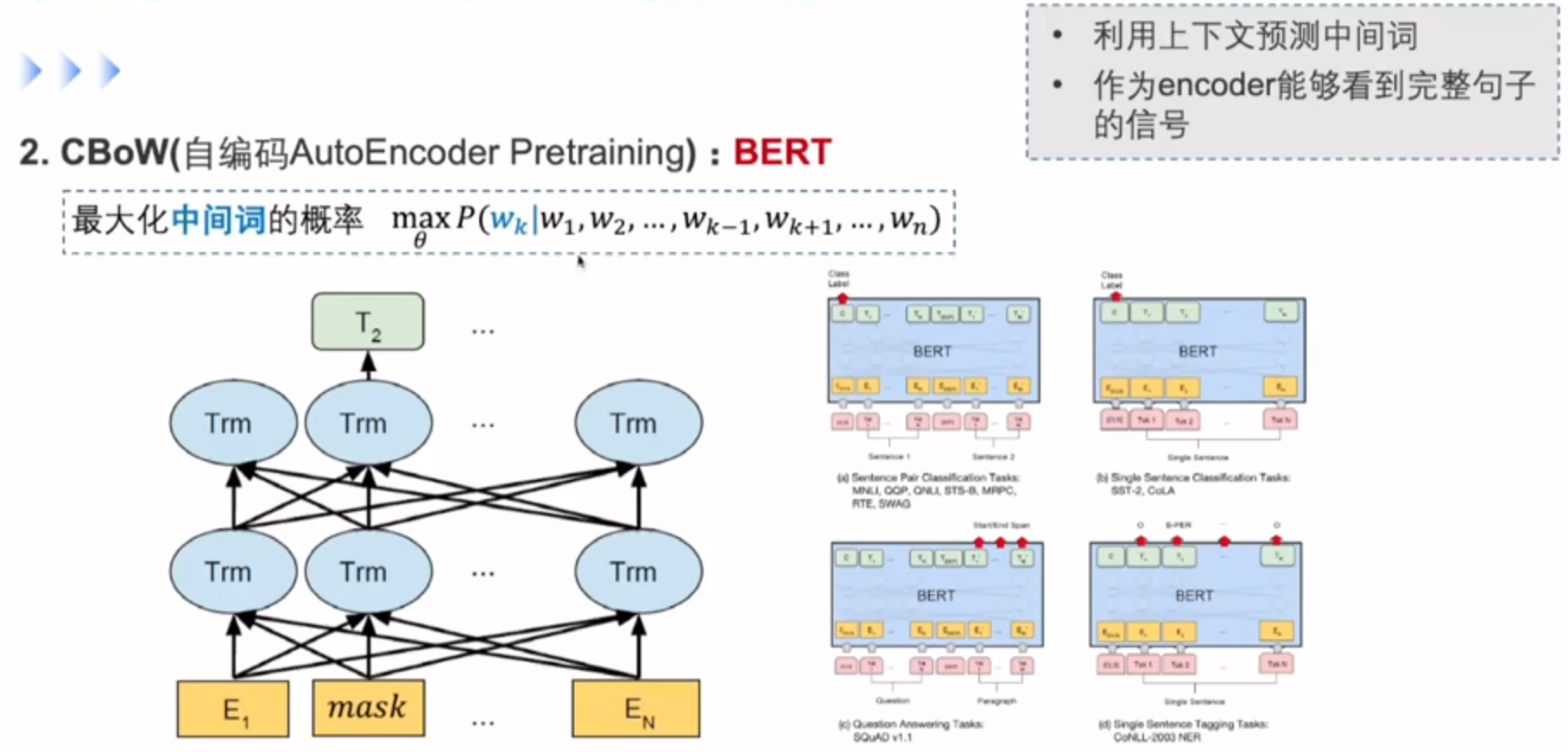
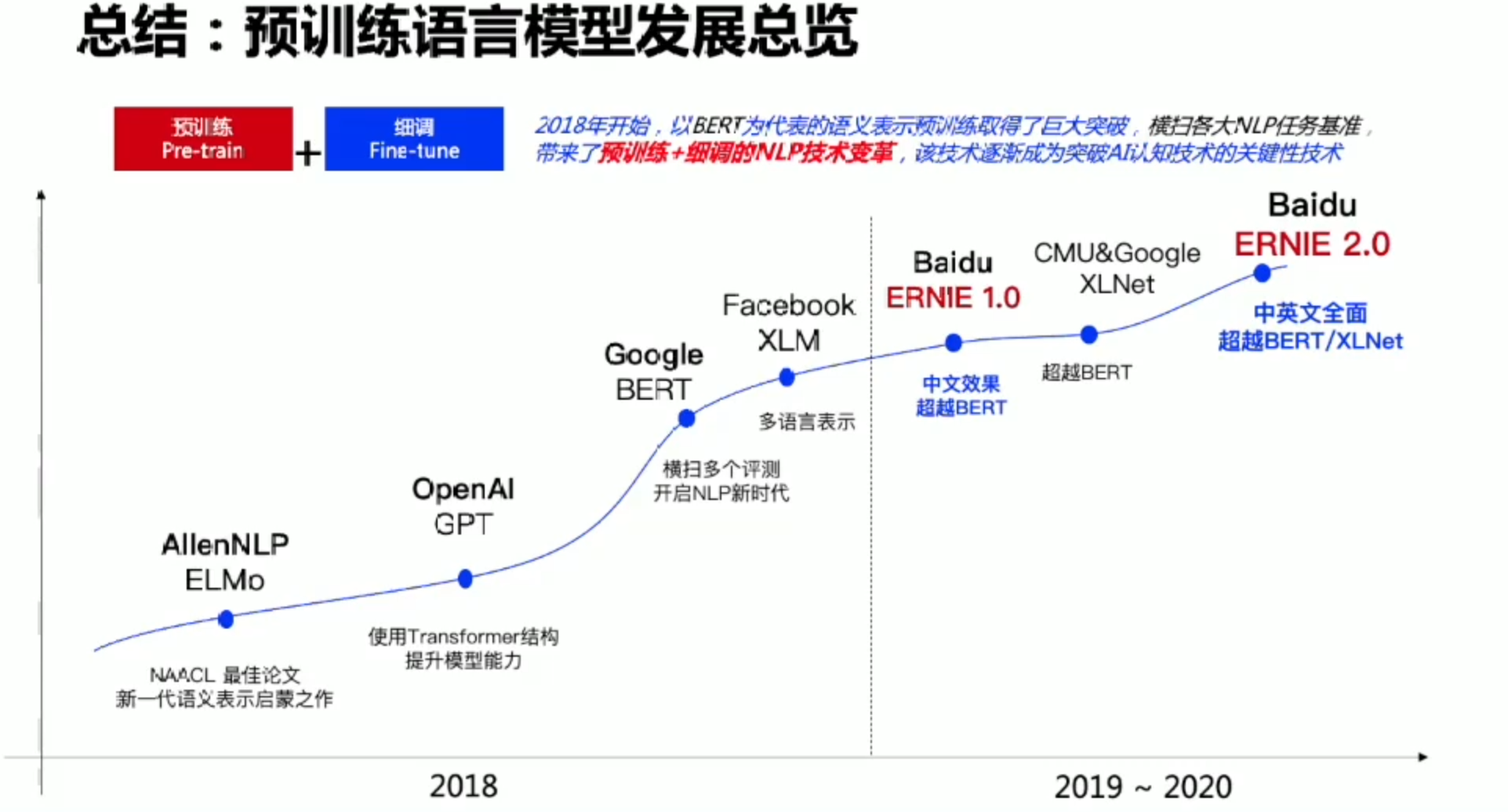
预训练语言模型
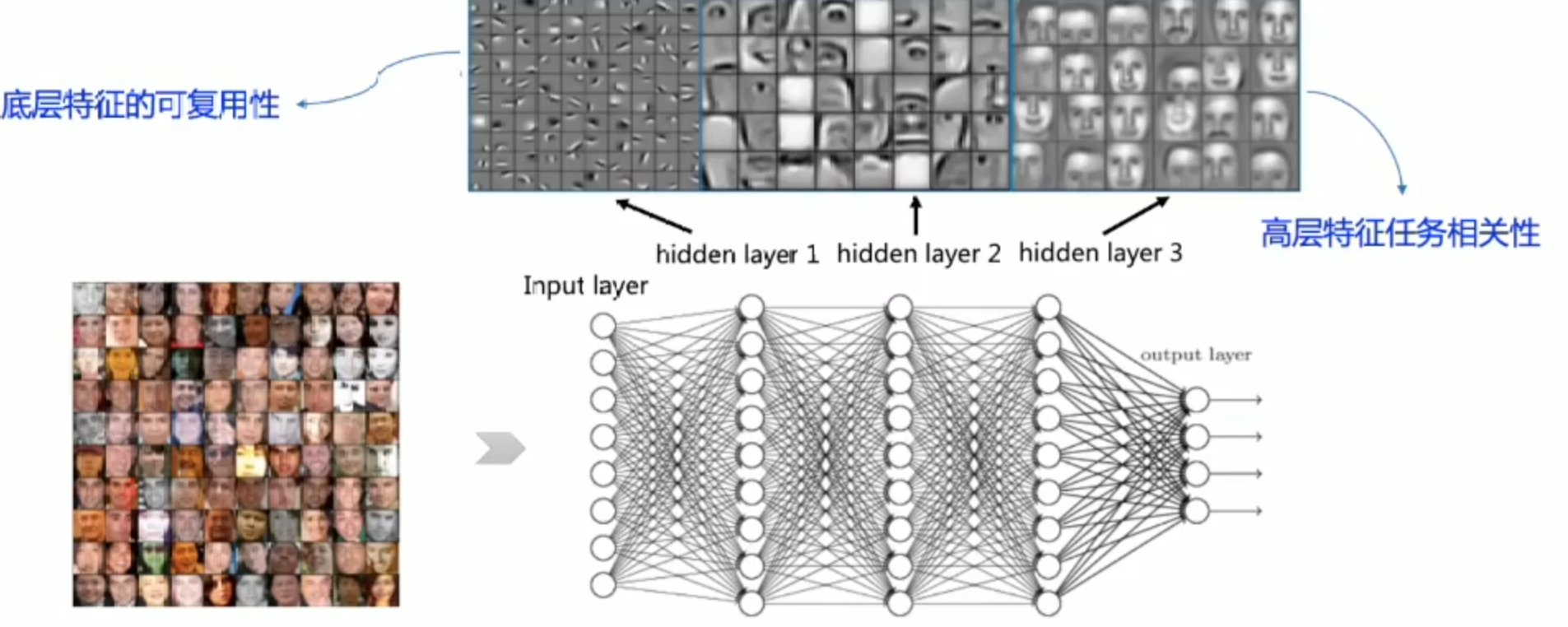
无论是Word2Vec还是序列编码网络,他们所获取的词向量都是与任务无关(只与他需要的几个词有关)
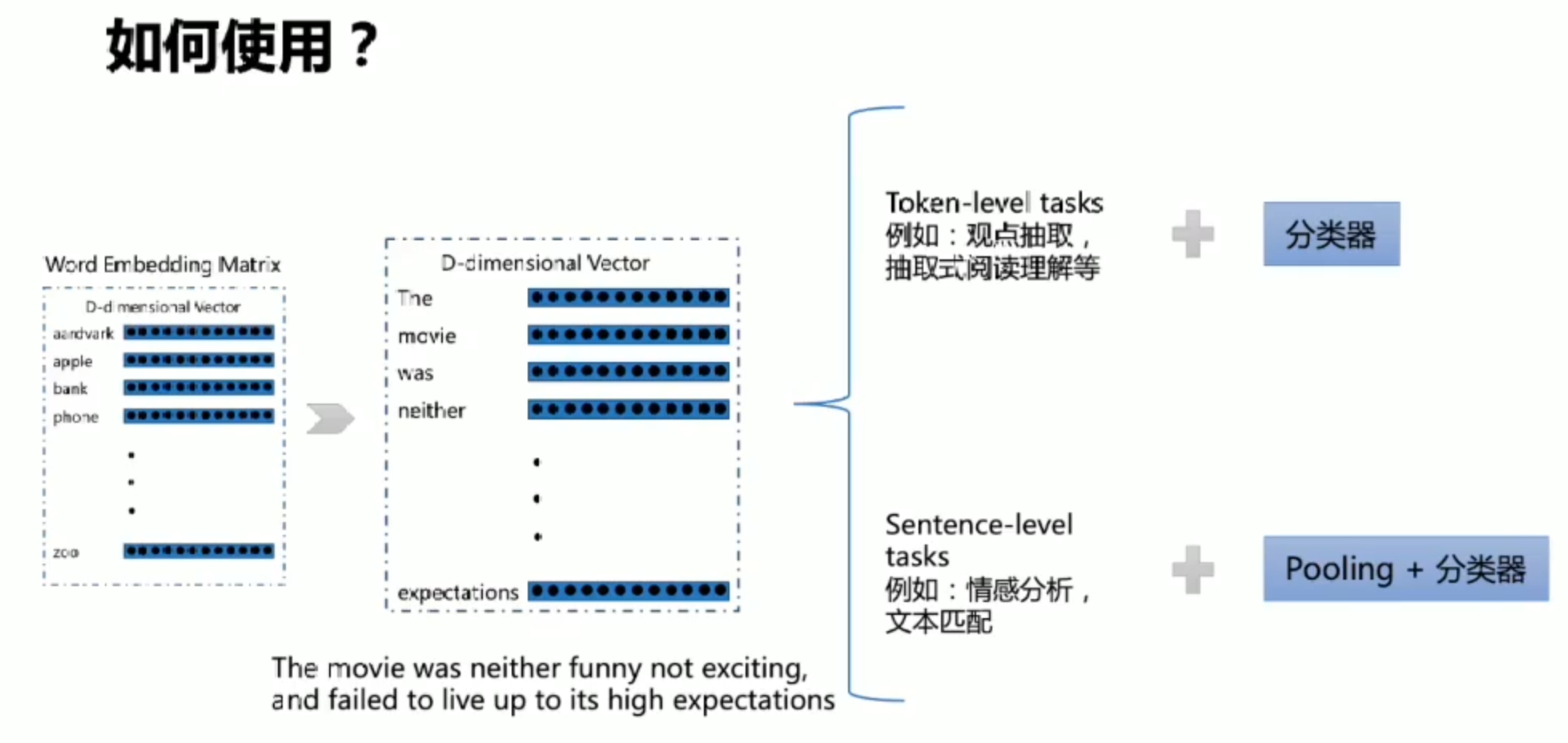
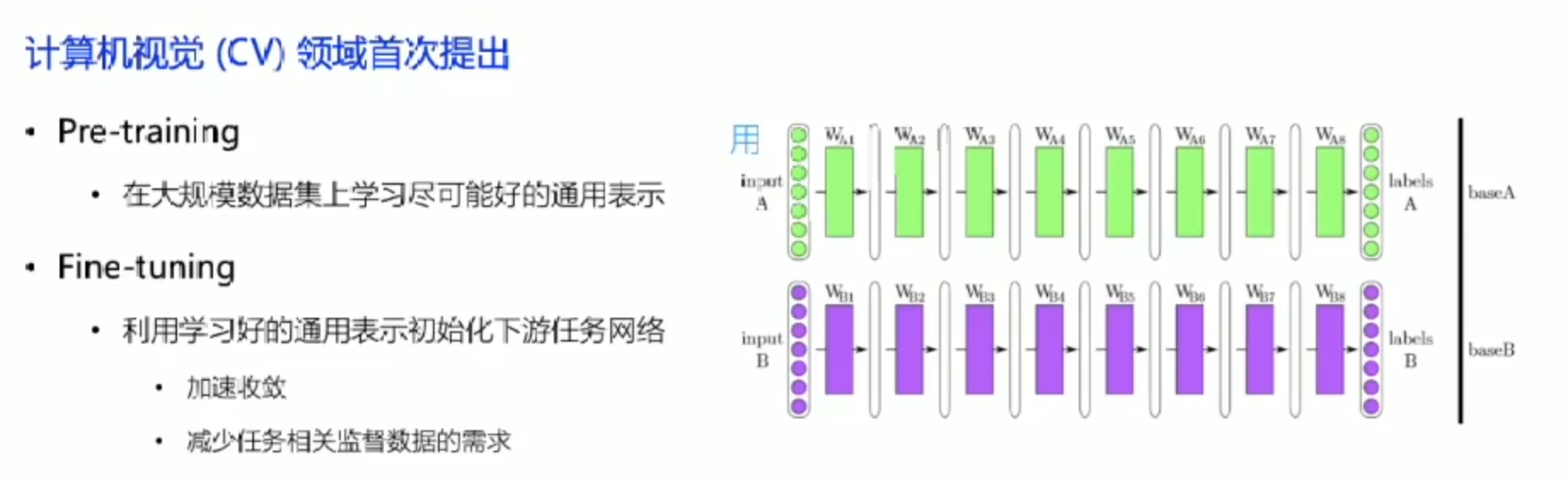
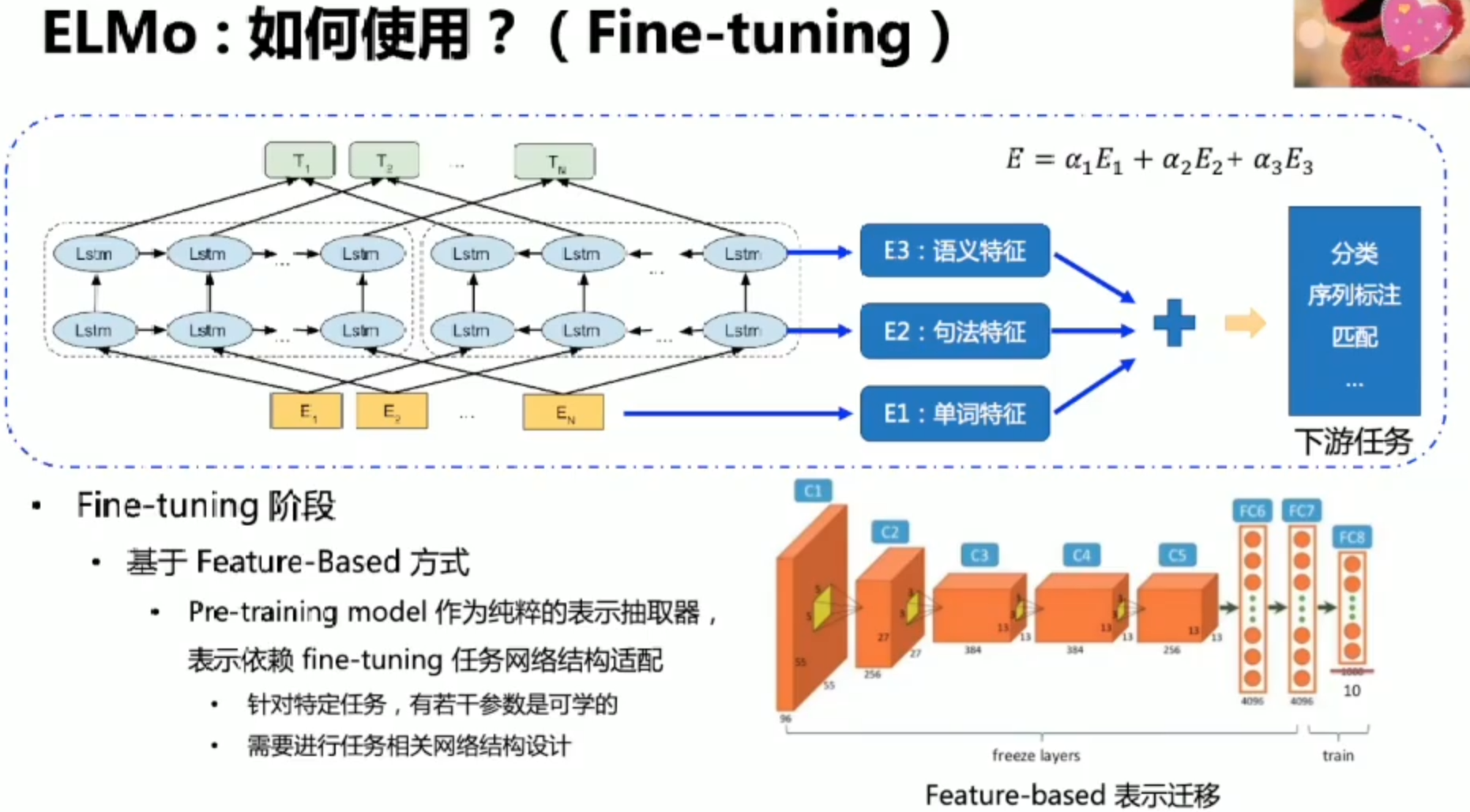
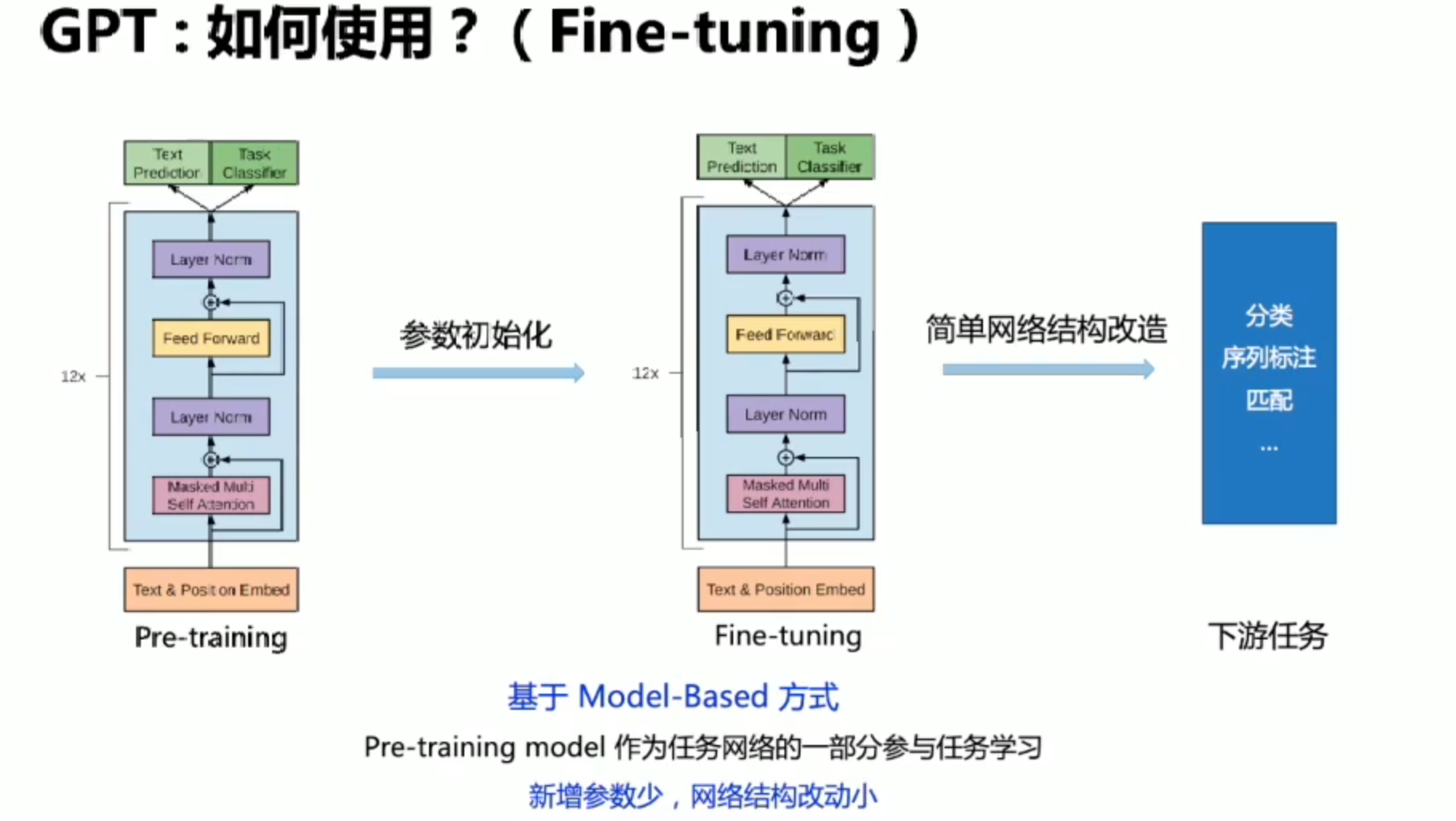
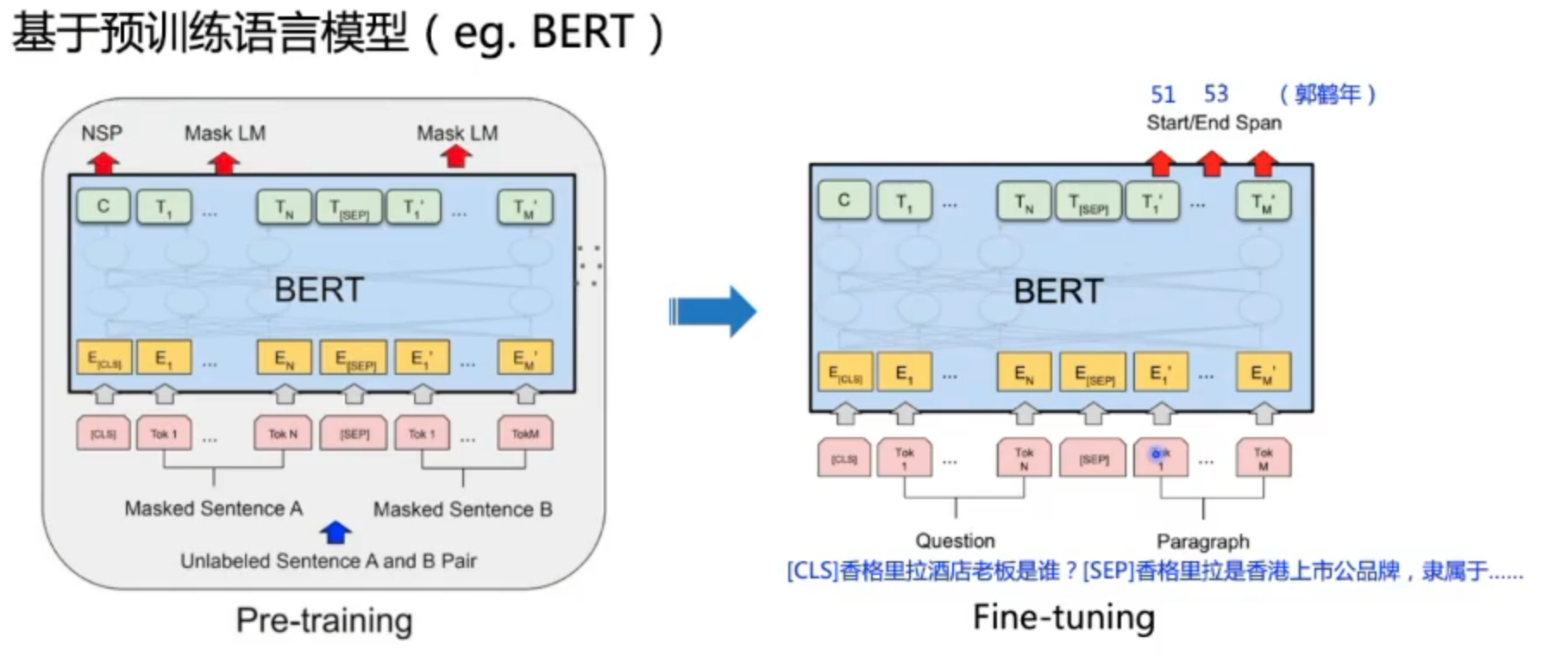
Pre-Training & Fine-tuning

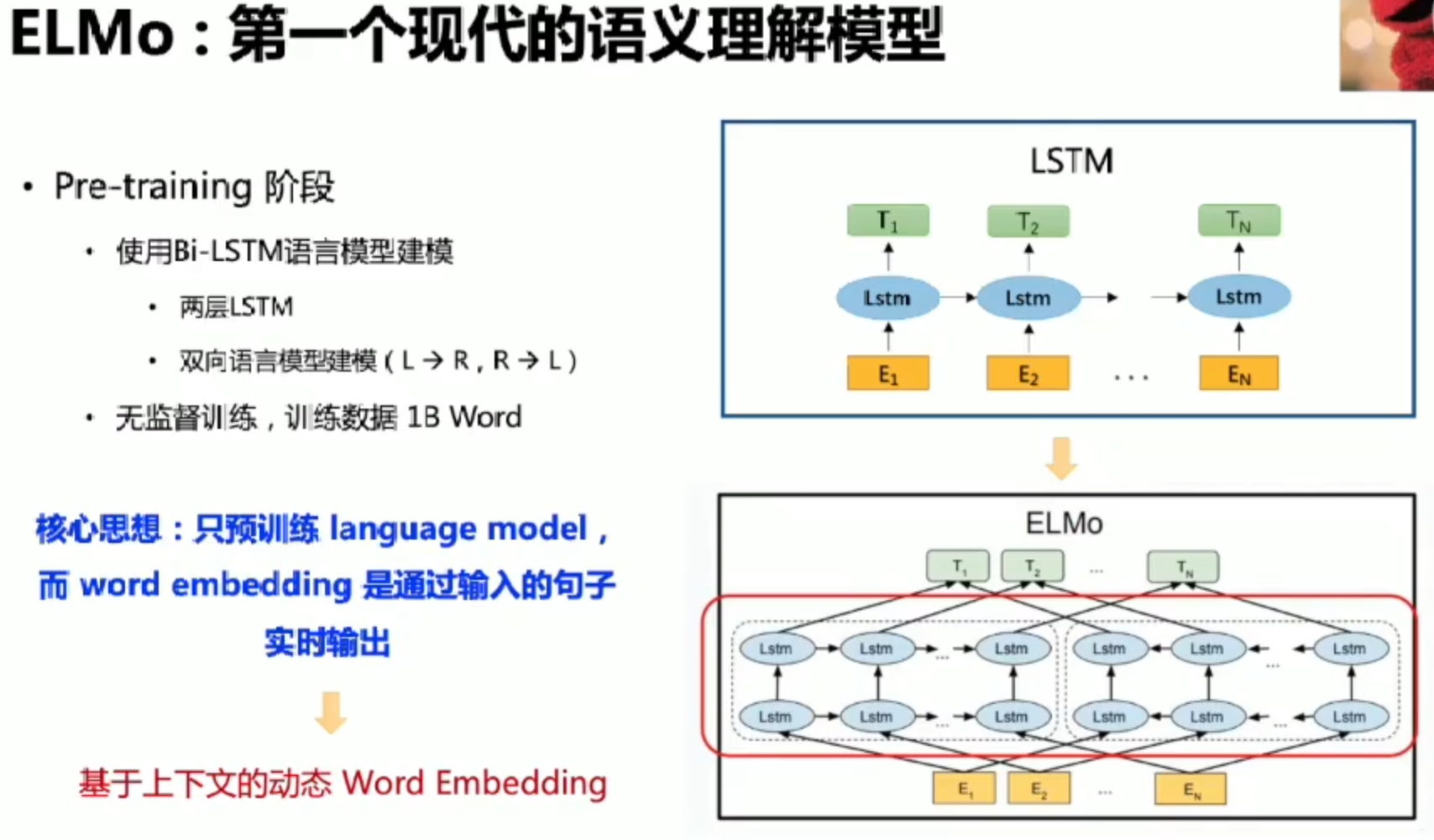
ElMo:语义理解模型
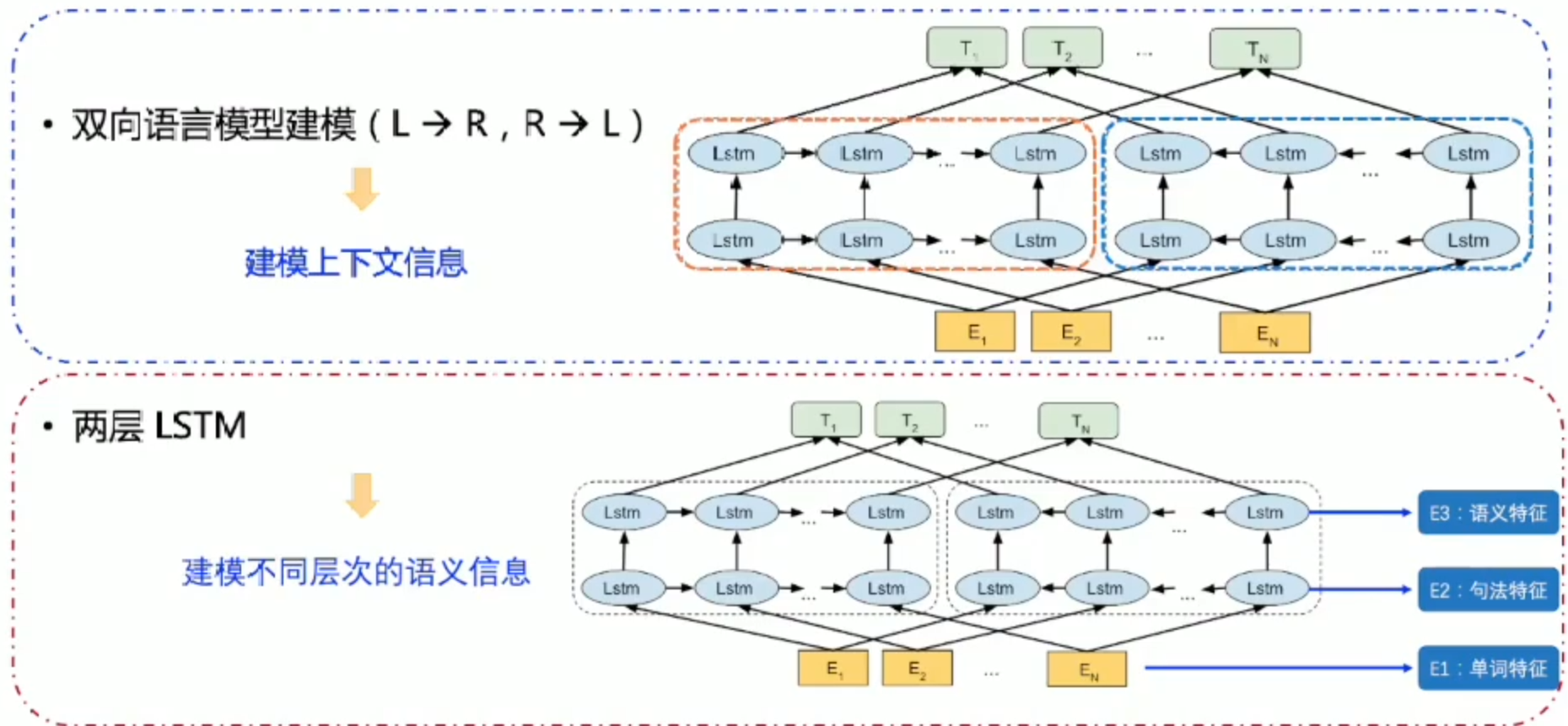
策略
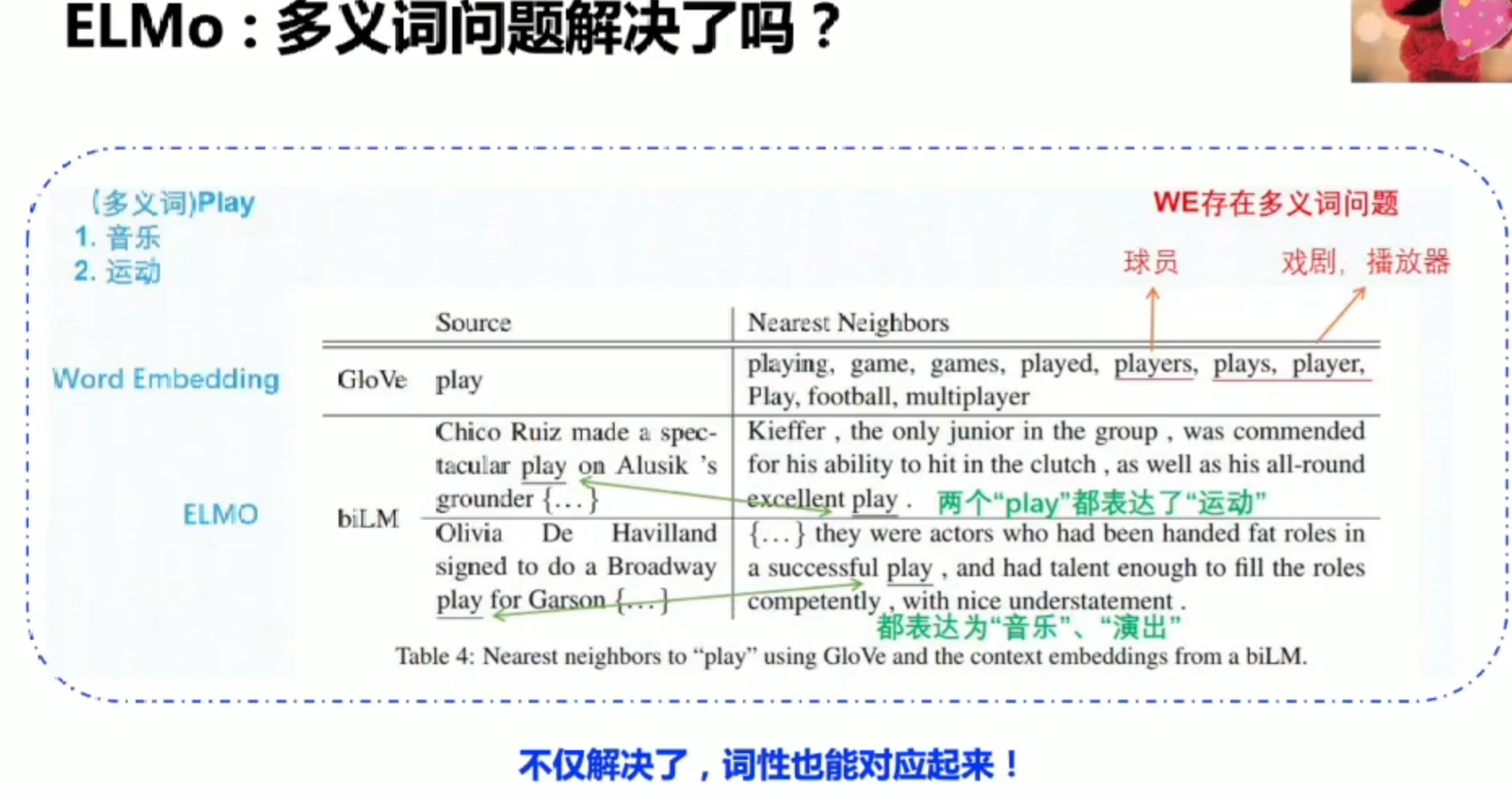
缺点

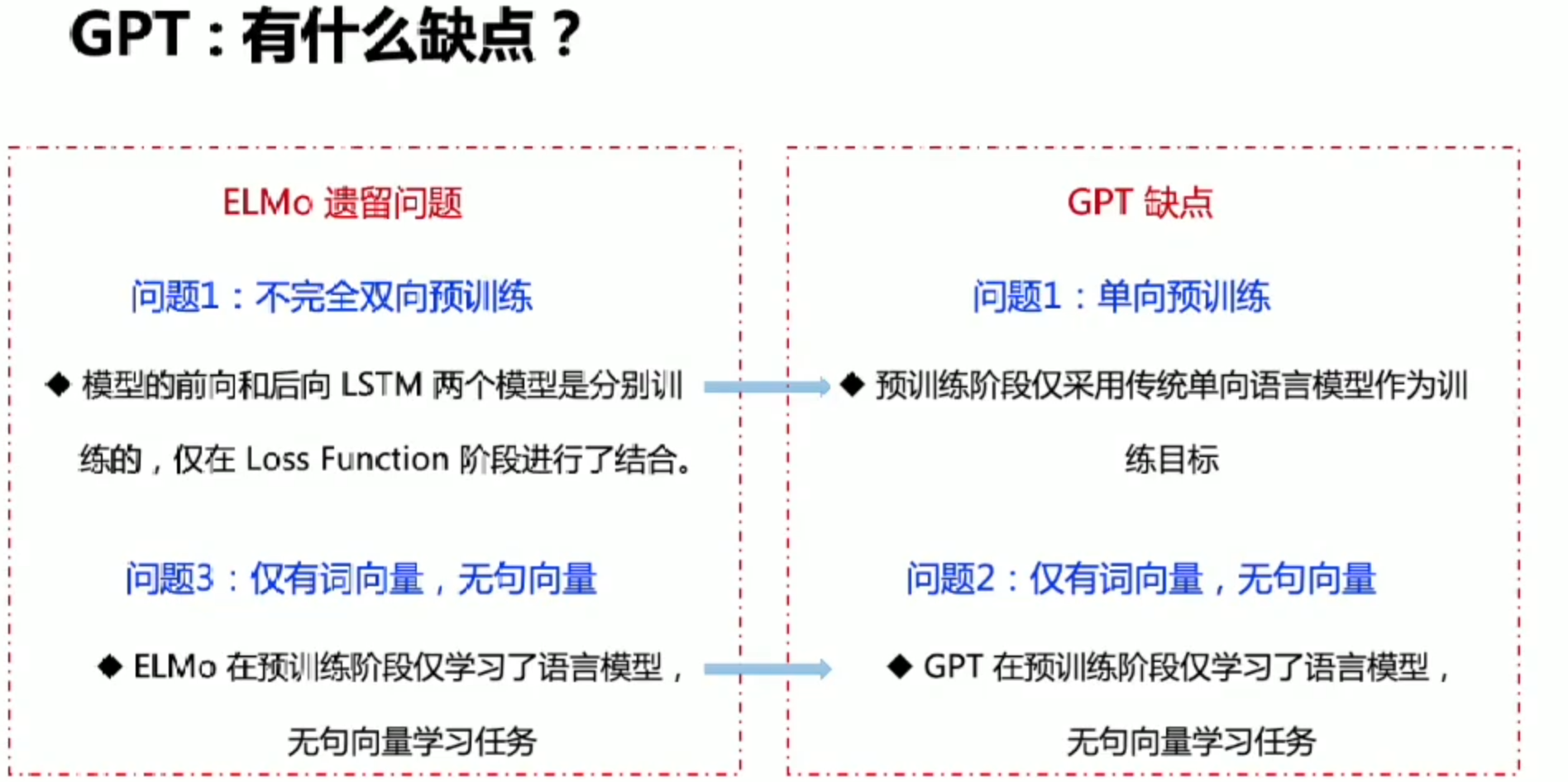
GPT:Bert之前的工作
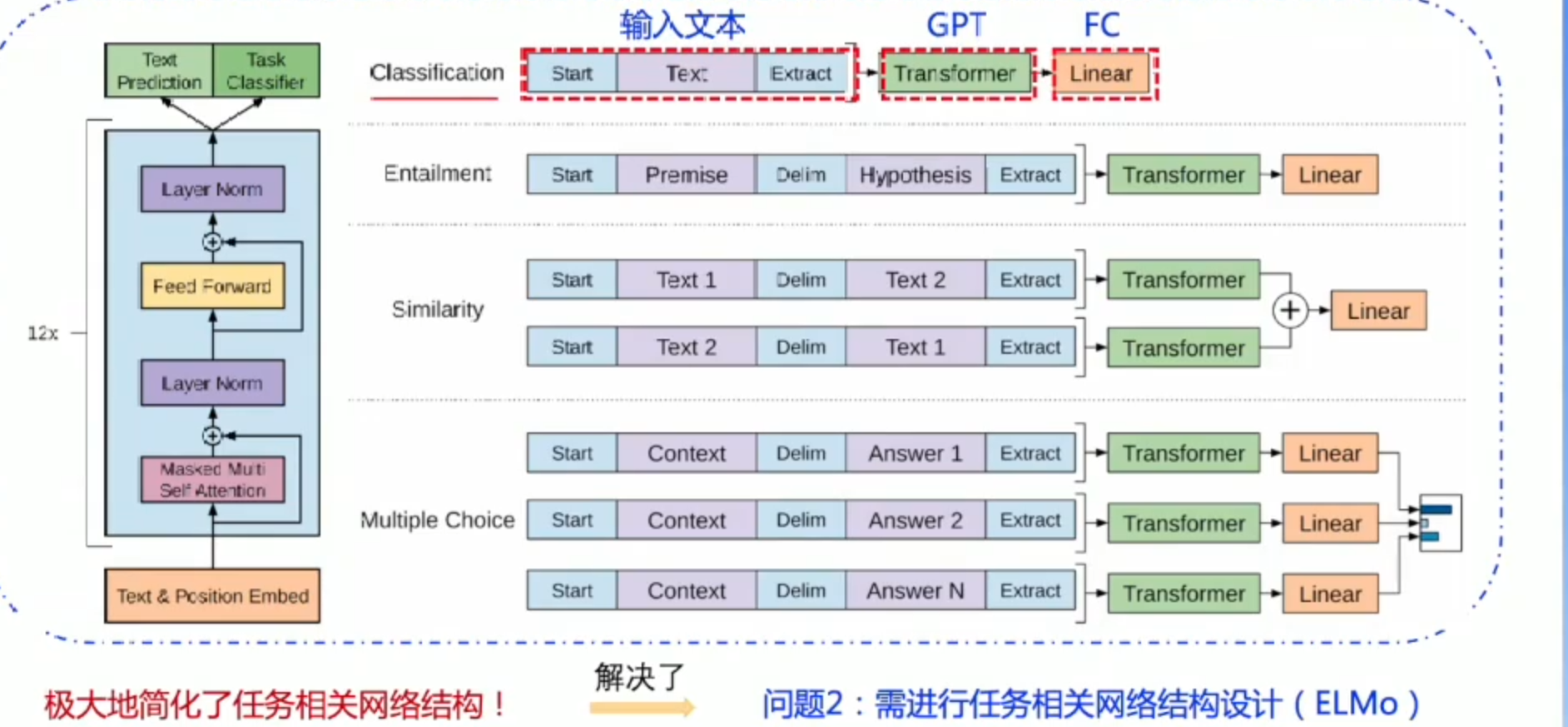
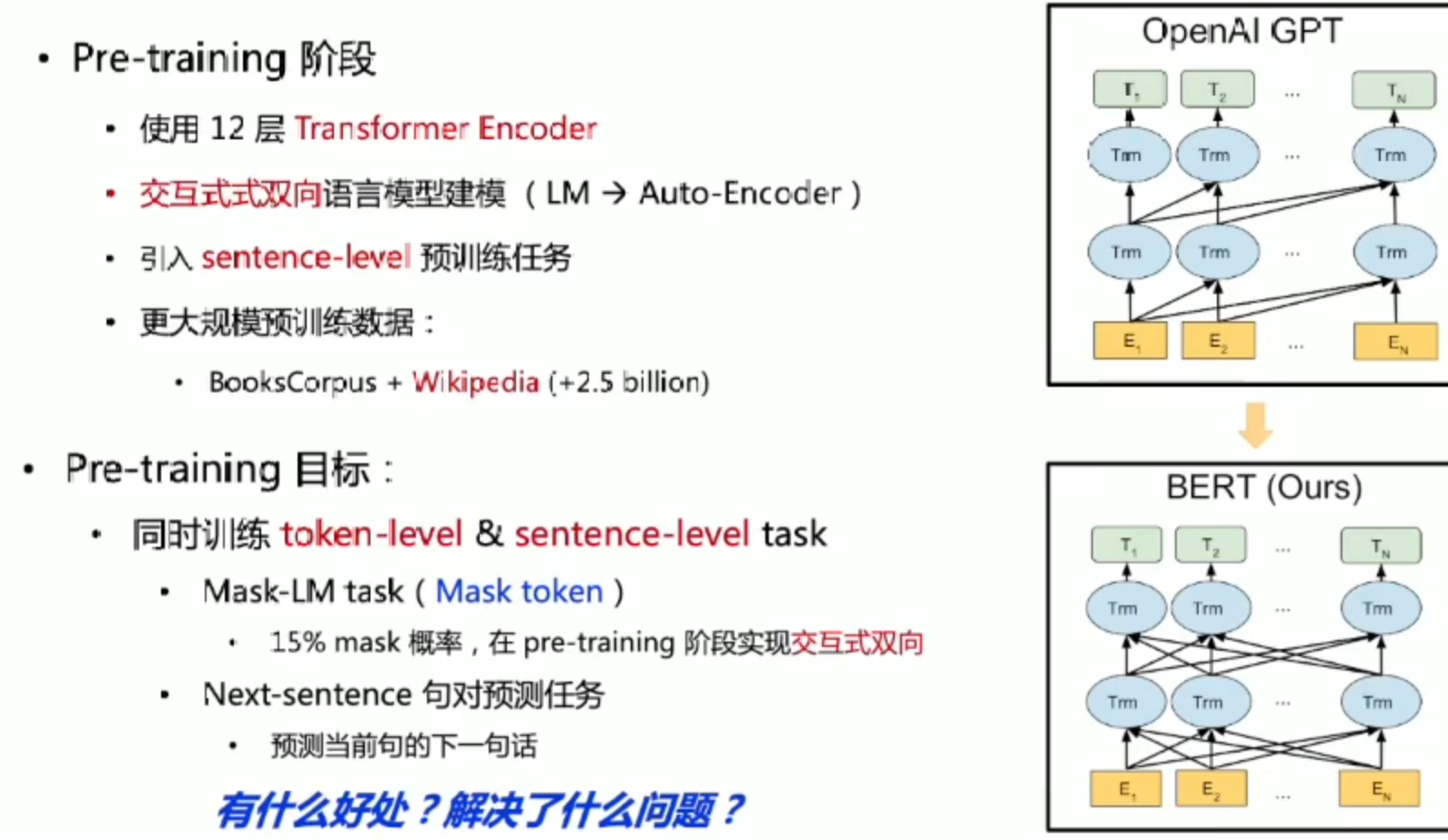
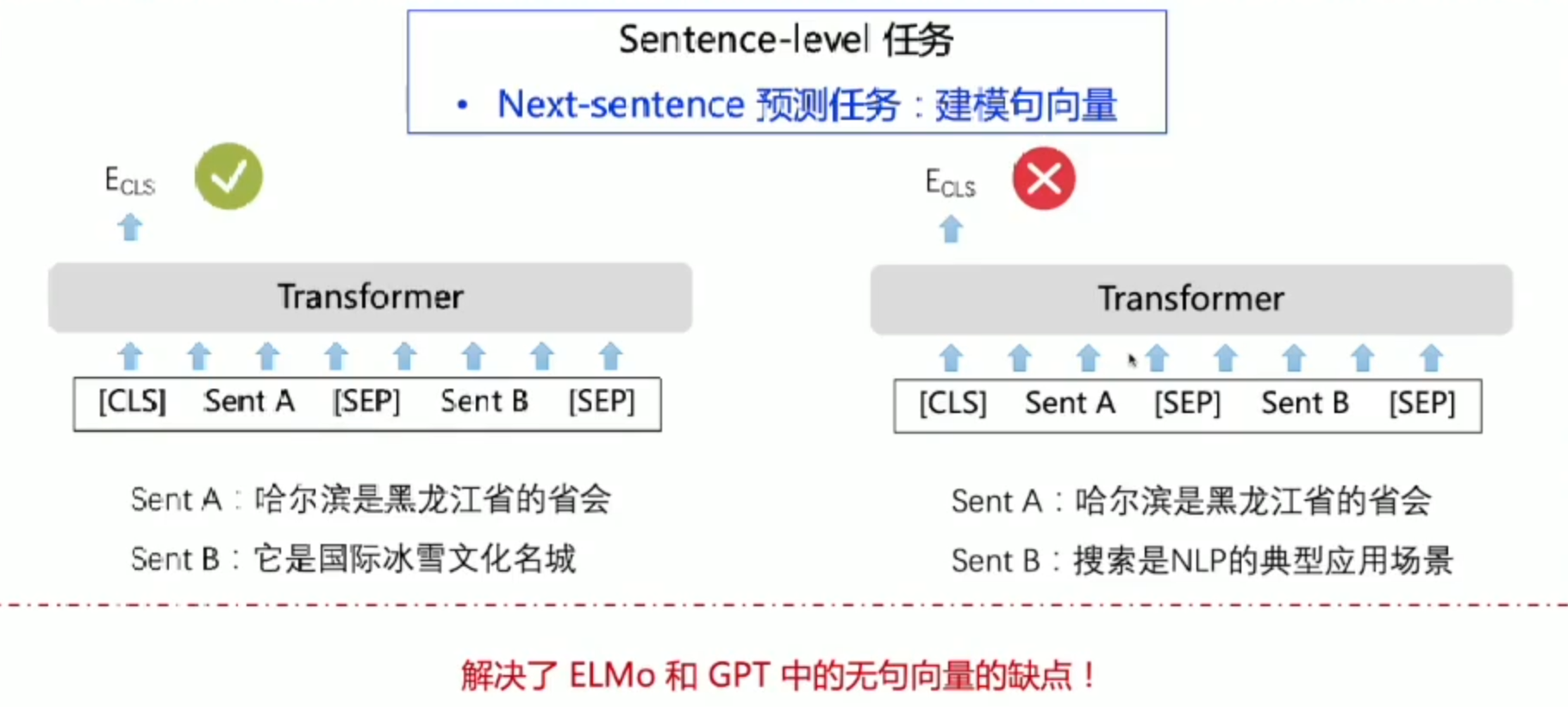
Bert: 预训练里程碑式突破
策略分析


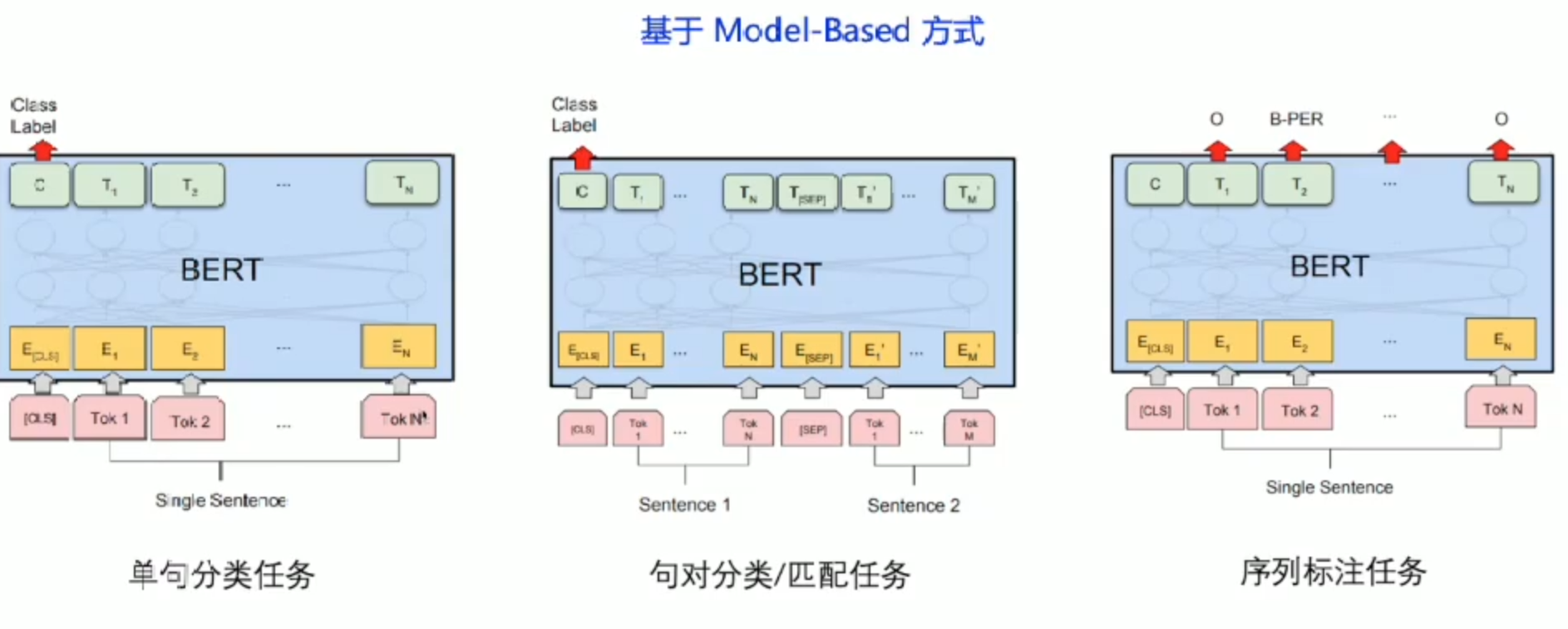
缺点

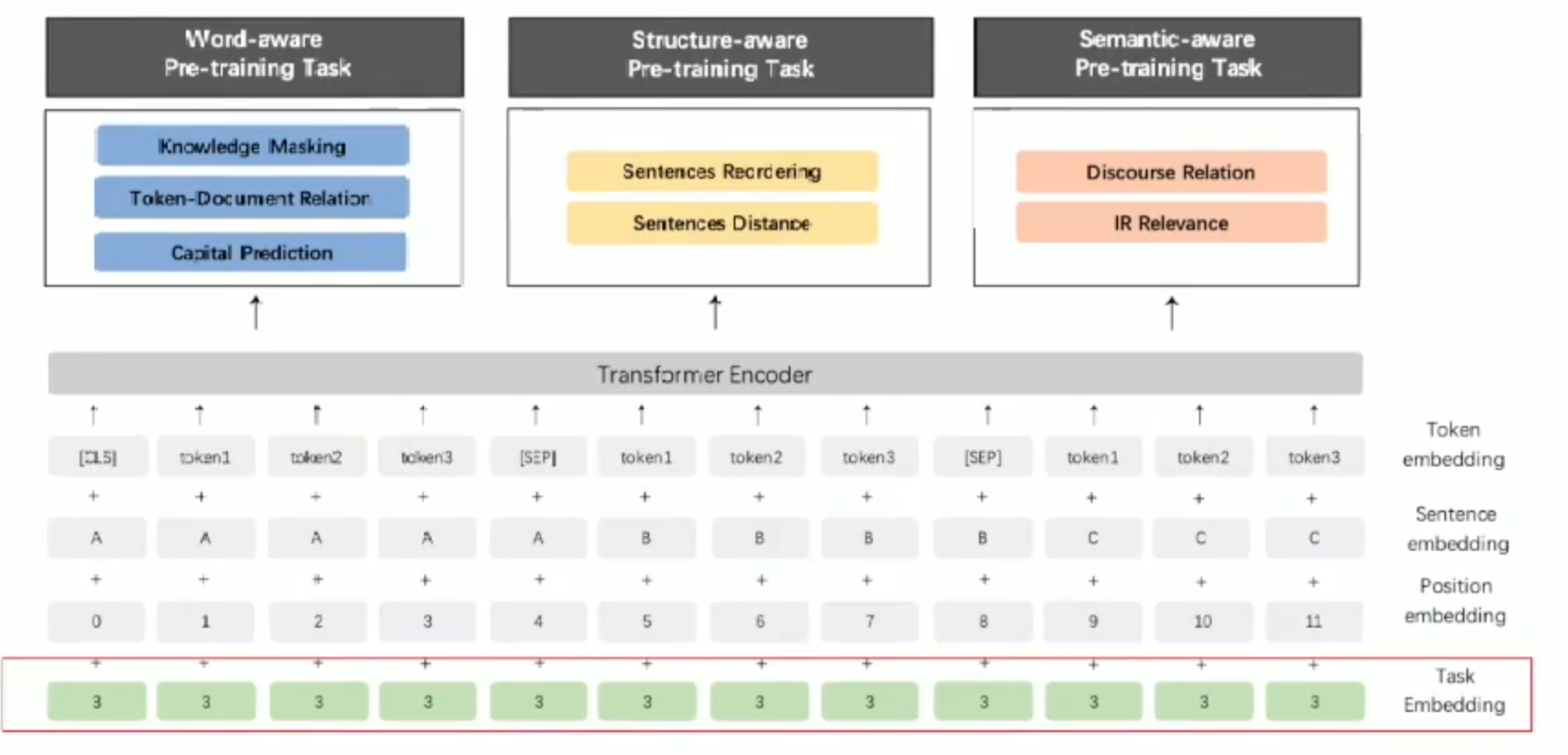
ERNIE
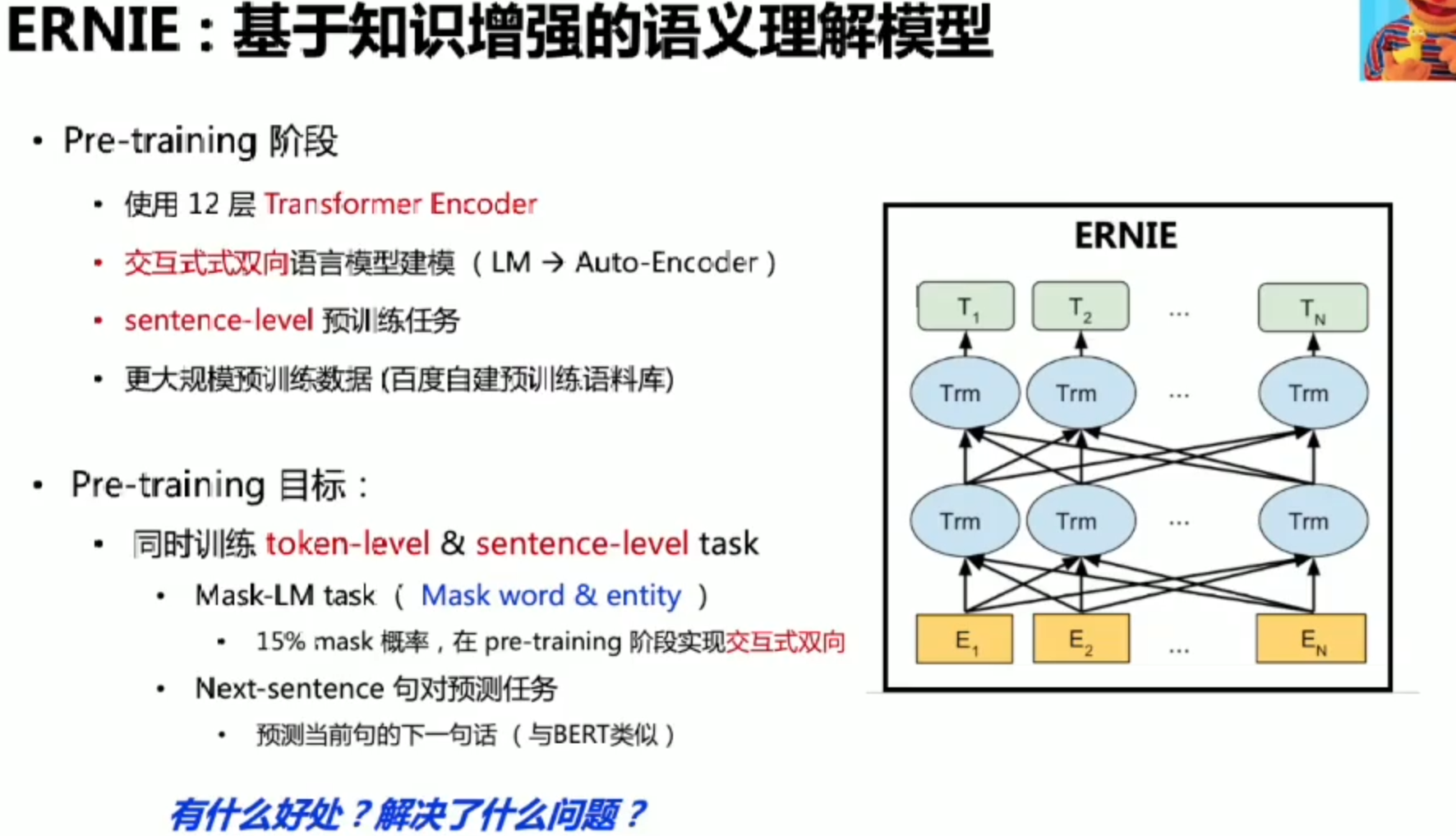
策略分析



ERNIE2.0
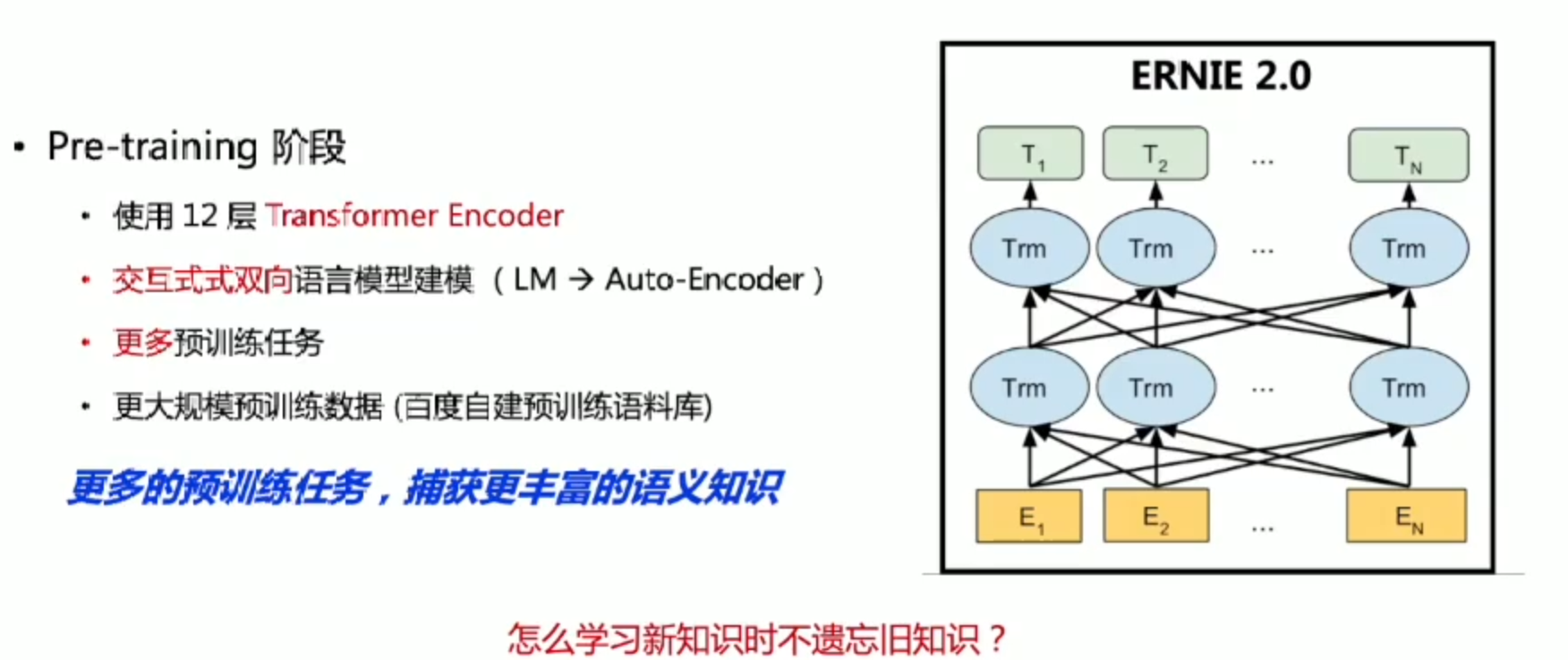
持续学习框架
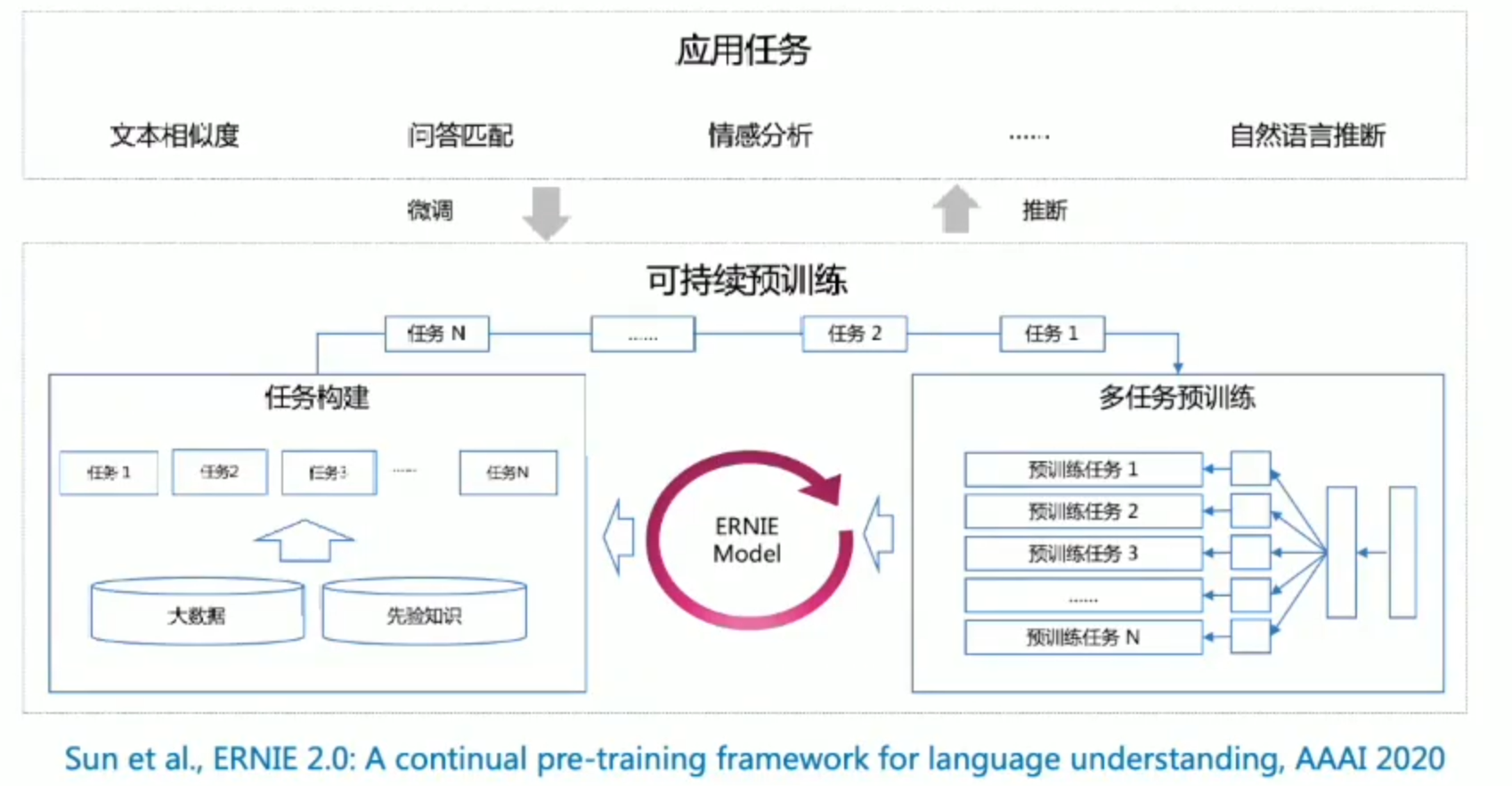
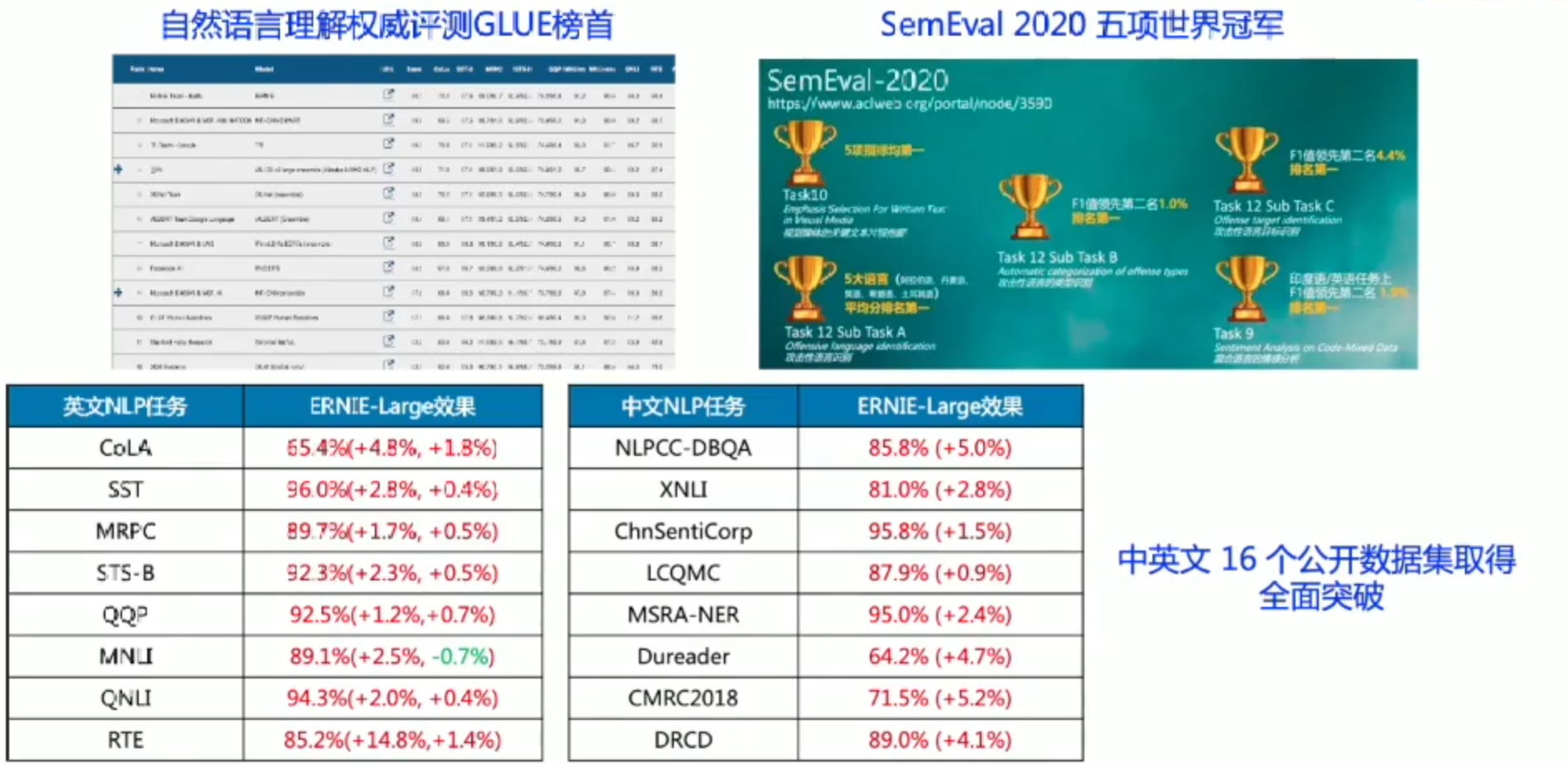
预训练模型优势

文本匹配
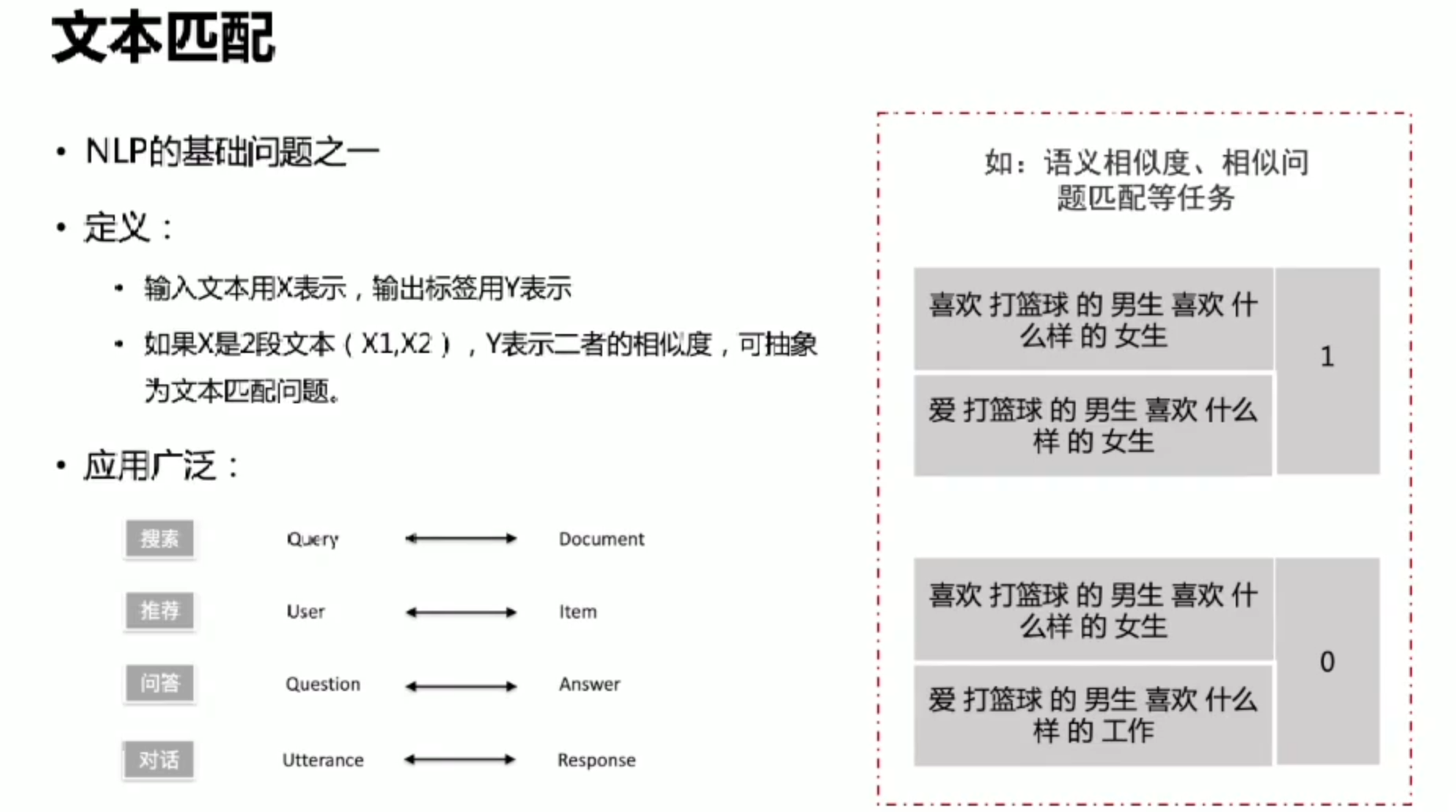
难点
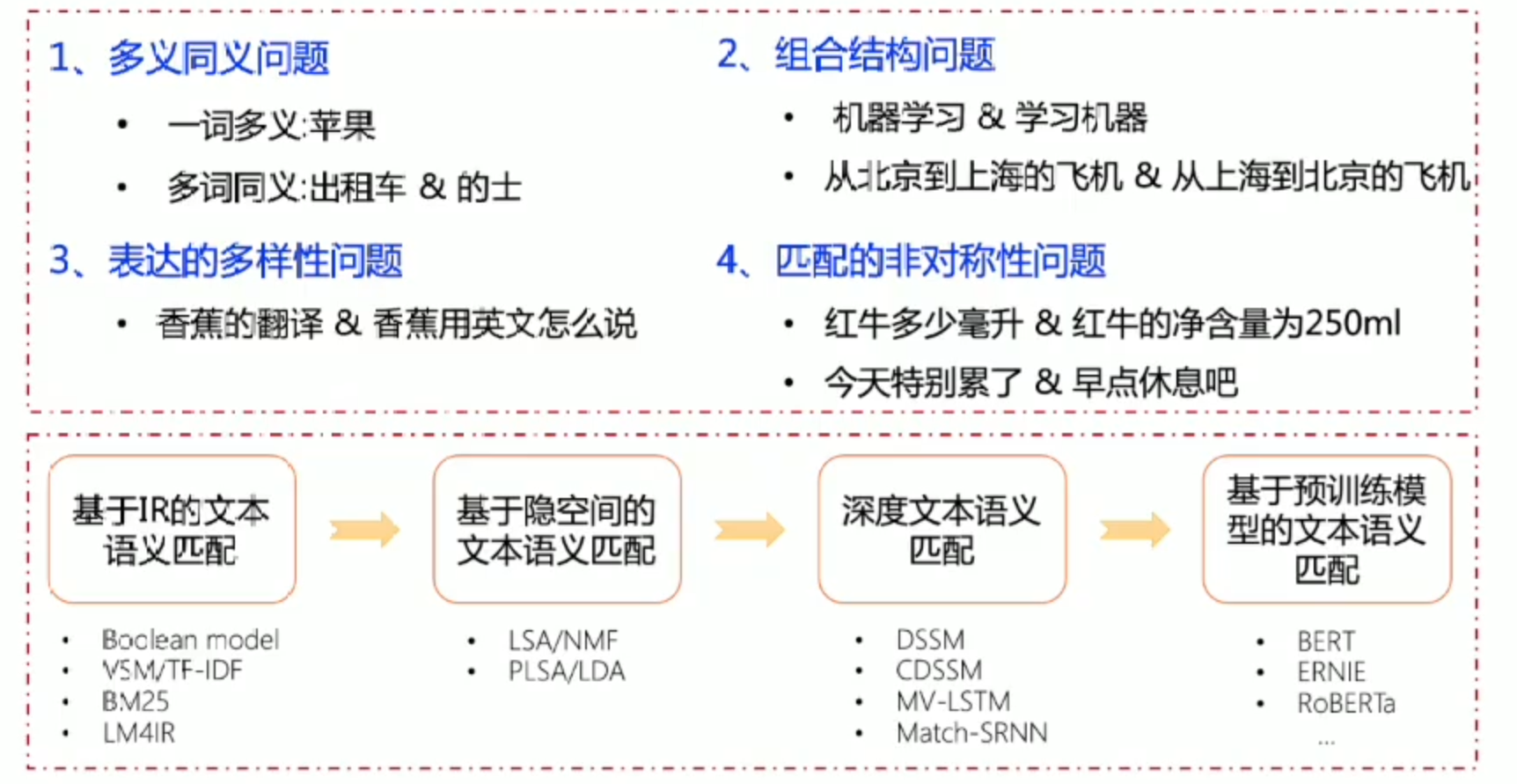
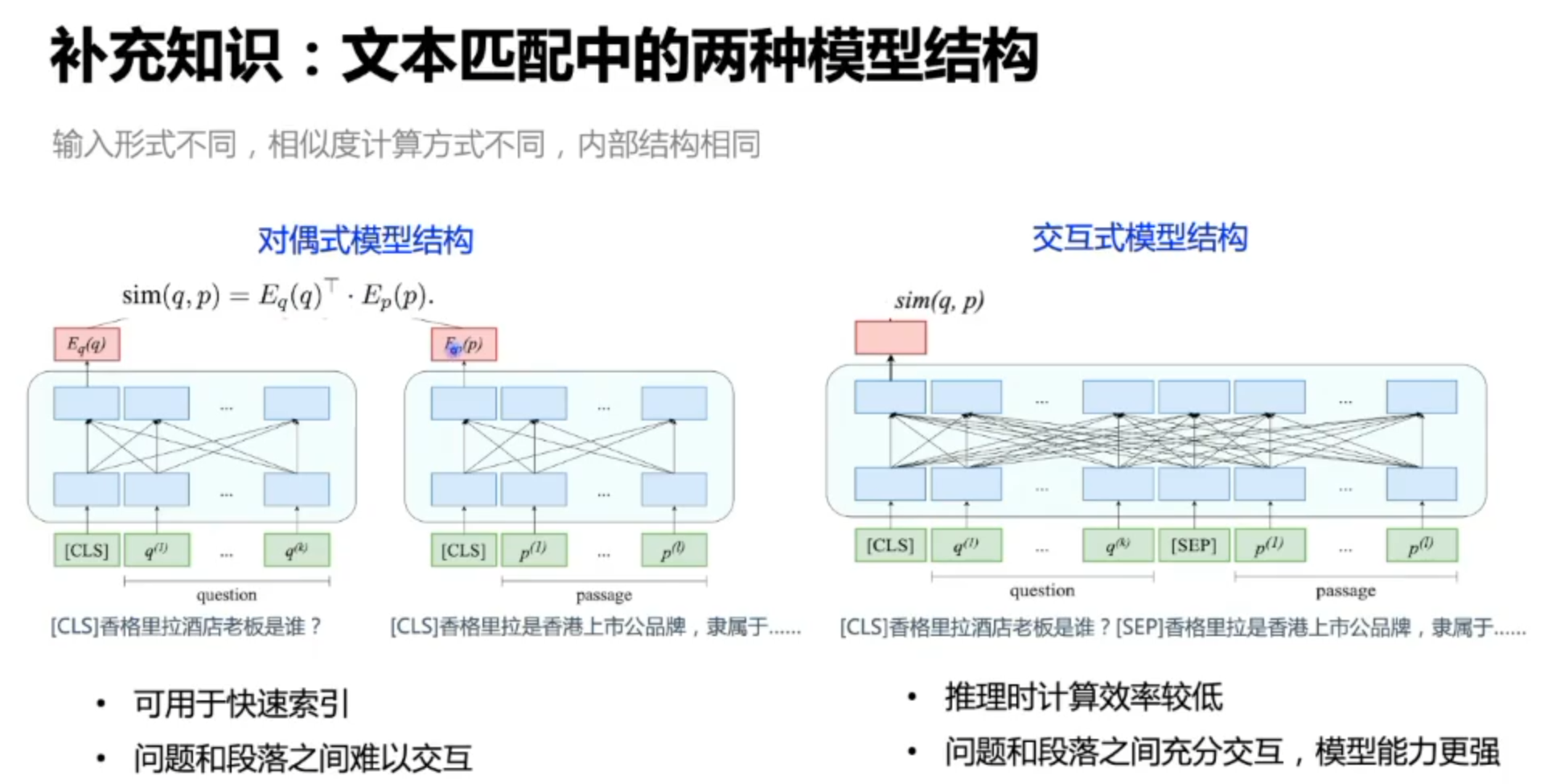
基于预训练的文本匹配
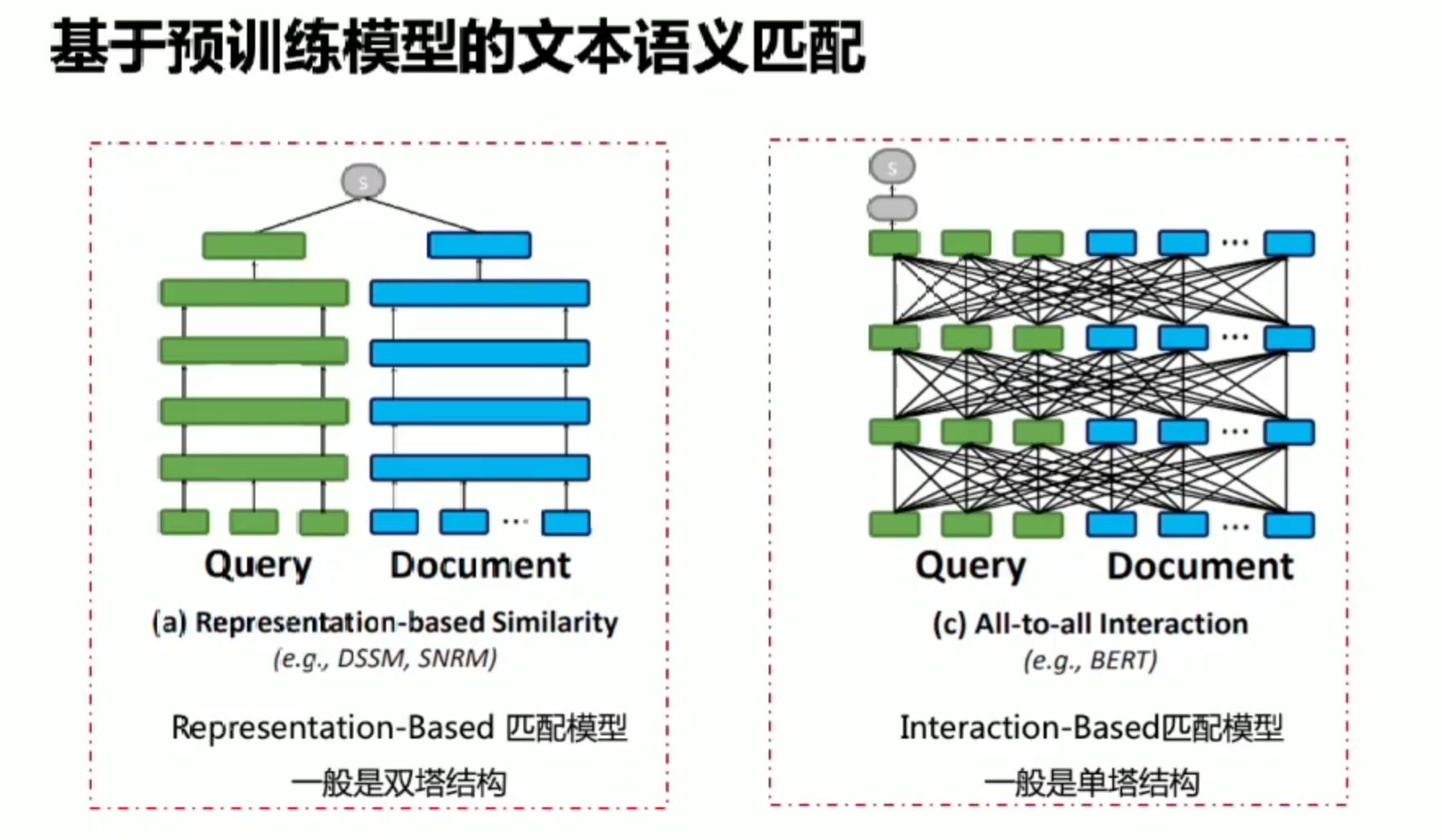
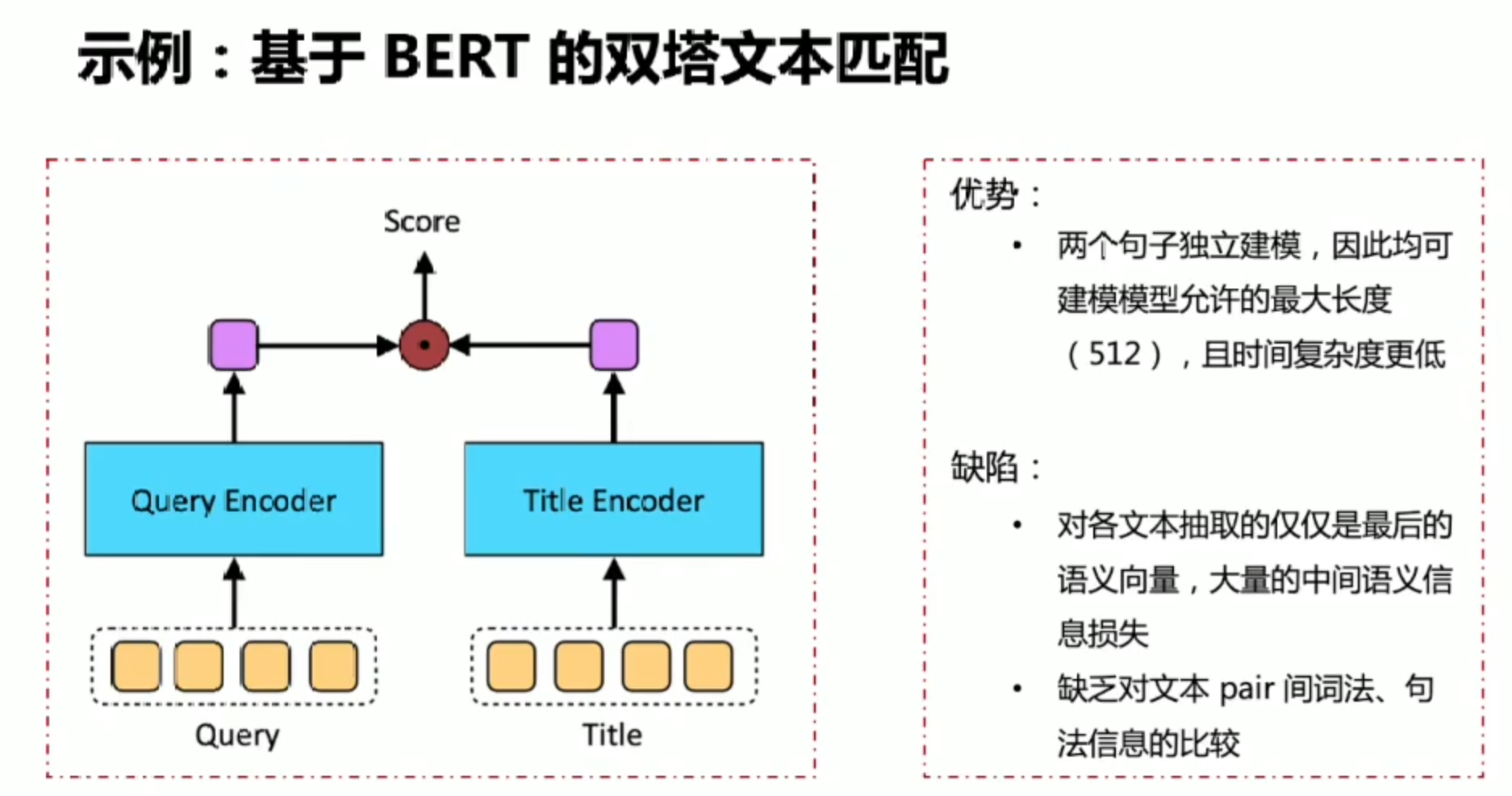
文本长用双塔
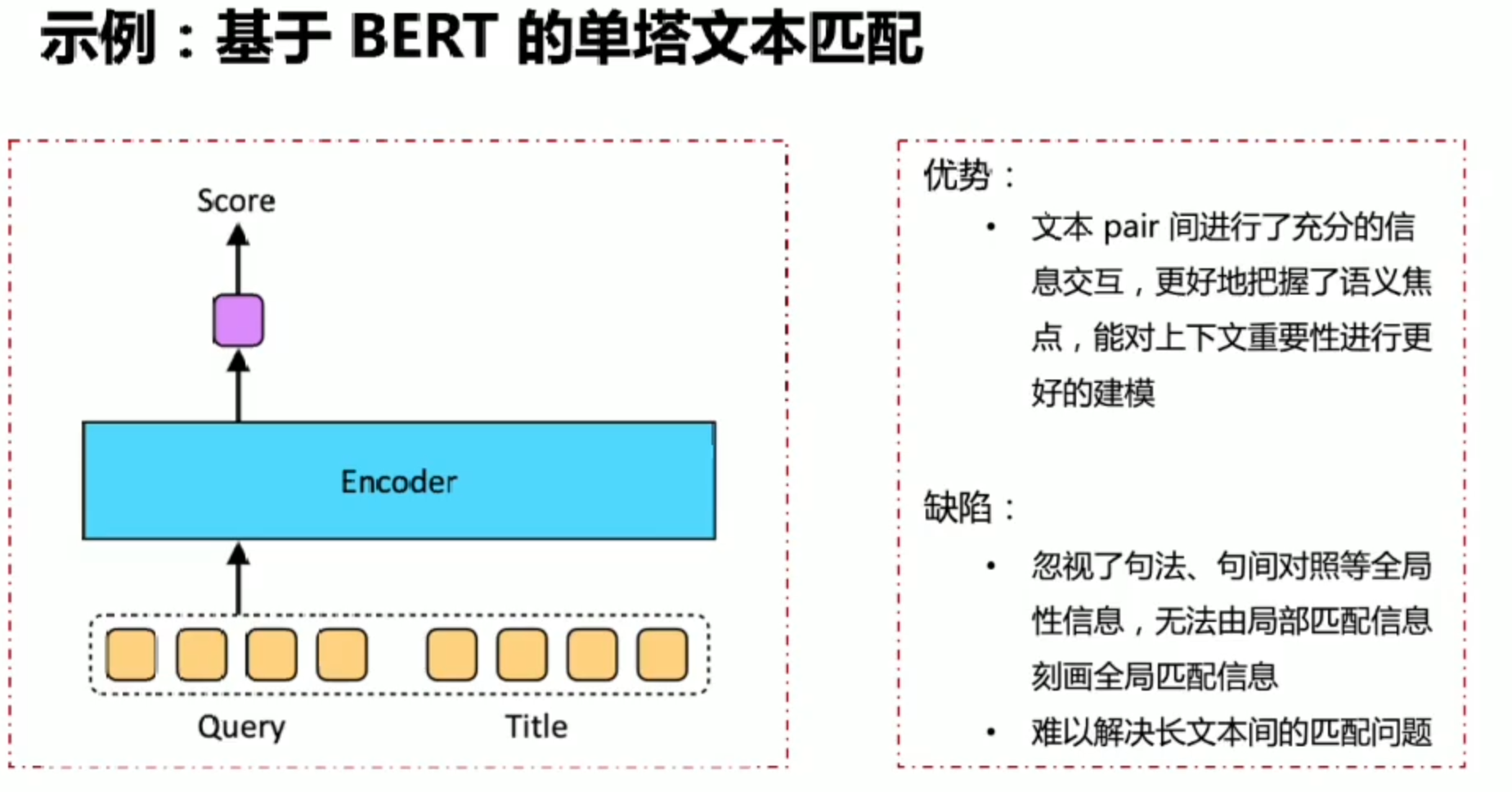
文本短于512建议单塔(更充分的信息交互)
文本相似度计算
数据集
若title与query相似,label为1,反之为0
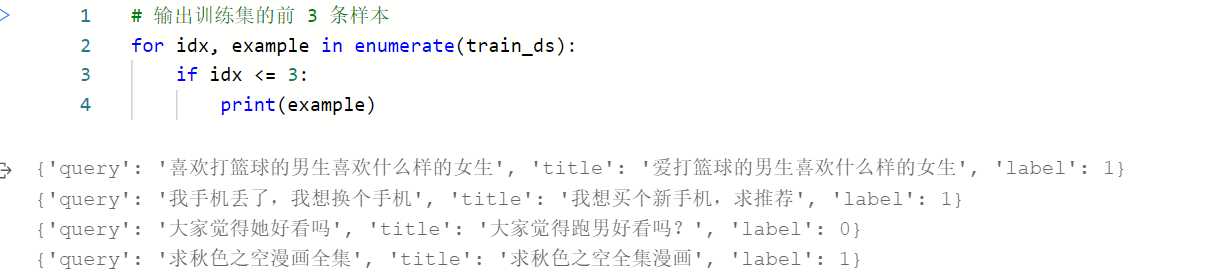
每一个token对应一个输出,Segment对应是这是第几个句子,Position就是给位置进行编码,最后把三个Embedding层信息进行相加,即可得到最终输出
[SEP] 句子末尾结束符号, [CLS]句子开始符号
载入Tokenizer

1 | # 将 1 条明文数据的 query、title 拼接起来,根据预训练模型的 tokenizer 将明文转换为 ID 数据 |
下面是对第一条句子数据进行转换



input_ids的1就代表CLS(起始符),2可能就代表SEP(句断符)
为何要做偏函数呢?
我们可能要对几万条数据做同样的处理,可能有许多东西都是一样的,我们这里就是将tokenizer和max_seq_length给固定掉,然后对一个batch 一个batch的传数据就行。给这样一个函数起名为trans_func,这只是把函数进行了封装。
数据Padding
PaddleNLP 提供了许多关于 NLP 任务中构建有效的数据 pipeline 的常用 API
| API | 简介 |
|---|---|
paddlenlp.data.Stack |
堆叠N个具有相同shape的输入数据来构建一个batch |
paddlenlp.data.Pad |
将长度不同的多个句子padding到统一长度,取N个输入数据中的最大长度 |
paddlenlp.data.Tuple |
将多个batchify函数包装在一起 |
更多数据处理操作详见: https://paddlenlp.readthedocs.io/zh/latest/data_prepare/data_preprocess.html
用最低维度来举例,Stack就是将同样维度,同样shape(通常先pad,所以是同样维度)的一维列表外加括号组装成二维列表,Pad就是将所有一维列表的长度补齐,Tuple就是将多个函数组装集成的作用
1 | from paddlenlp.data import Stack, Pad, Tuple |
1 | Stacked Data: |
dataloader
我们处理这么多的数据,就是为了将其载入dataloader
1 | # 为了后续方便使用,我们使用python偏函数(partial)给 convert_example 赋予一些默认参数 |
1 | # 定义分布式 Sampler: 自动对训练数据进行切分,支持多卡并行训练 |
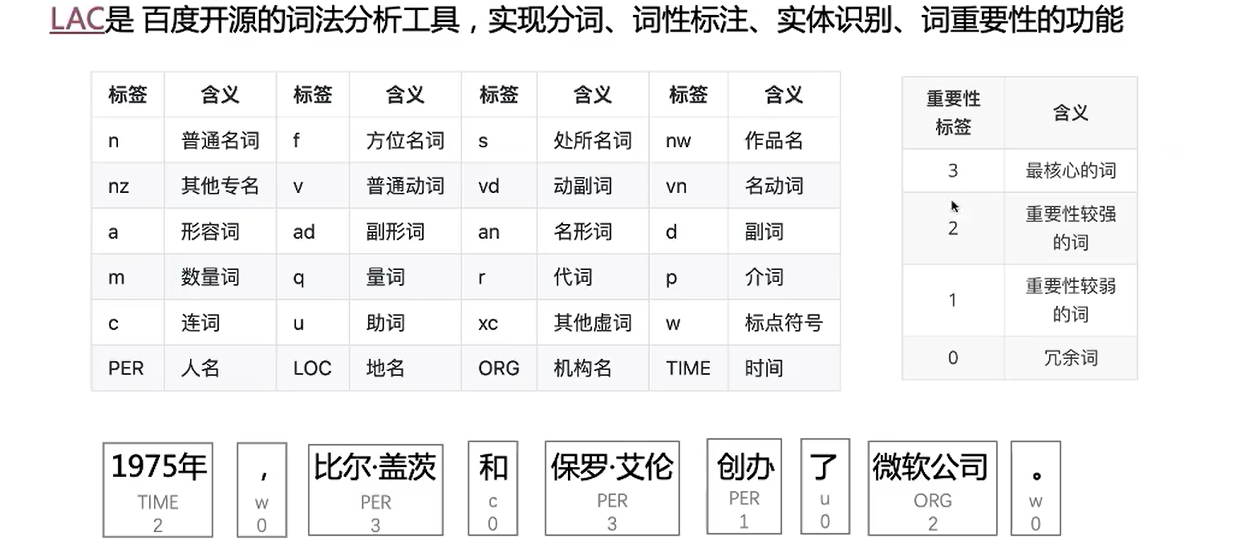
词法分析应用
概念

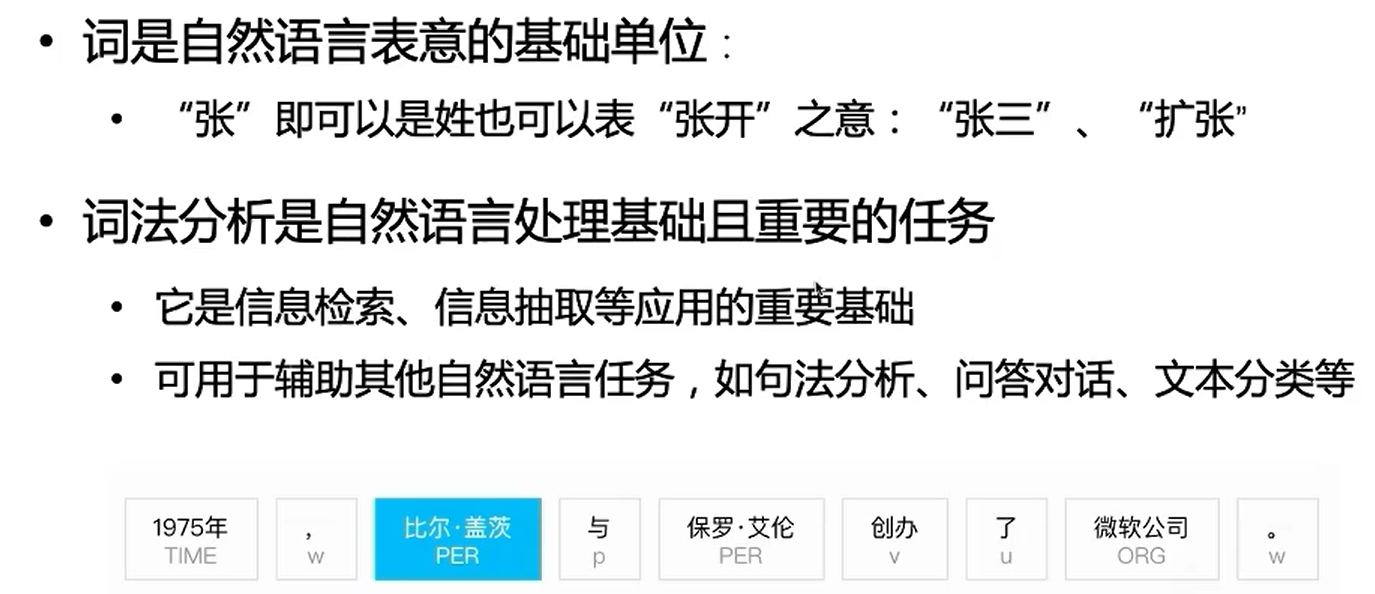
用户使用时,先进行分词,与网页关键词进行匹配

准确体现在:以词为基本单位,往往会更佳精准匹配到想要的内容;
召回体现在:以句子匹配,很多是没有结果的,即便有的网页和输入结果很像,但因为我们输入的有误差,因此影响召回的问题,所以我们用词进行搜索,就是准确与召回的一个均衡。
应用场景
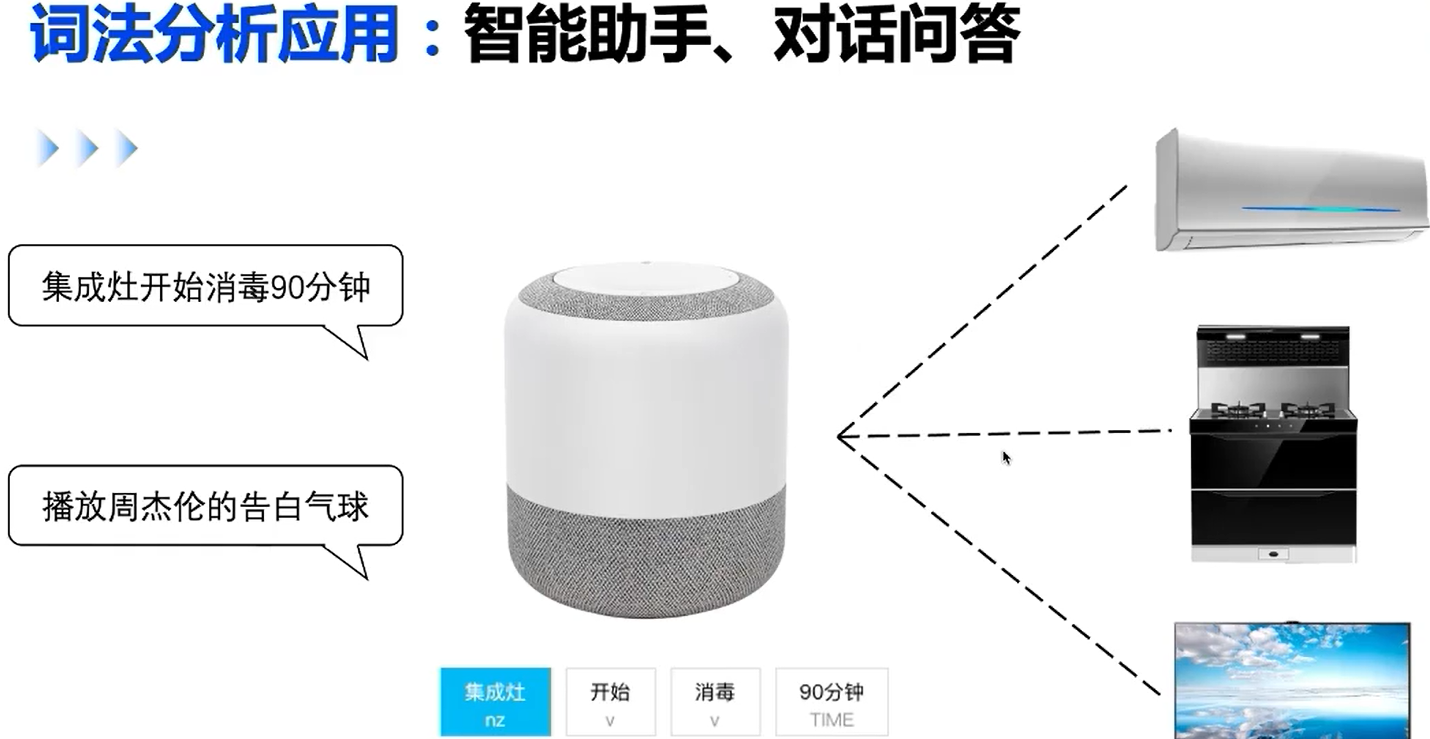
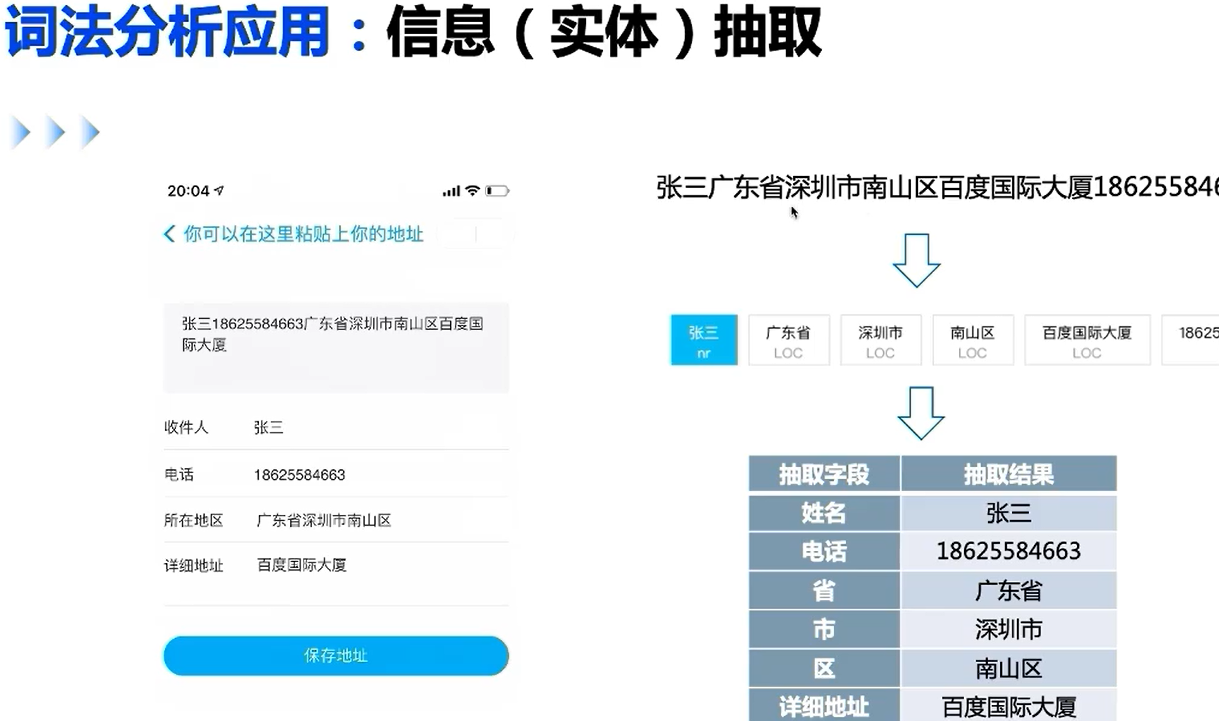
发展路线
适用于搜索量较大的

基于字符串匹配问题,引入统计语言模型
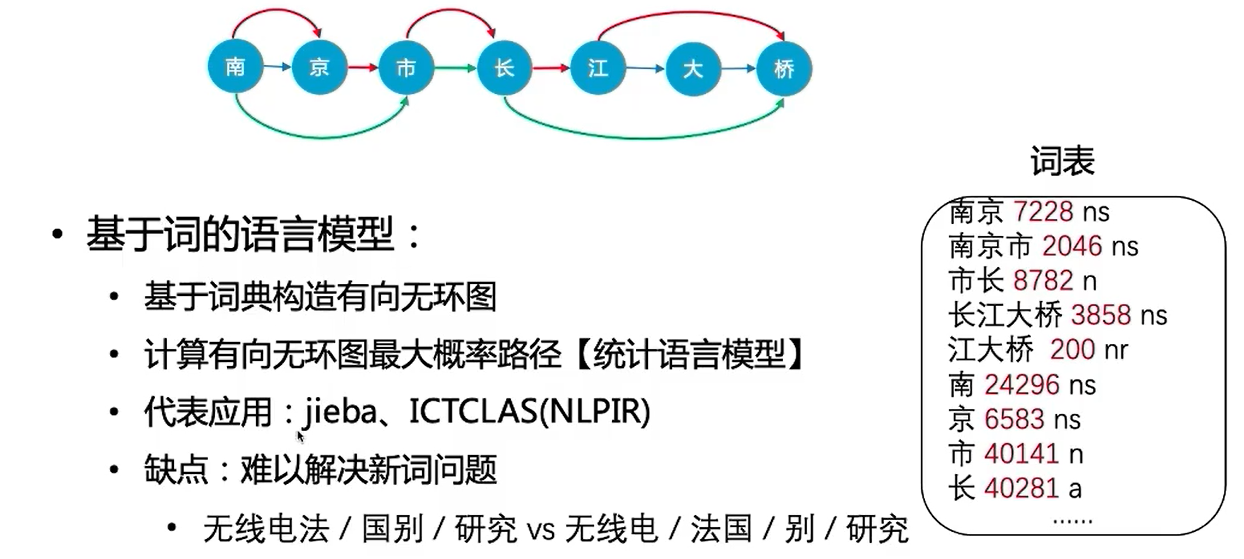
得到有效改善,但是仍然无法识别新词
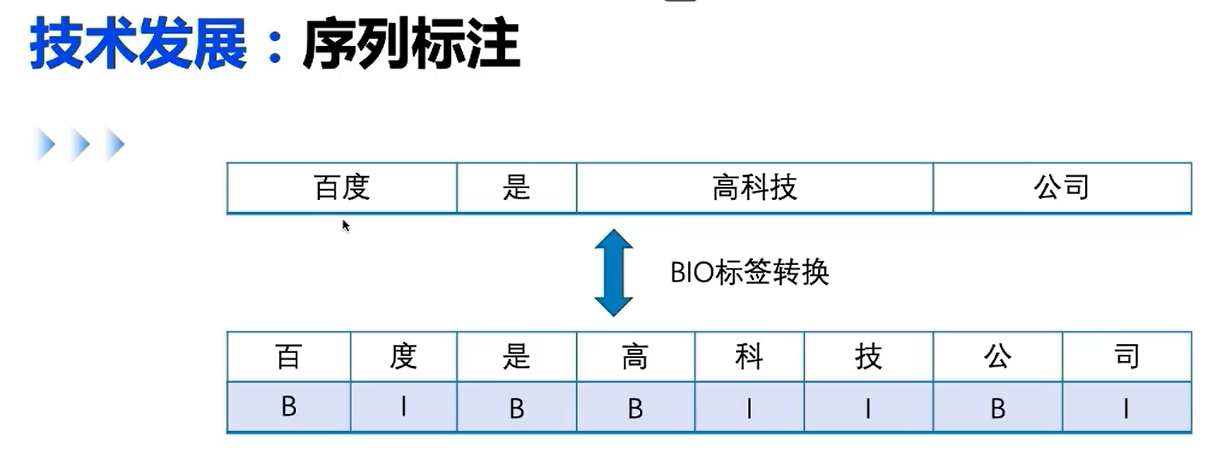


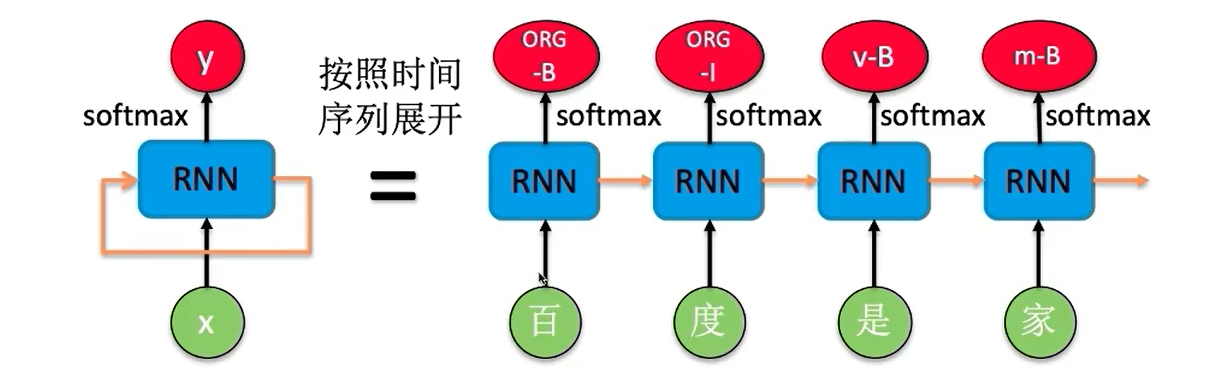
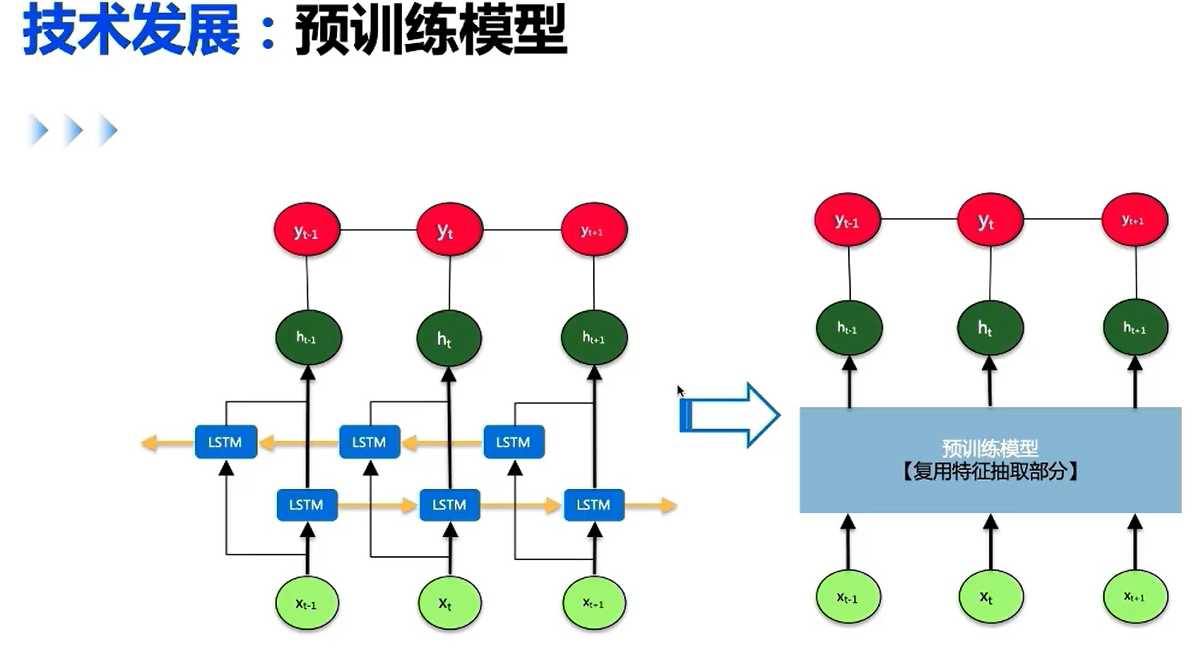
RNN实现序列标注
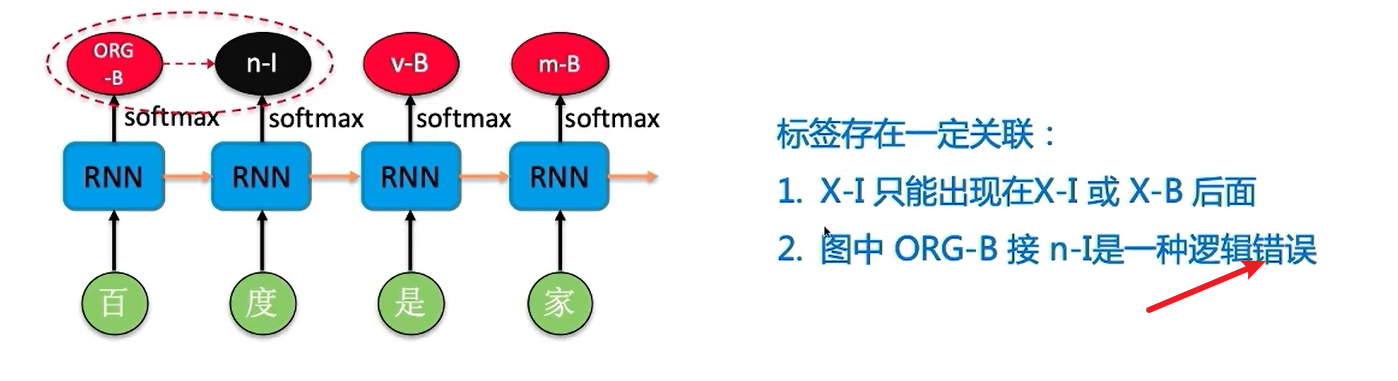

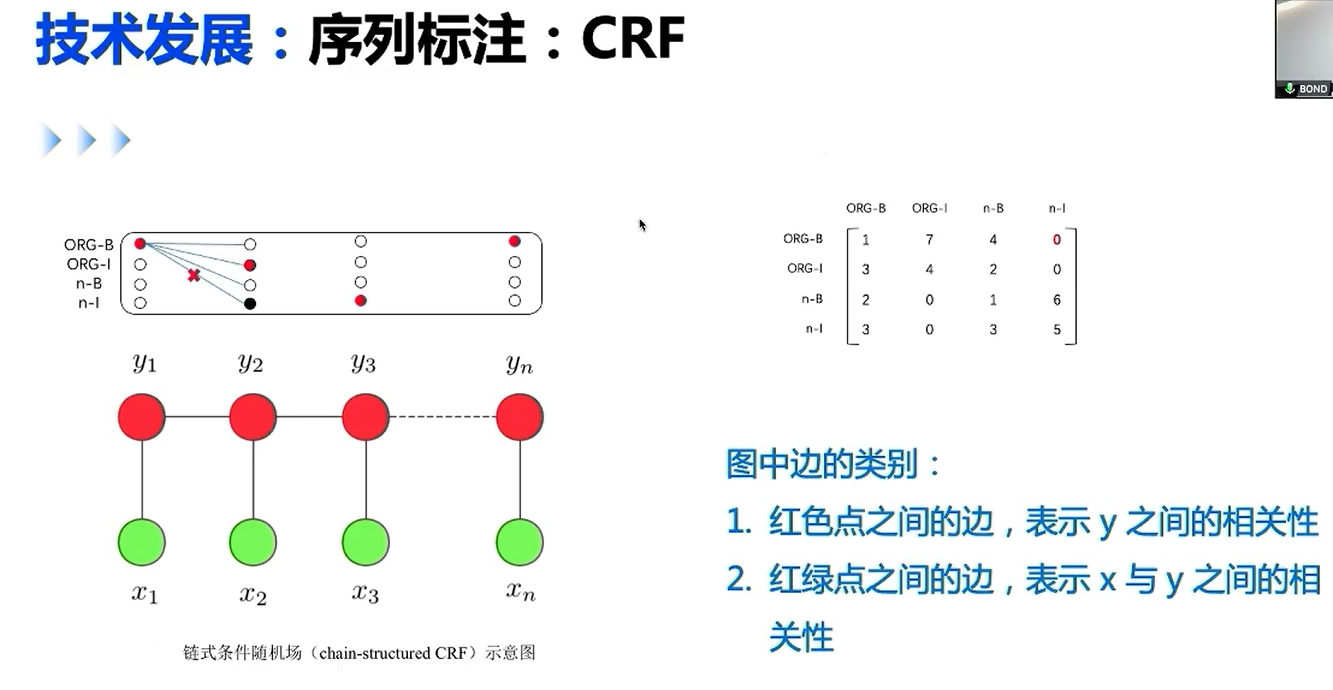
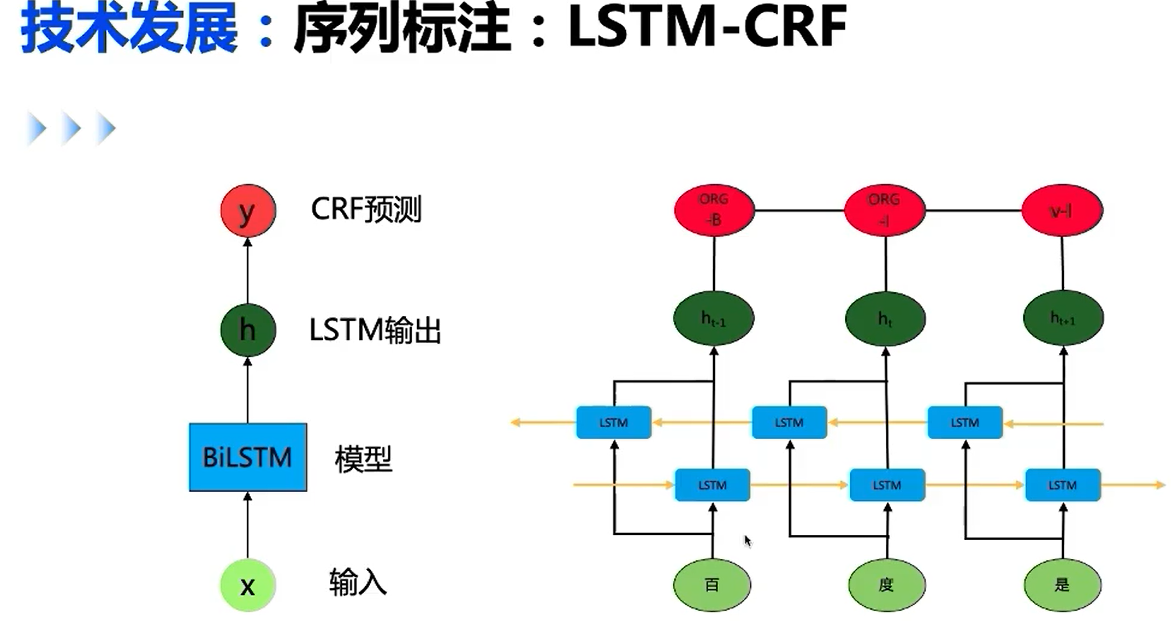
预训练模型对没有见过的词又很好的作用
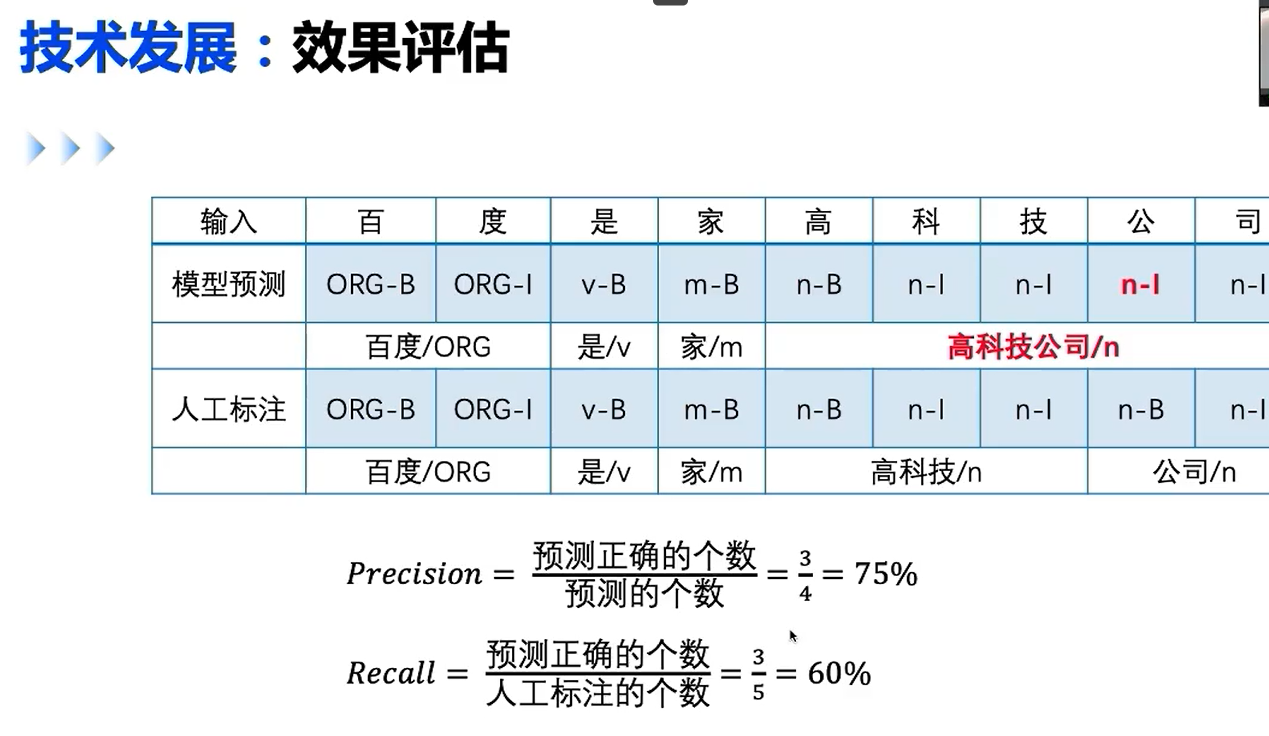
效果评估
通常以词为预测力度,召回率就是人工标注的词组预测的与所有词组的概率之比,可以看出,虽然只有一个label错了,但是预测率远远小于 8 / 9,这种方法通常是更佳严苛的。
LAC

序列标注展示

智能问答
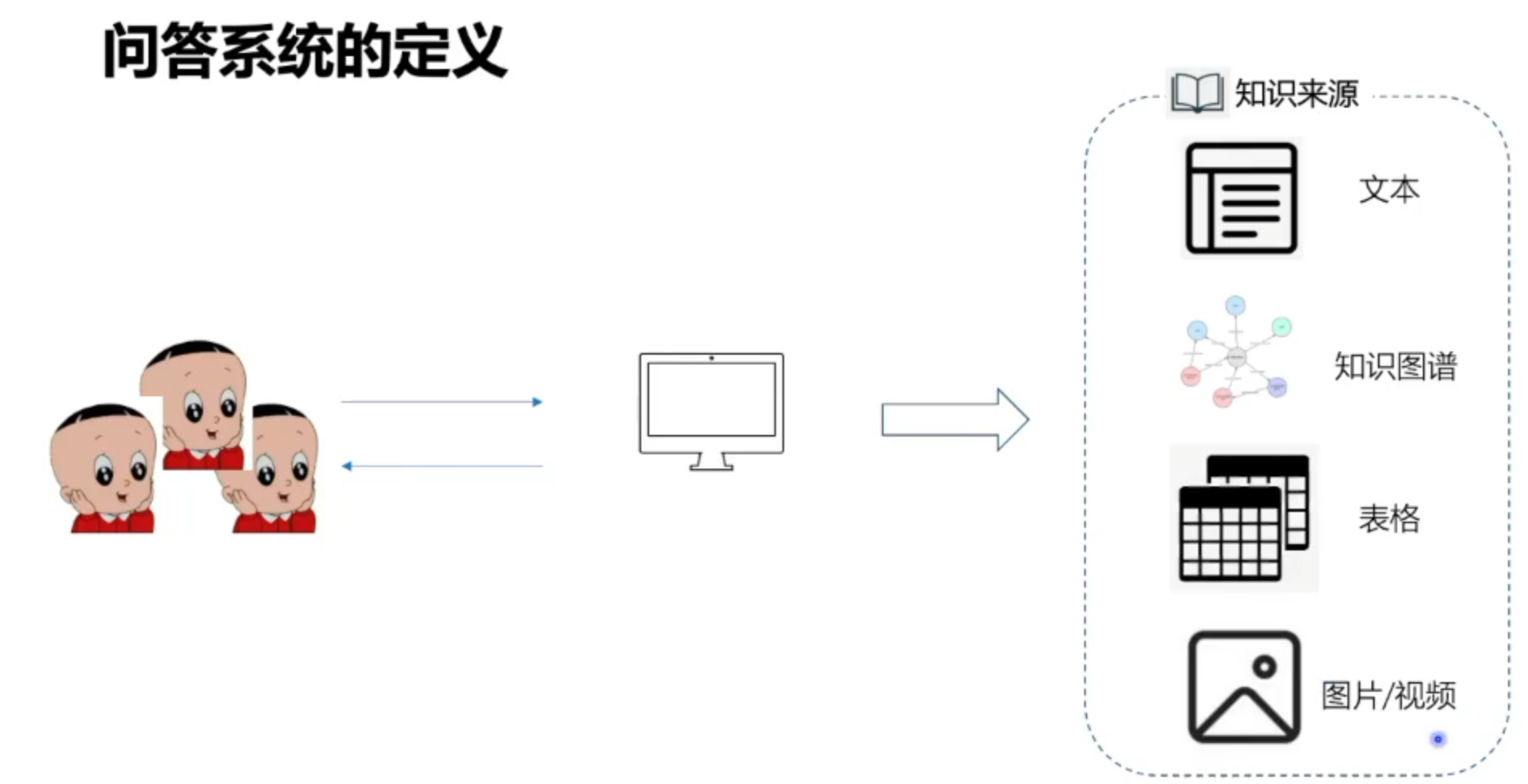
什么是问答系统?
信息检索的高级信息,能用准确简洁的自然语言回答用户用自然语言的问题。

为了解决人们日益增长的知识文化需要而提出
问答系统的应用场景

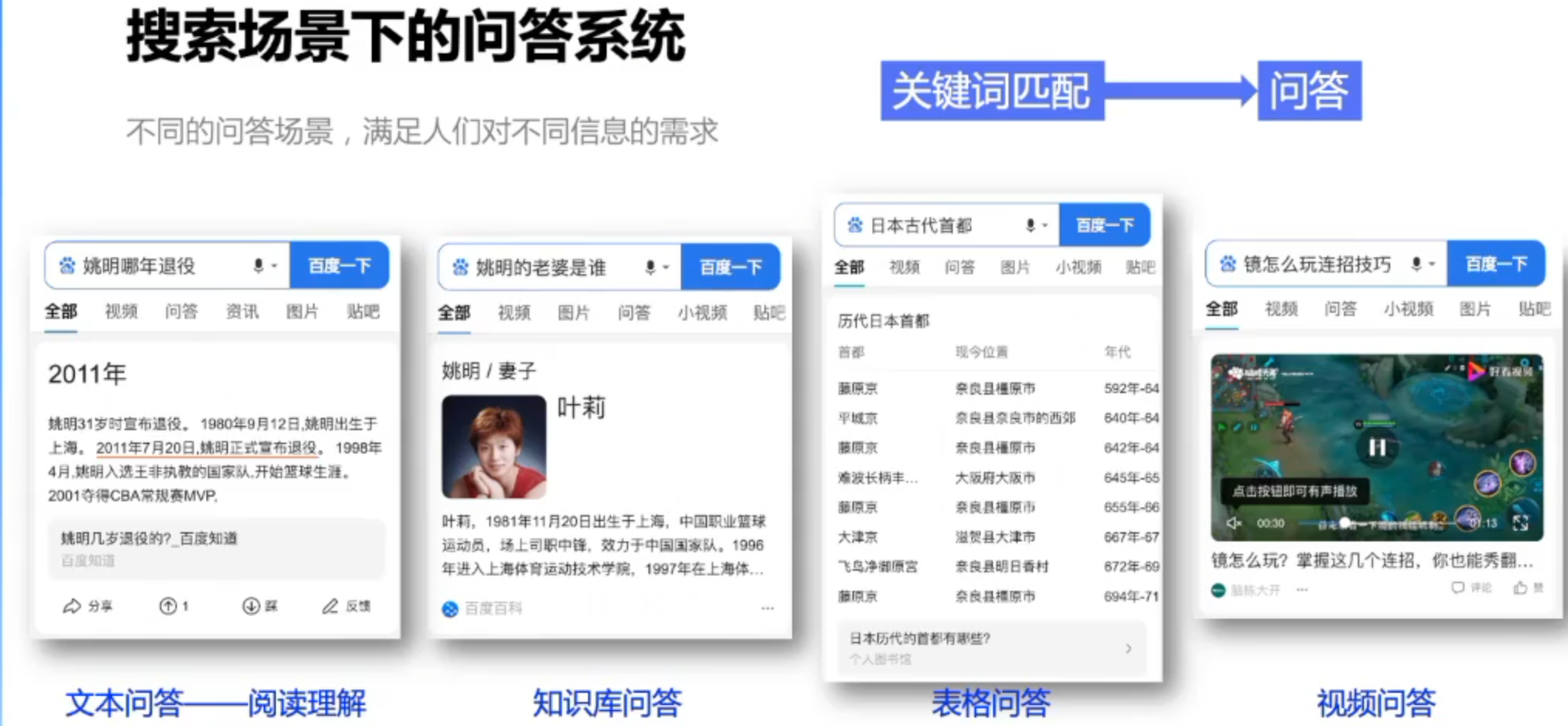
问答类型
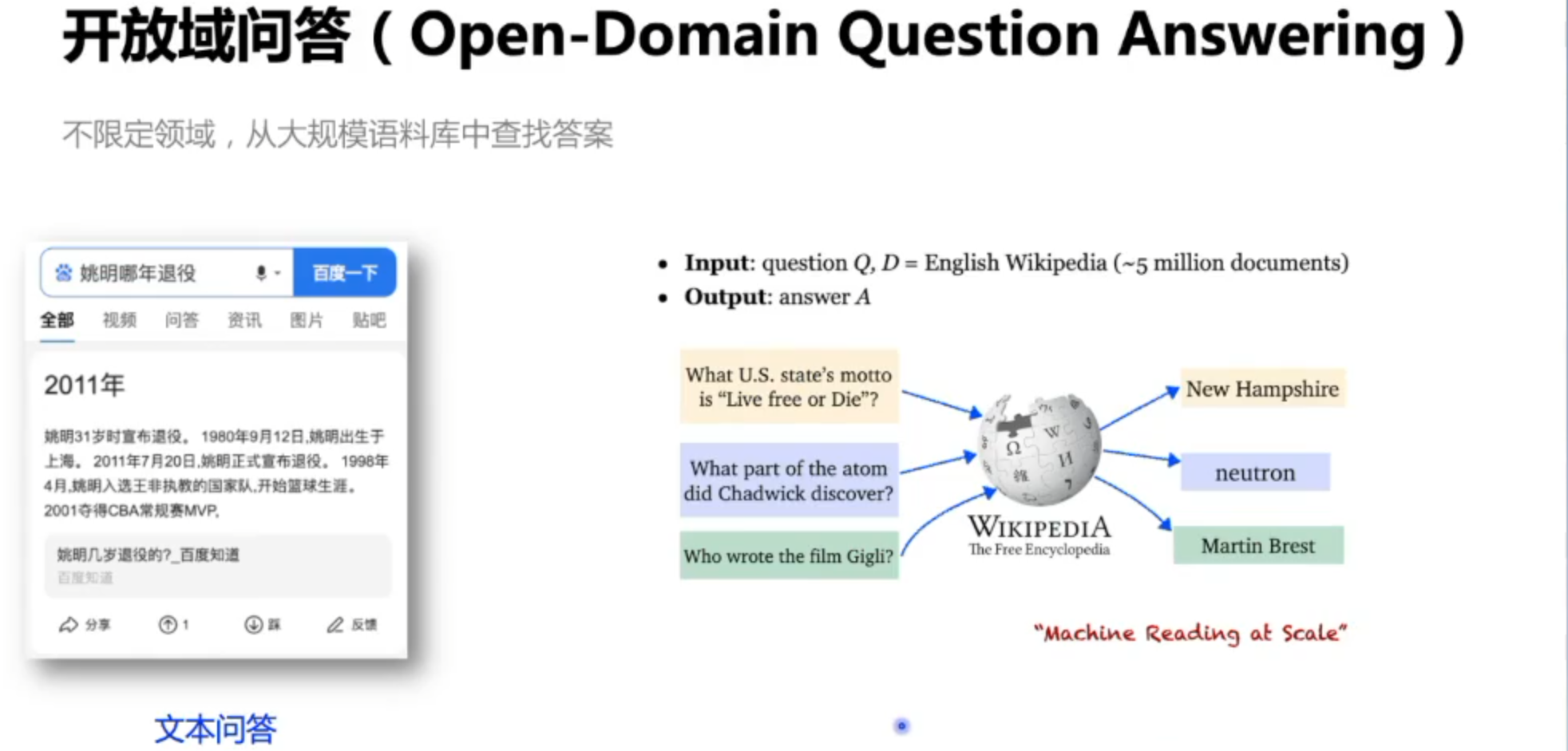
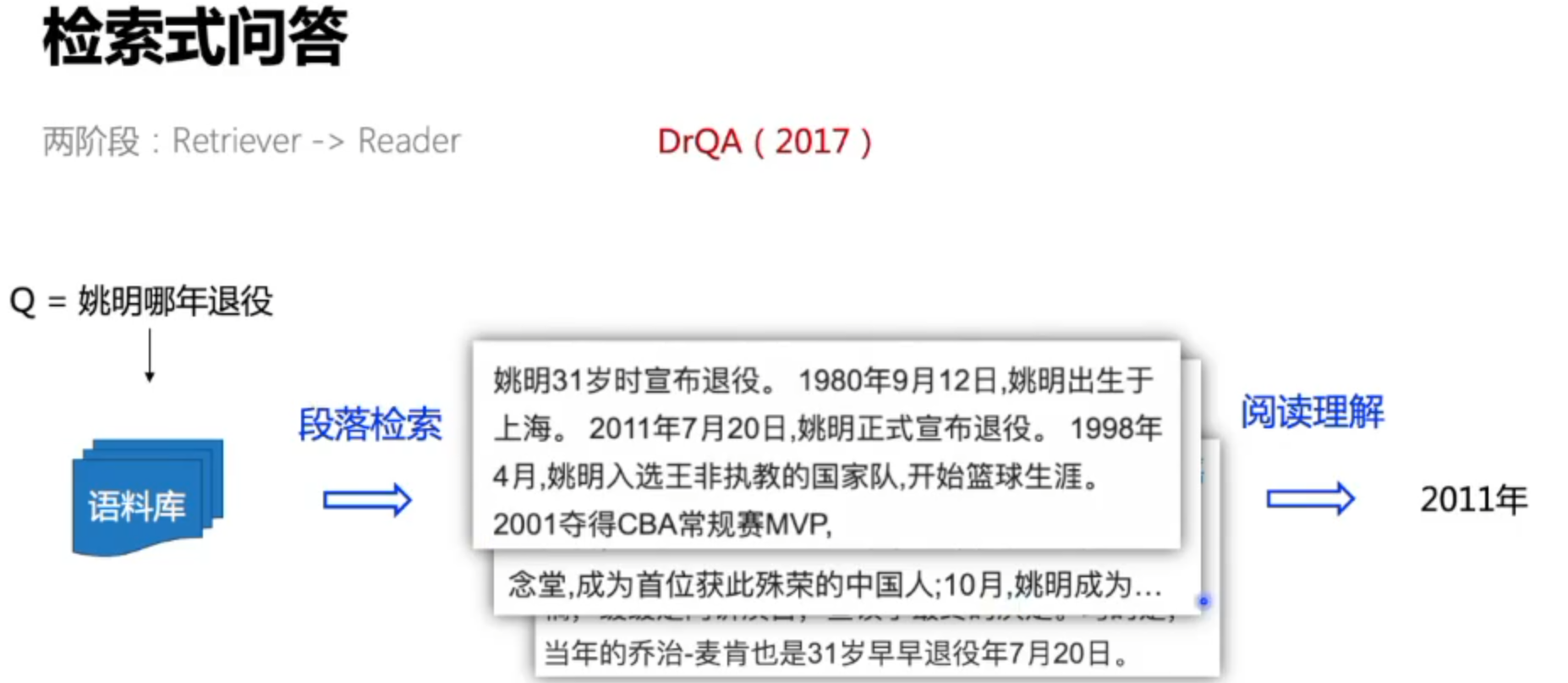
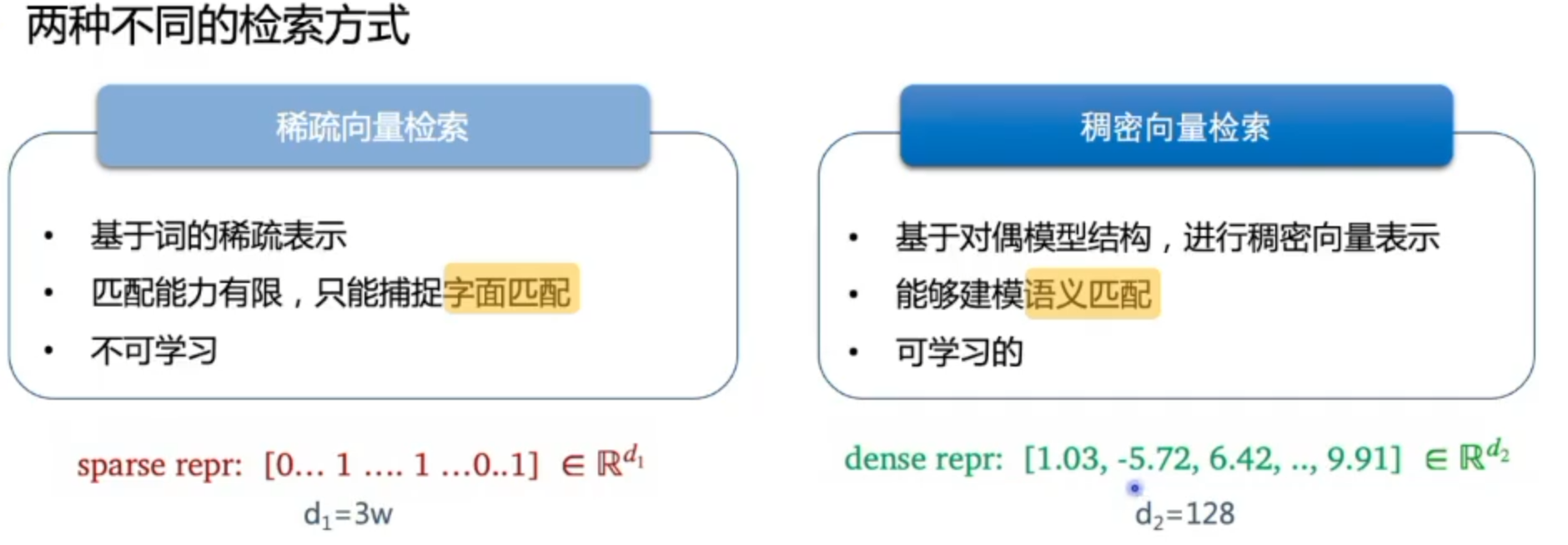
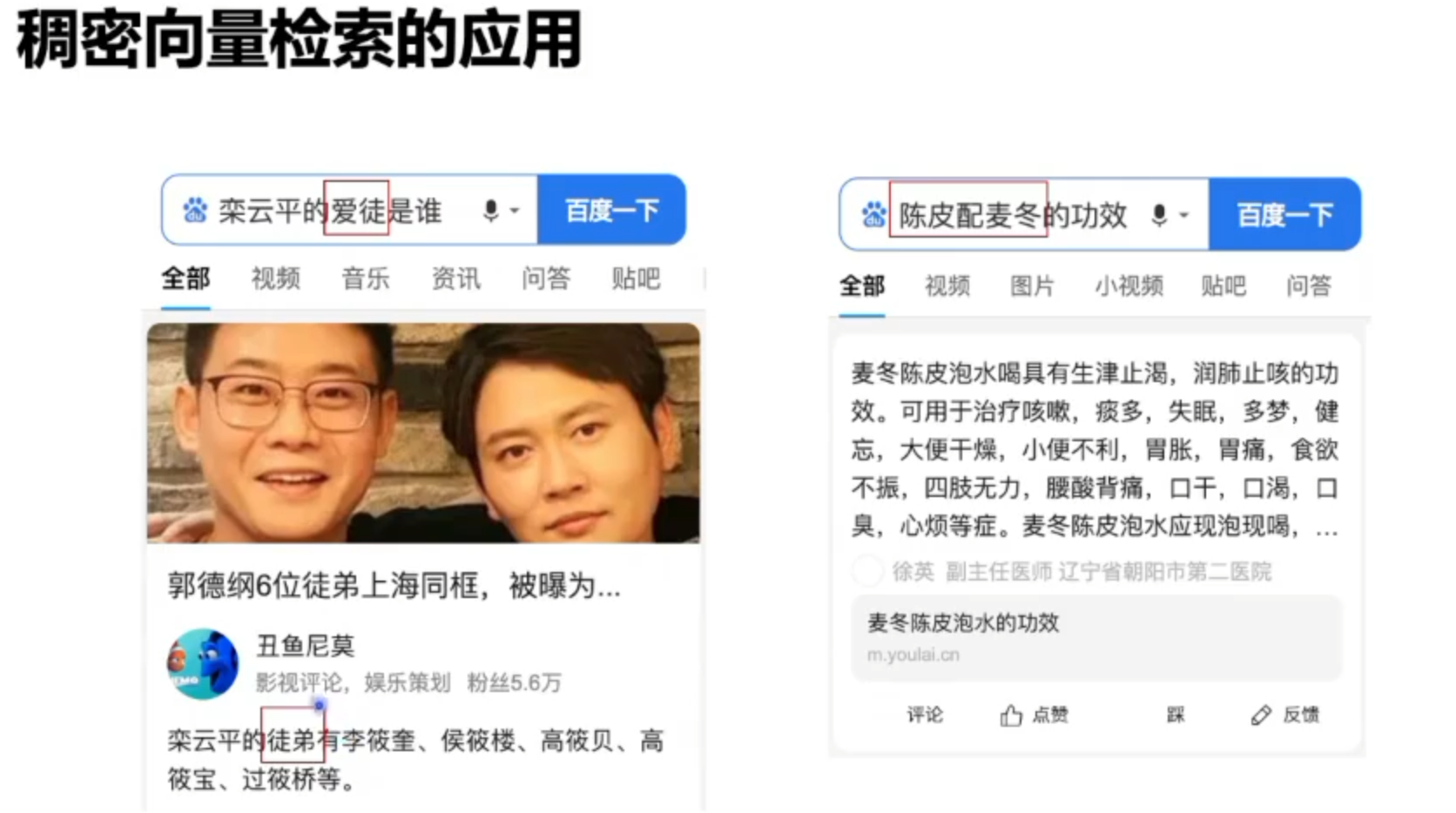
19年随着预训练模型的提出,稠密向量成为主流
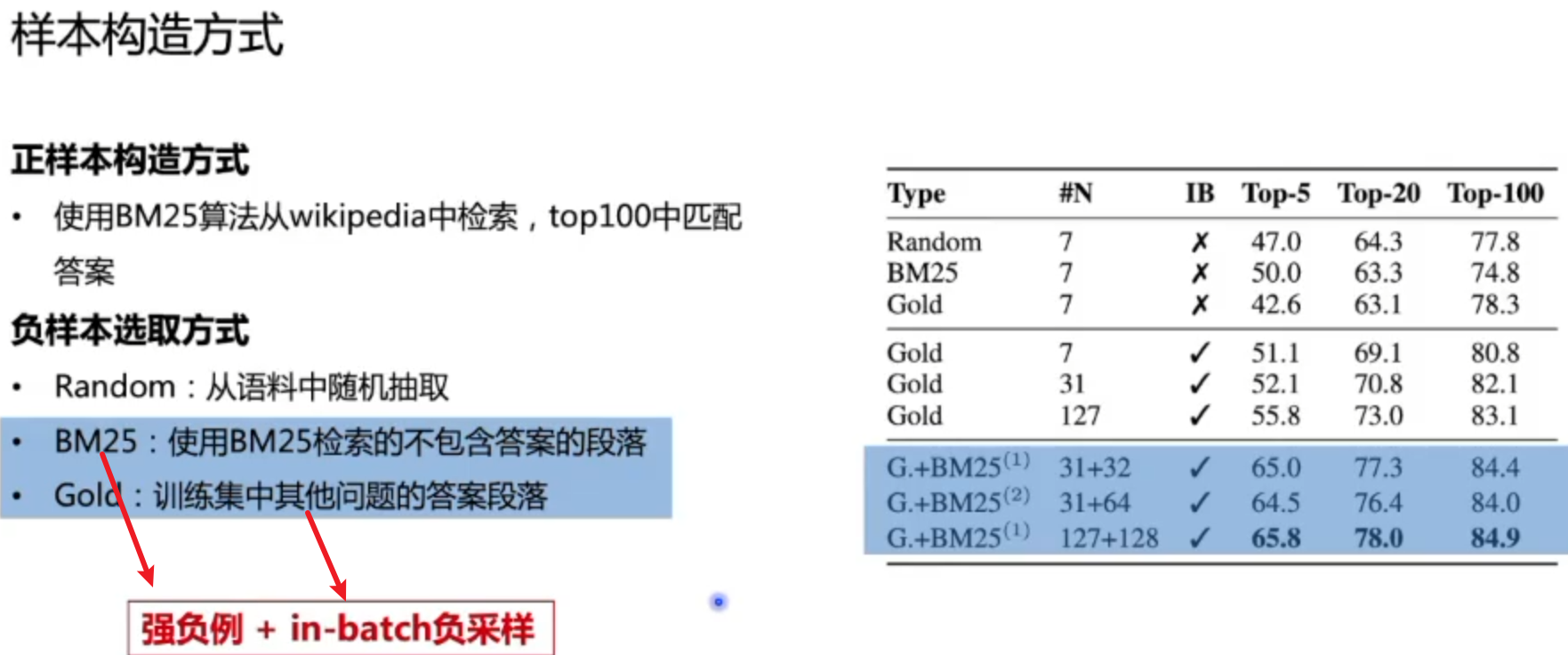
对稠密向量的优化,相当于将别的样本的Answer作为这个样本的负例子,与原本answer放在一起,做一个softmax多分类。

正例和强负例一般是1:1,按照经验弱负例是越多越好的。
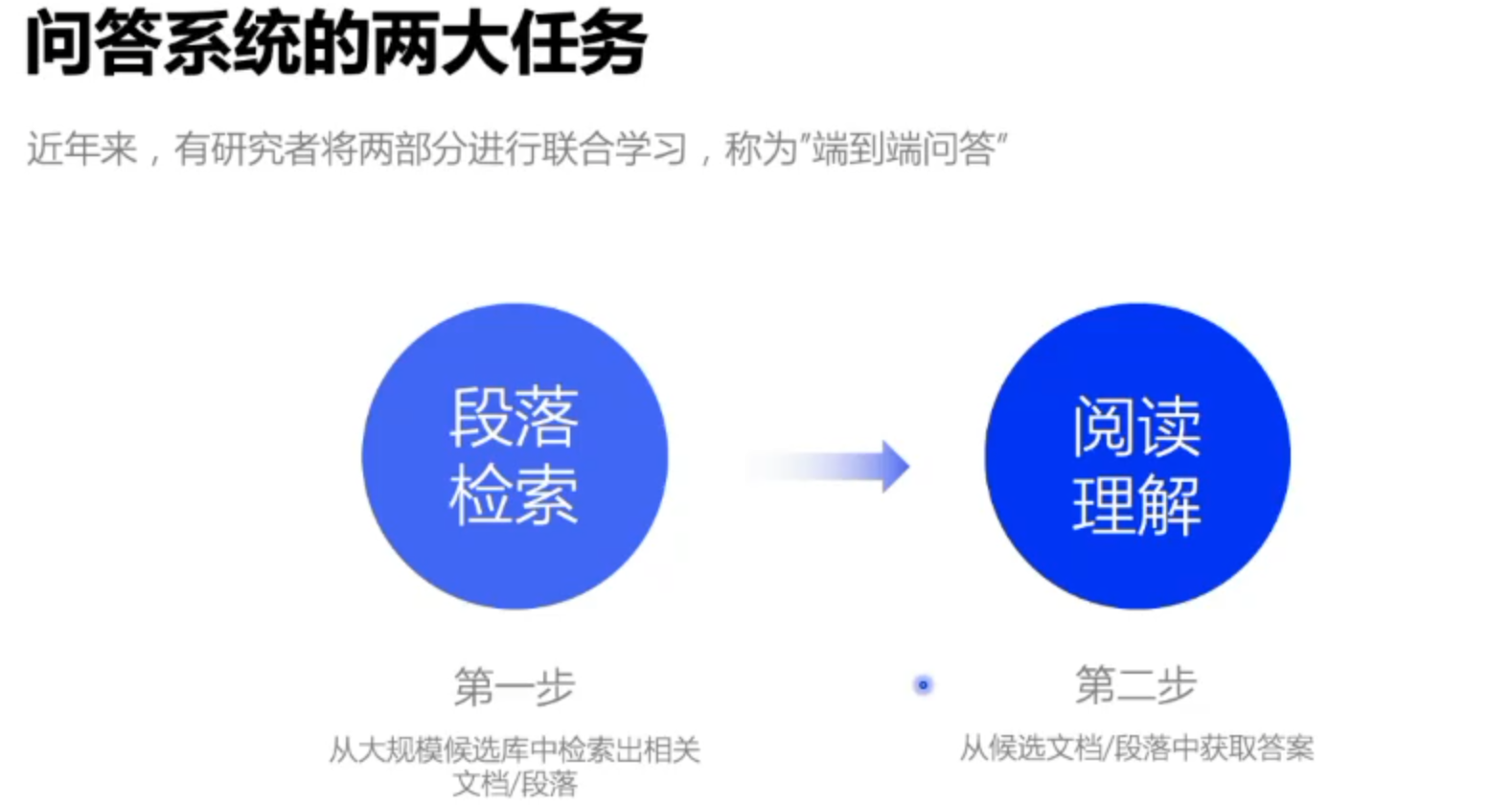
机器阅读理解

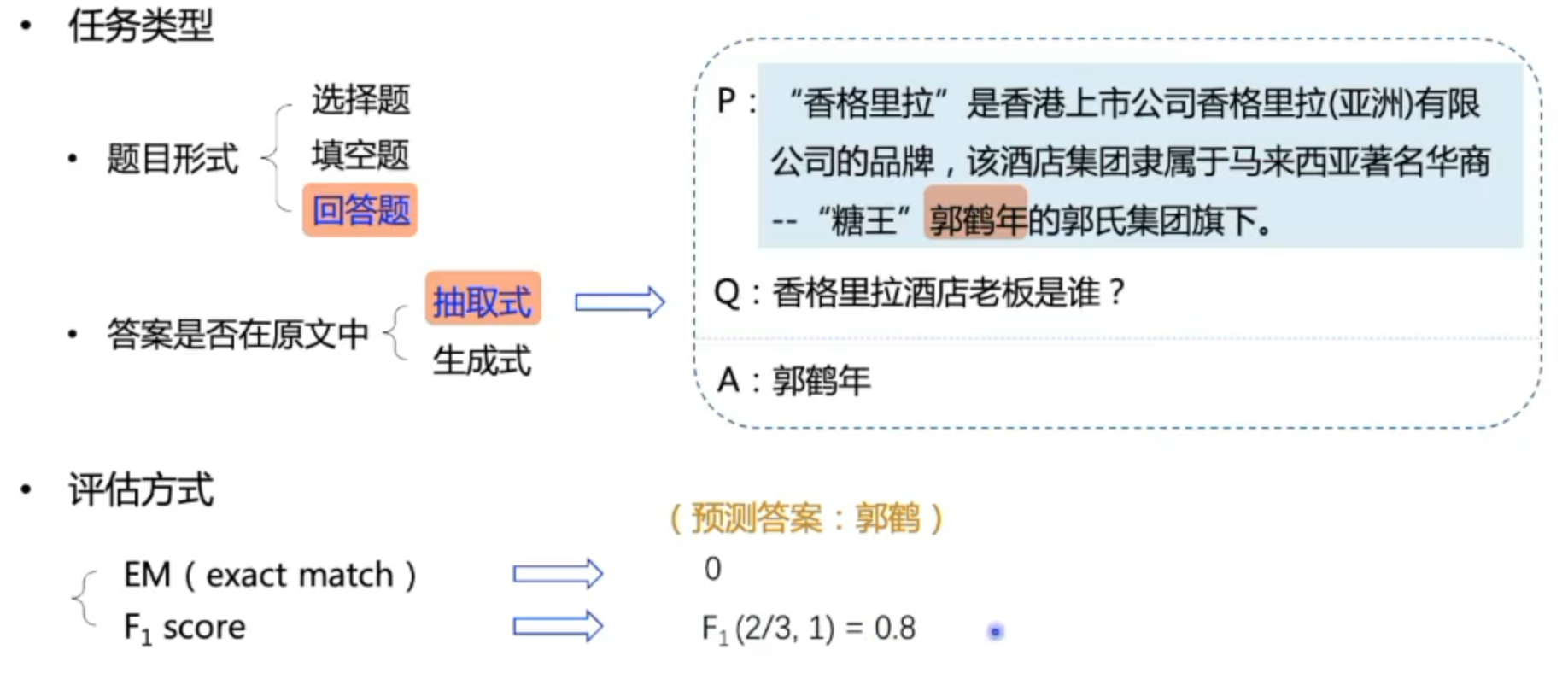
数据集介绍

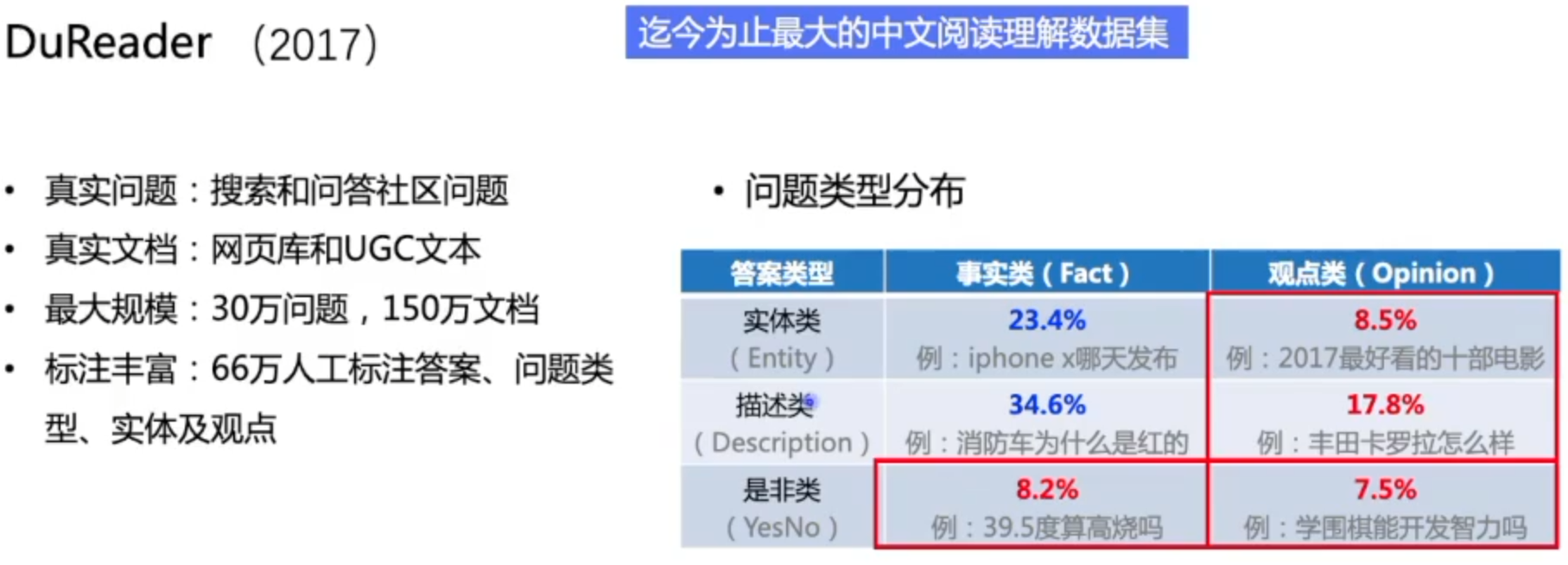
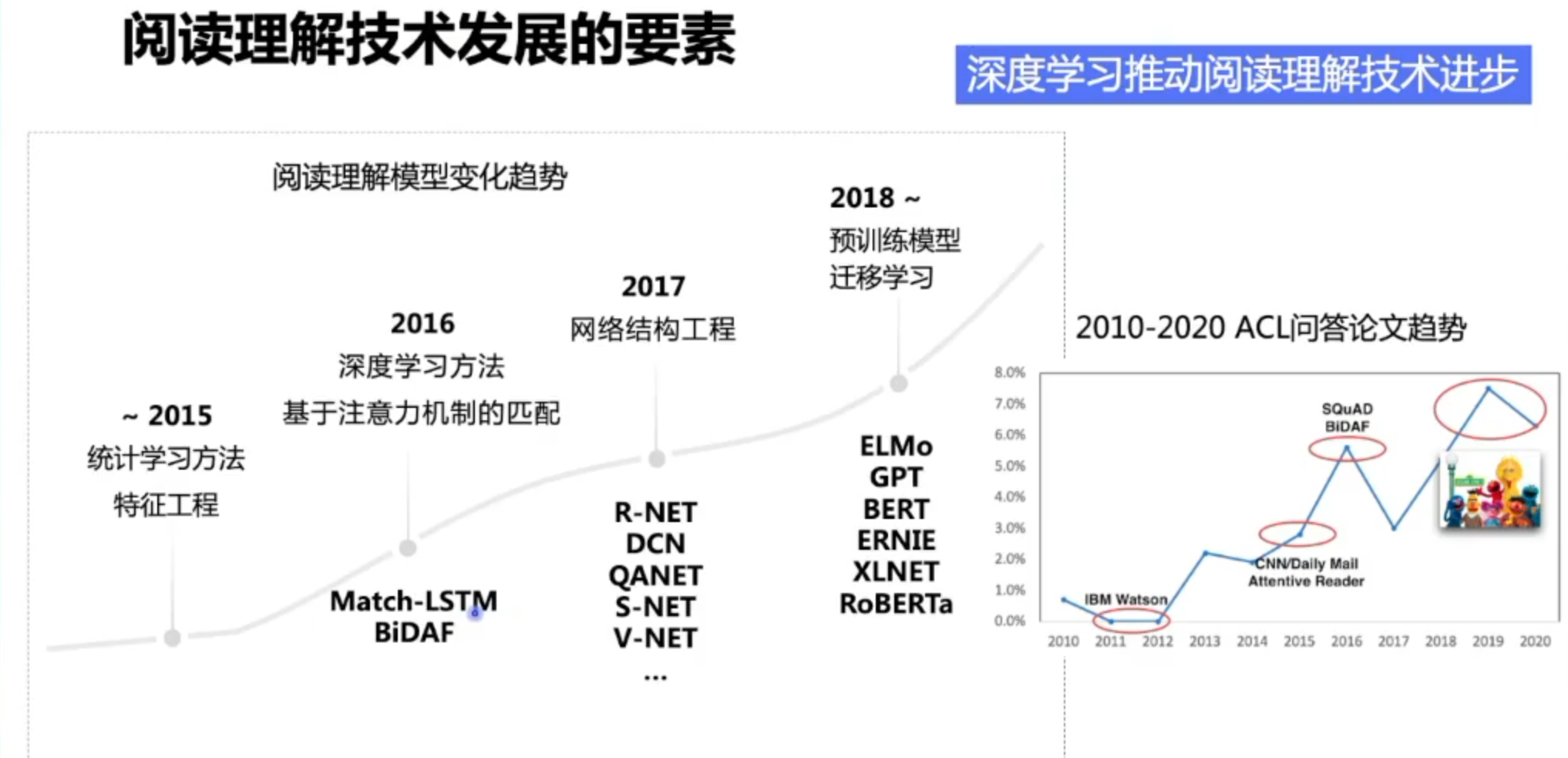
技术发展路线
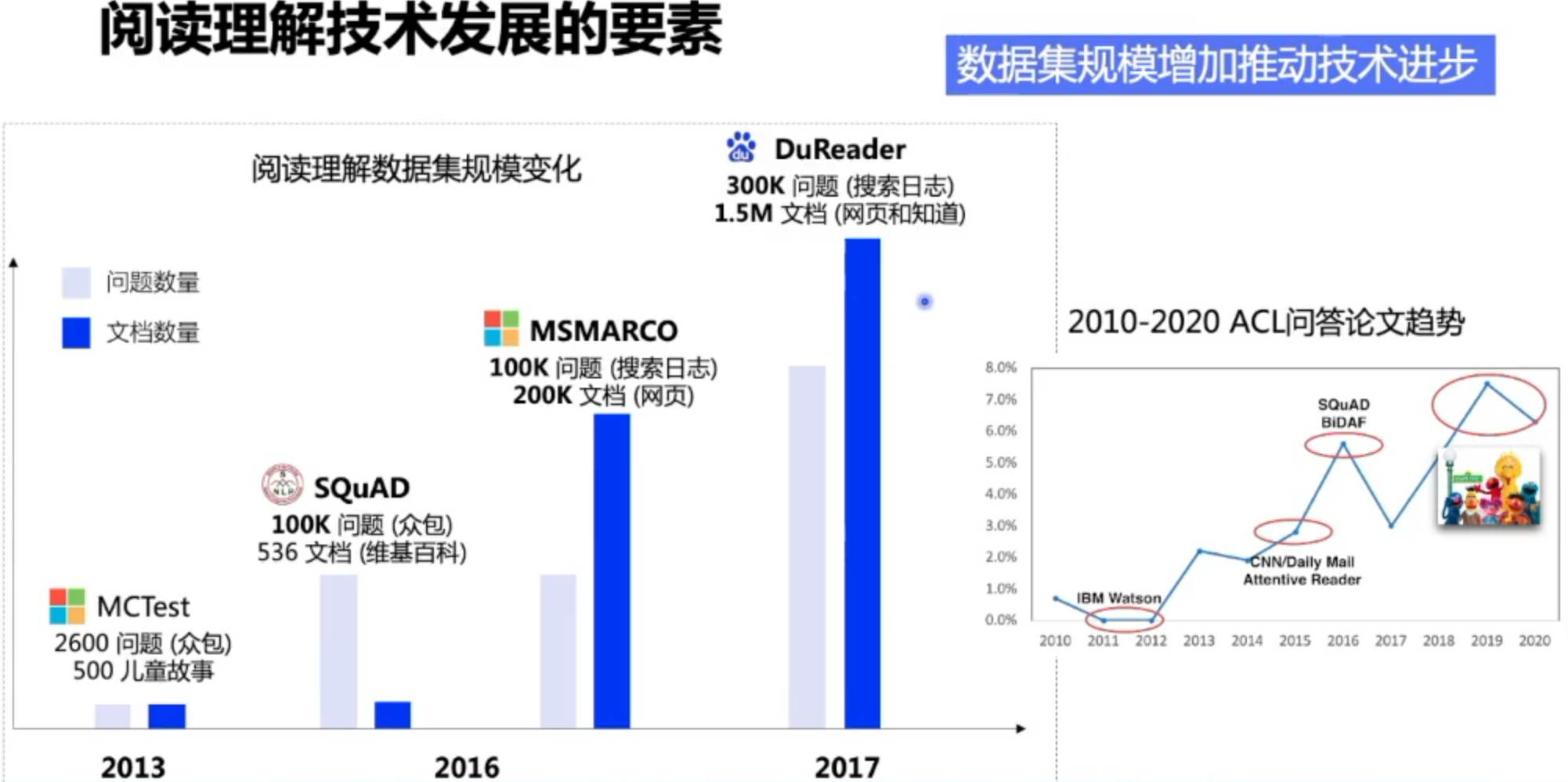
任务定义

相关模型
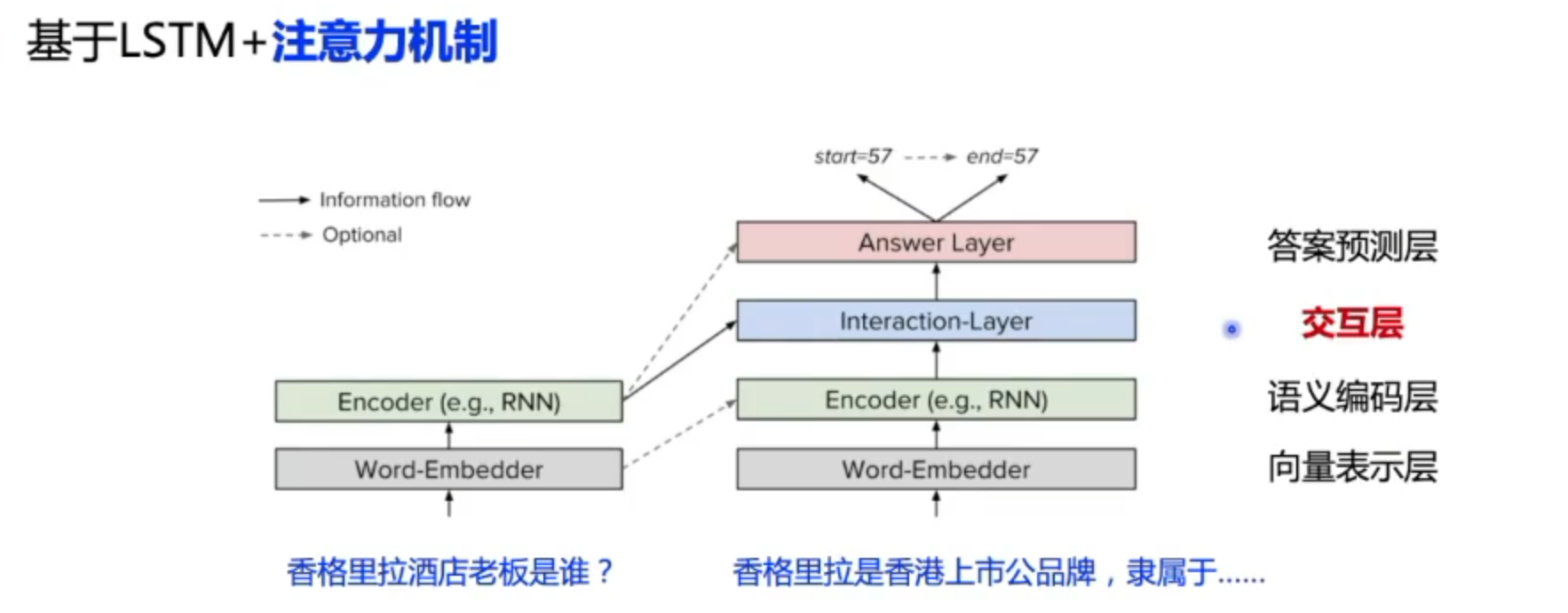
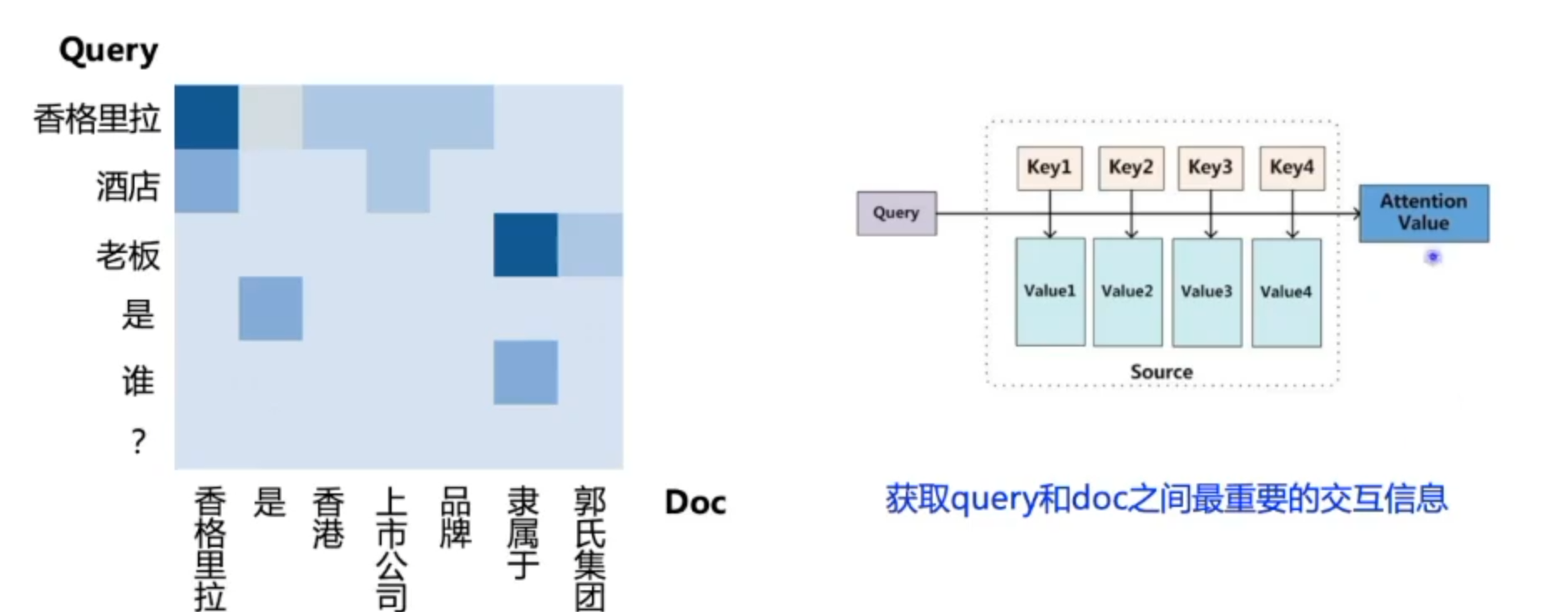
注意力机制简单来说就是获取文本交互信息的一种手段,关注于最重要的信息。
查询向量:Query
Valuex:已经编码好的语言表示
Keyx:问题的向量与Value做内积之后做一个归一化,代表每个词的权重,最后根据Value来对权重进行加权求和,就得到了经过attention之后的值(K、Q、V)
存在的问题

总结
结构化数据问答
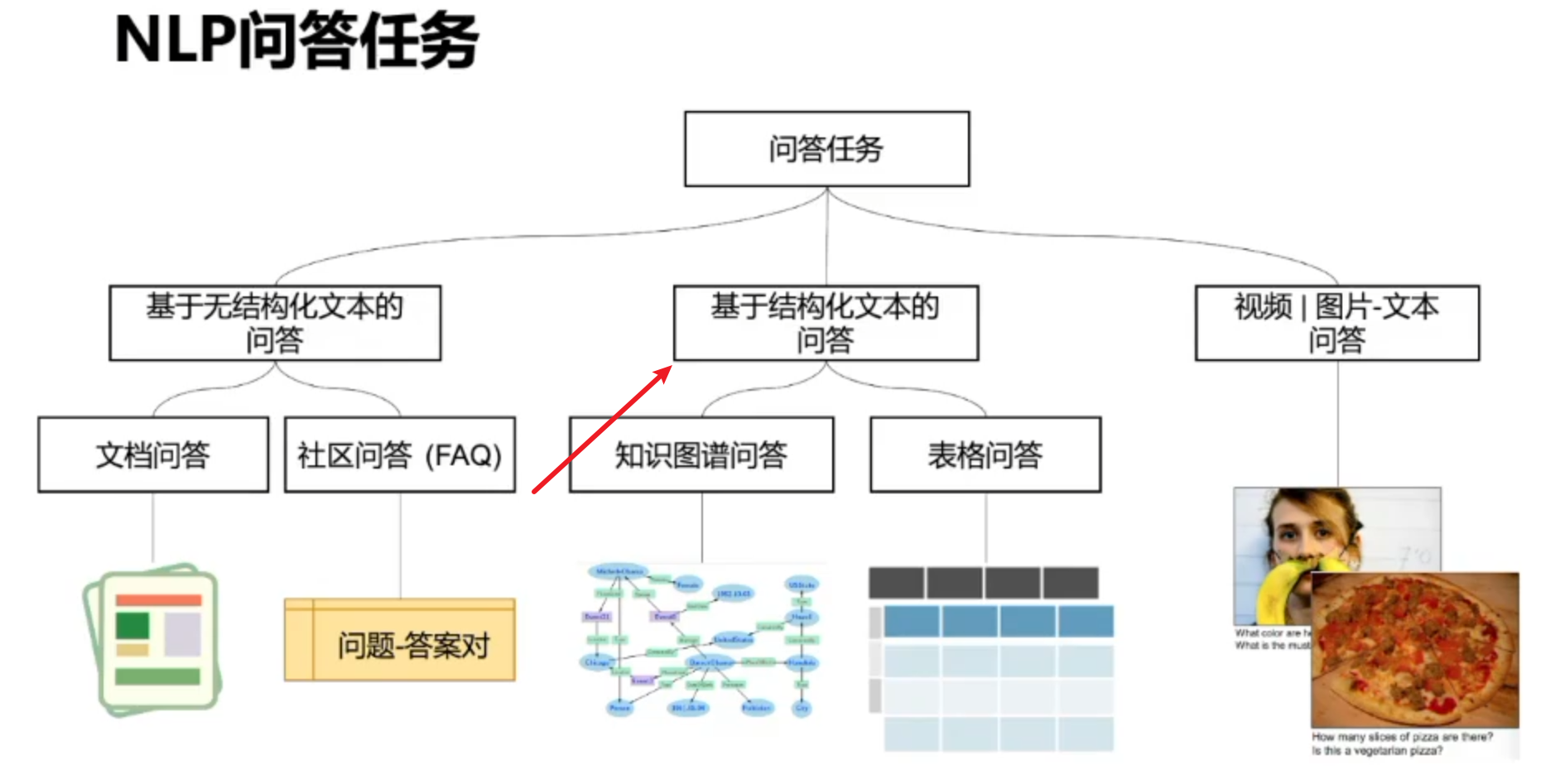
表格问答
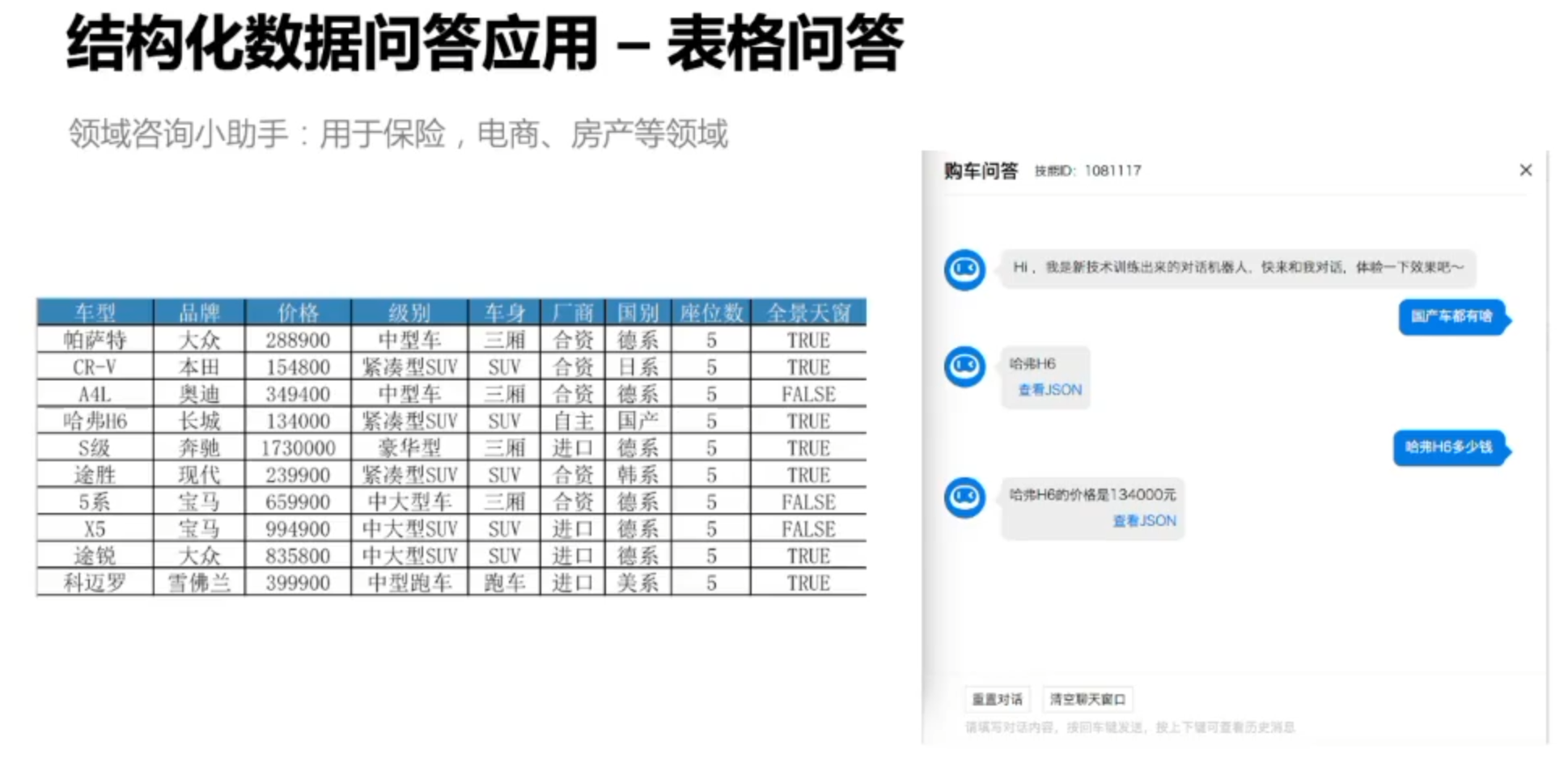
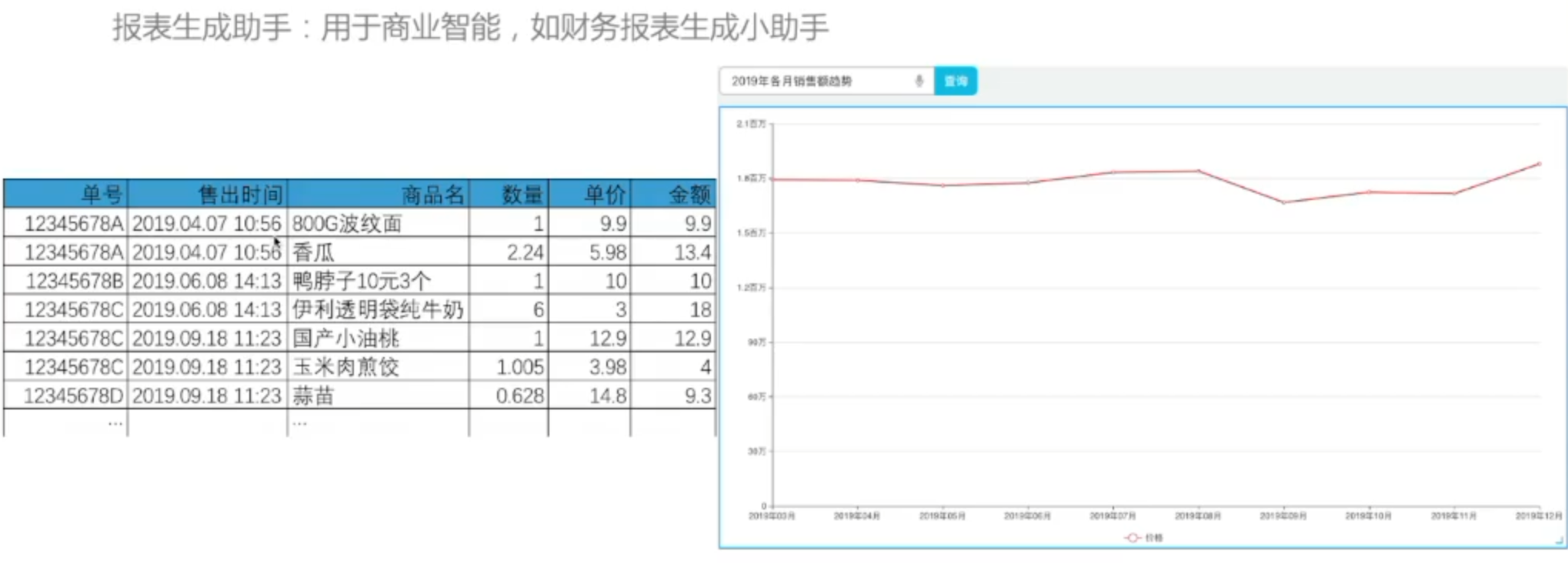
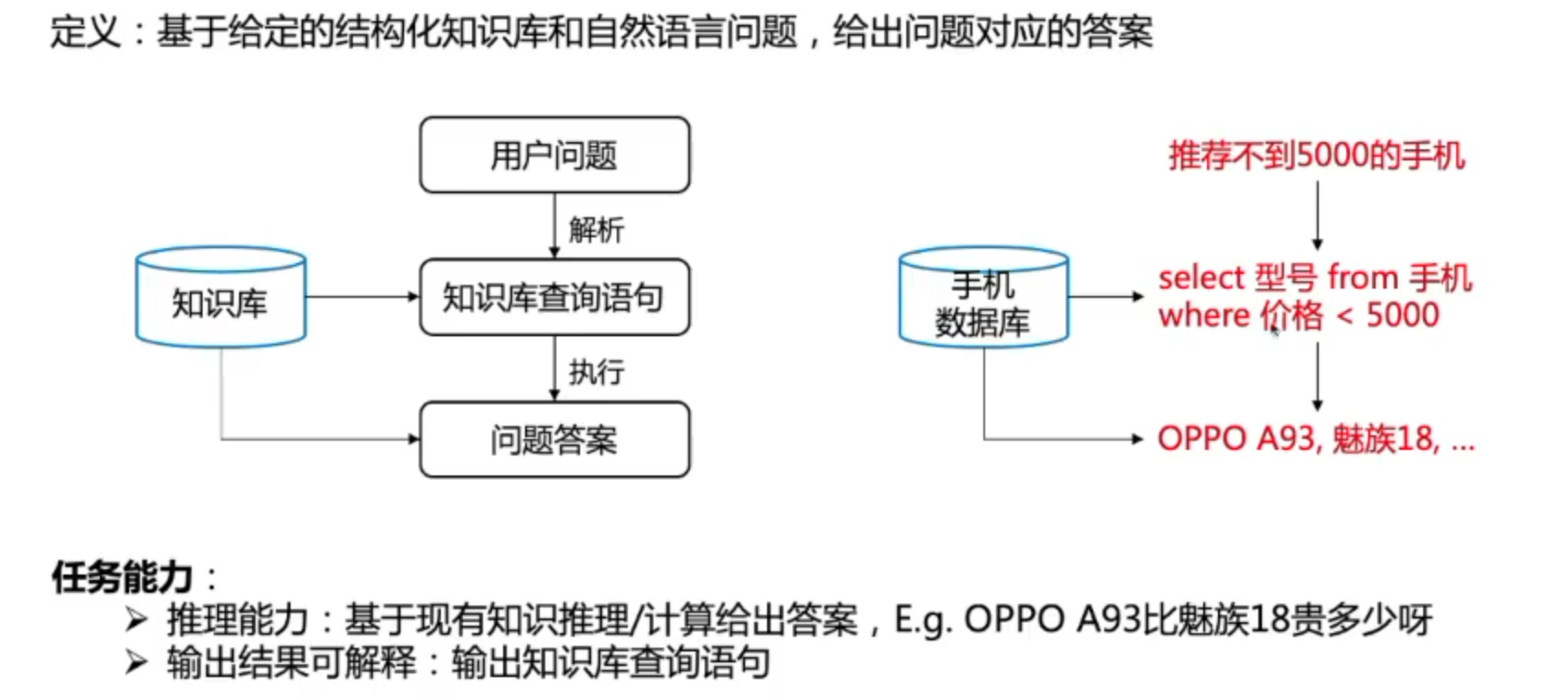
Text-to-SQL
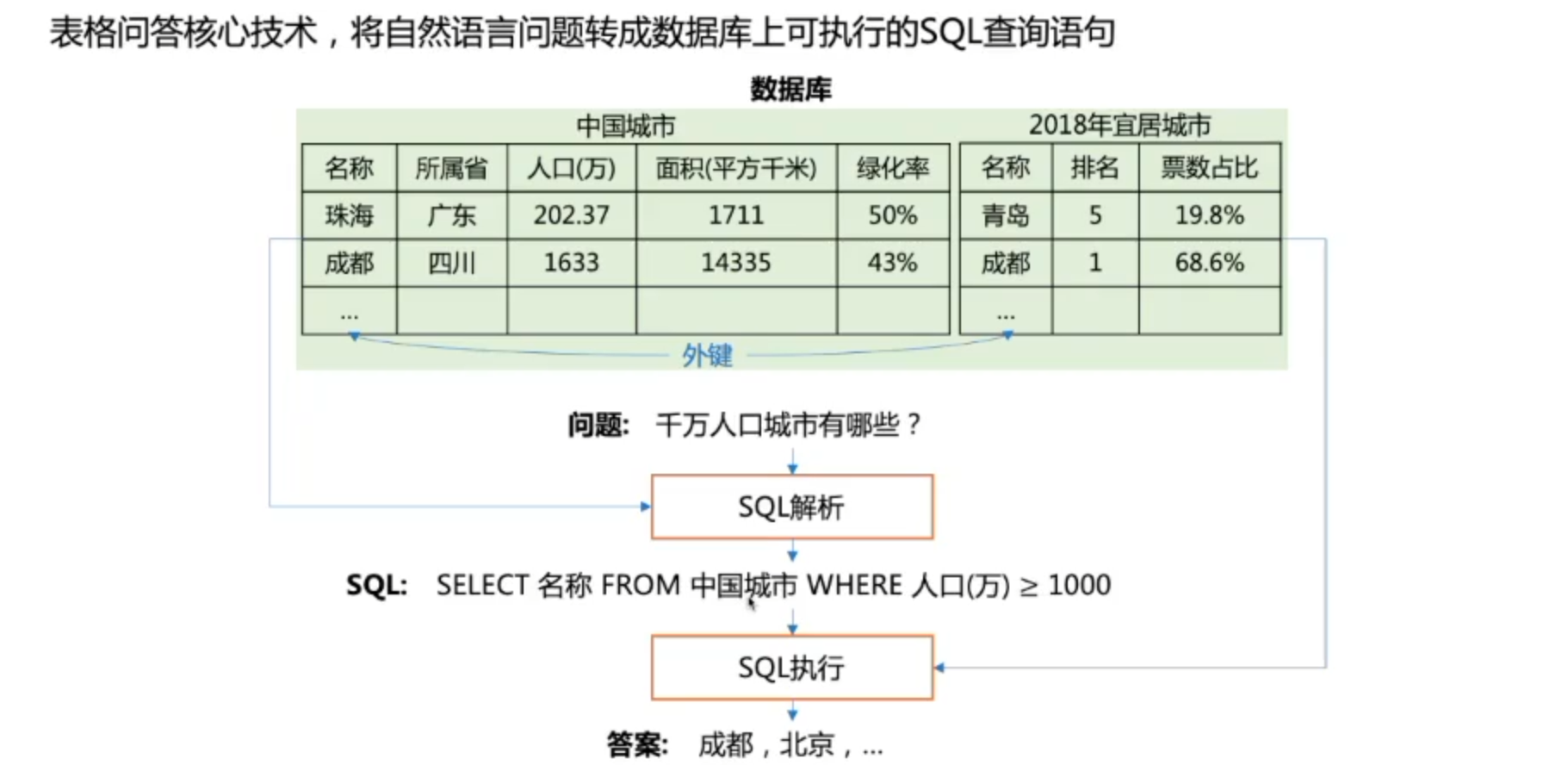
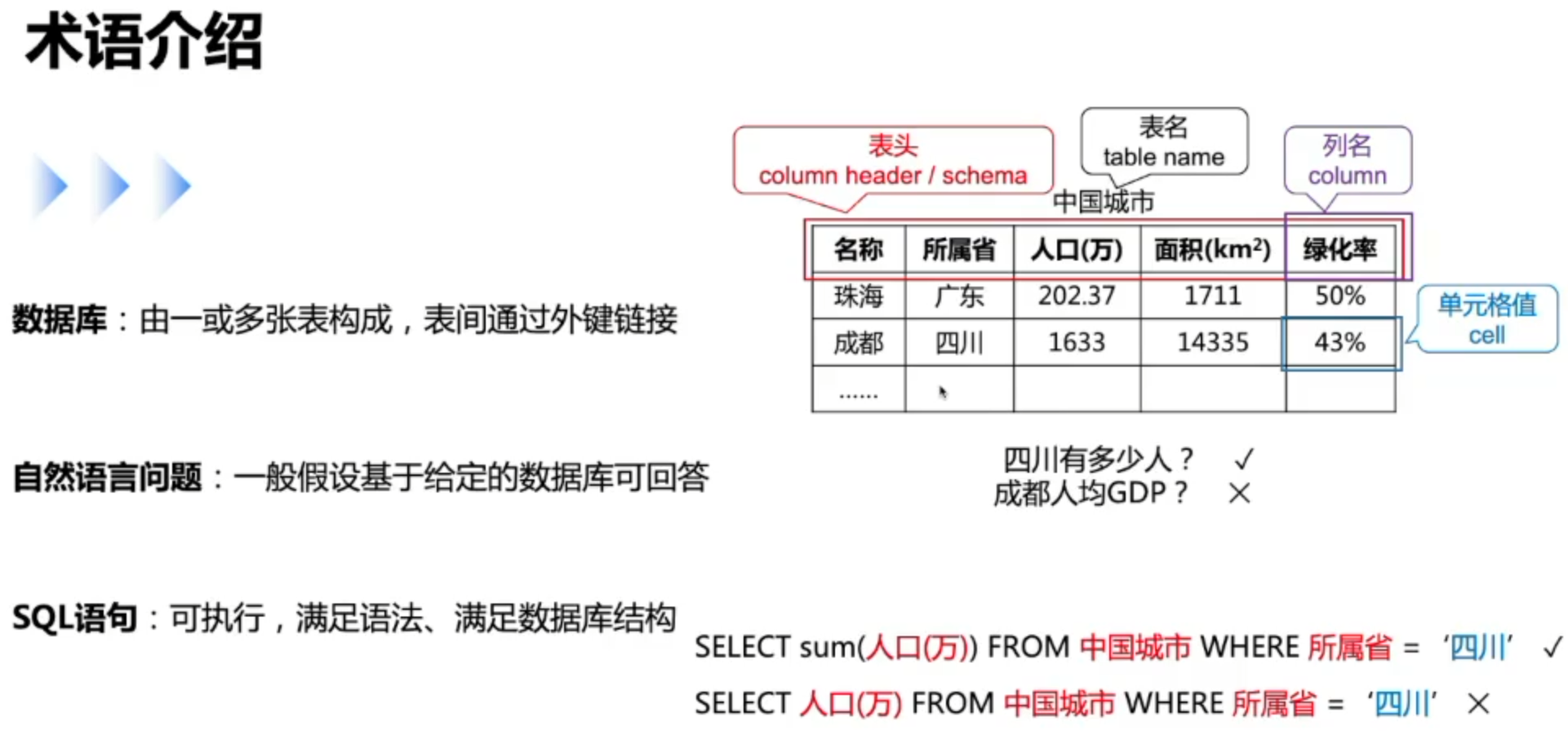
术语介绍
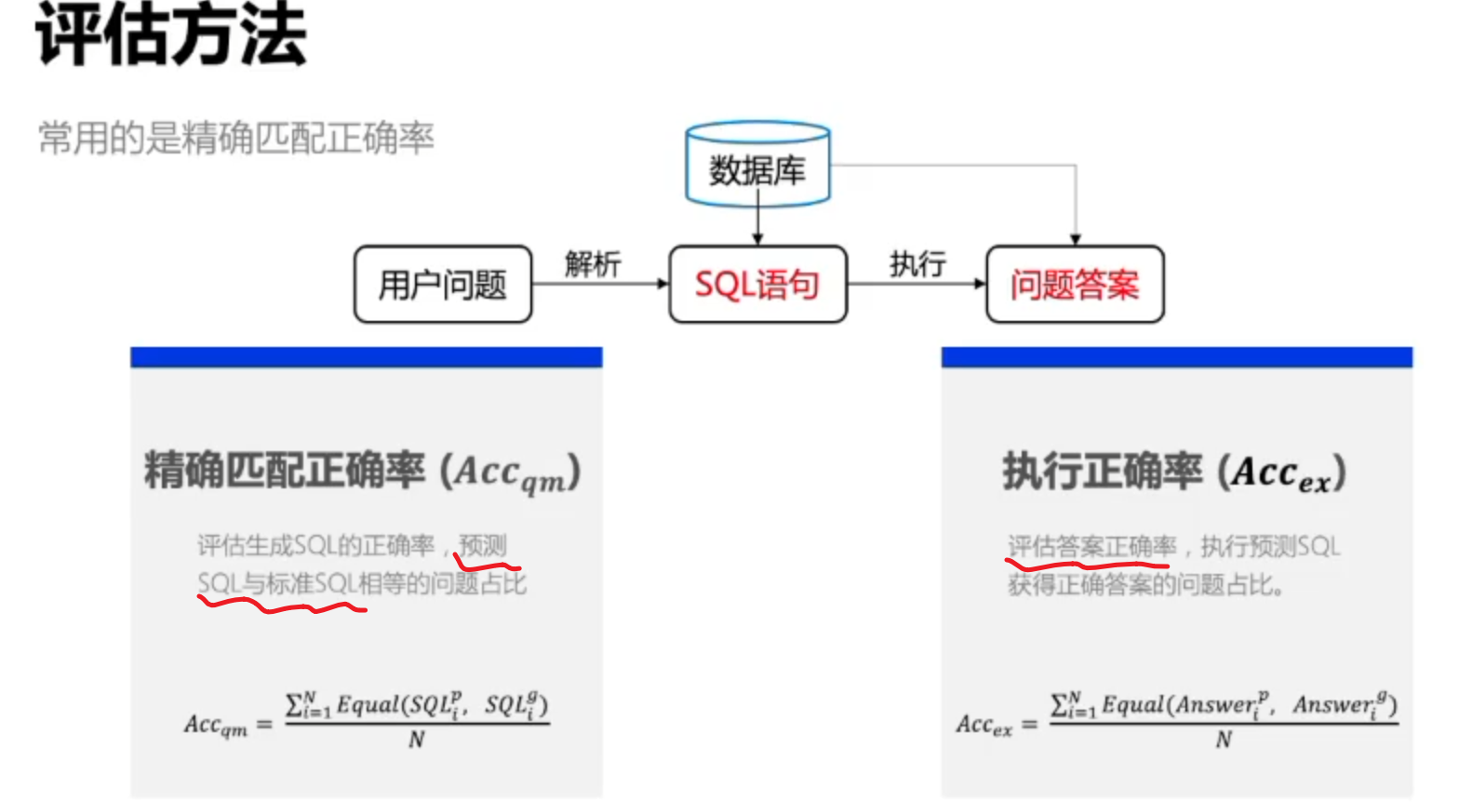
评估方法
使用中主要看更关注与答案的准确还是更关注于SQL语句的准确率
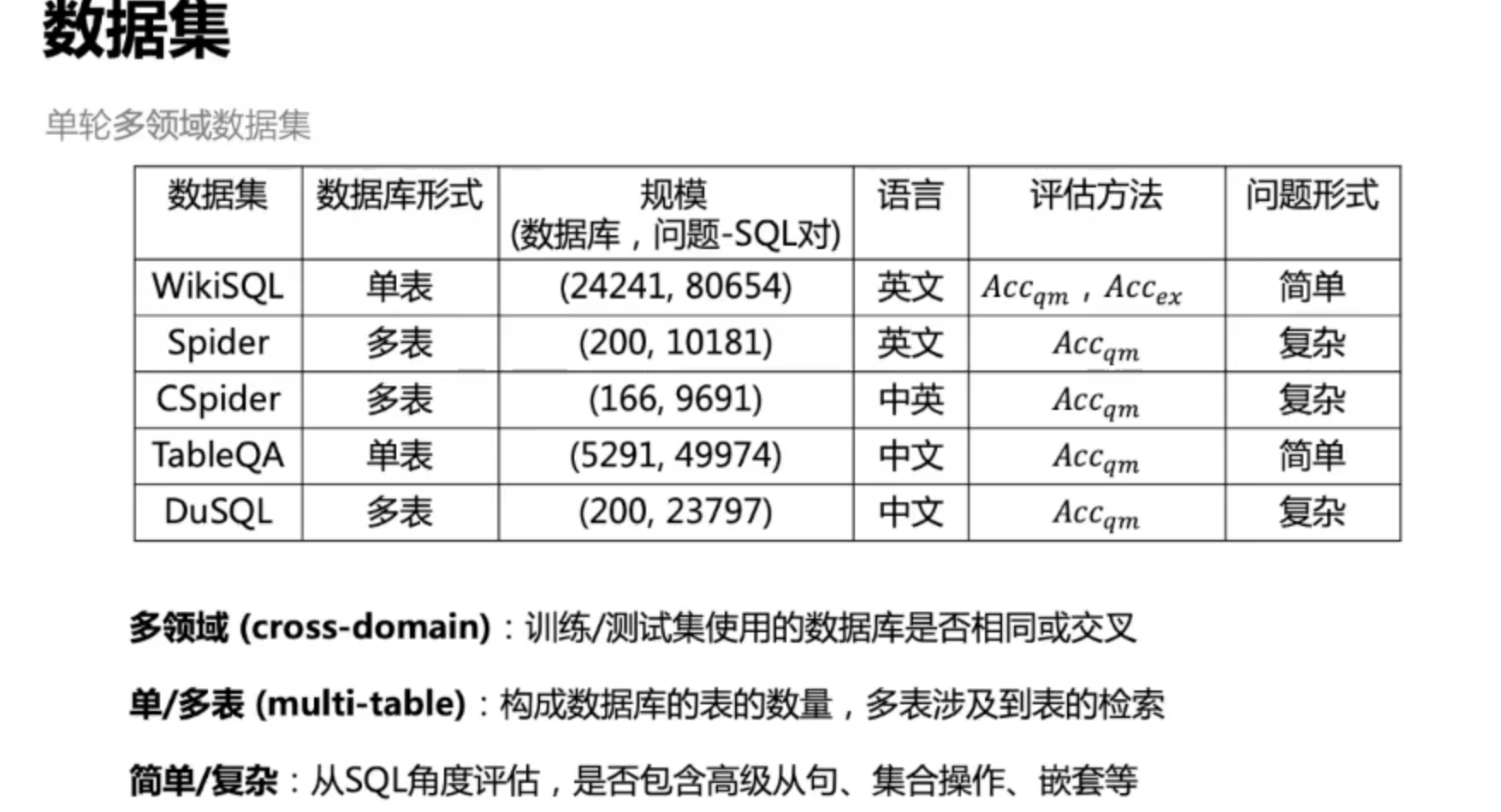
相关数据集介绍
学习方式
弱监督适用于比较简单的数据集,目前主要都是用有监督的方法

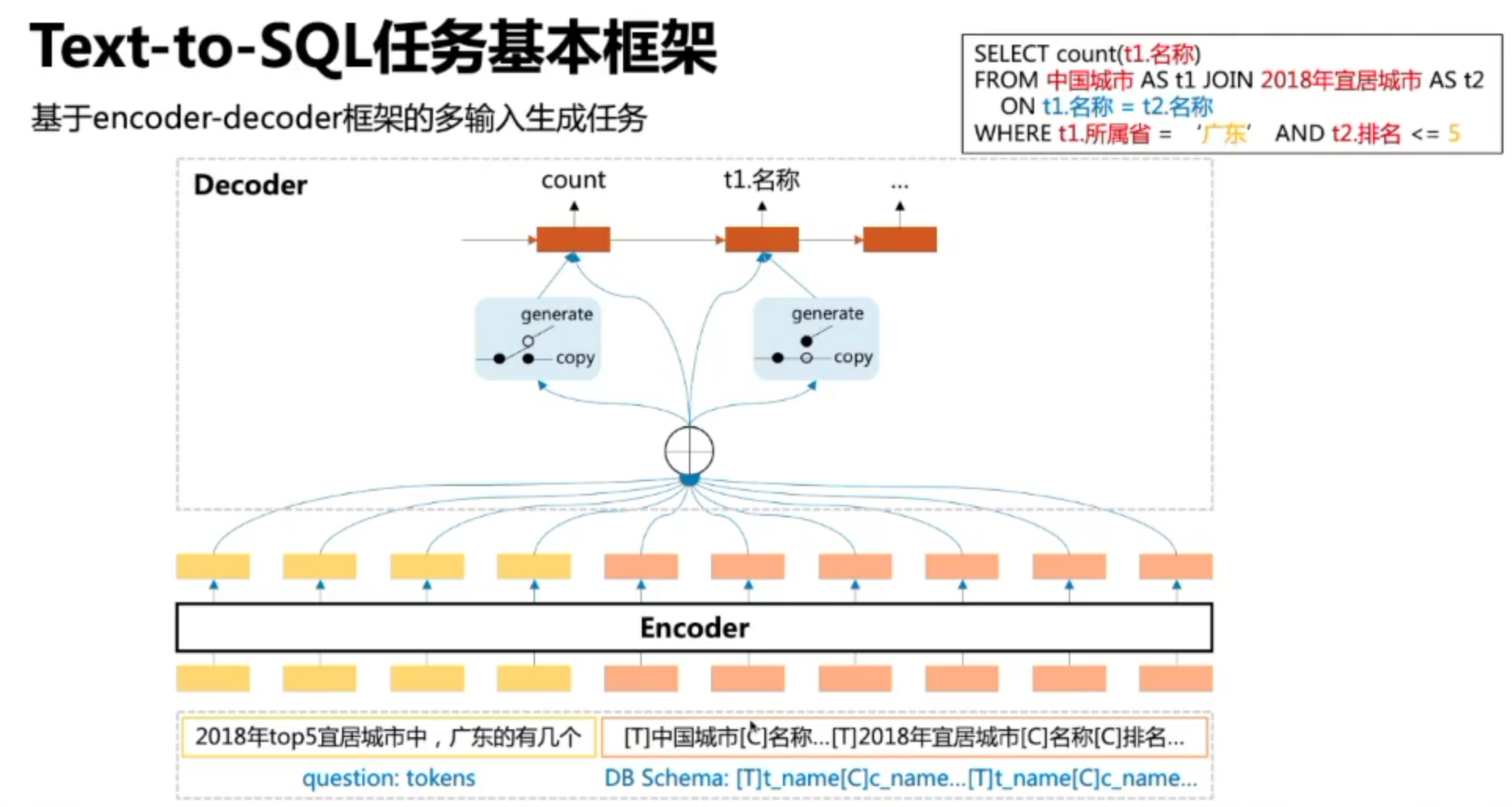
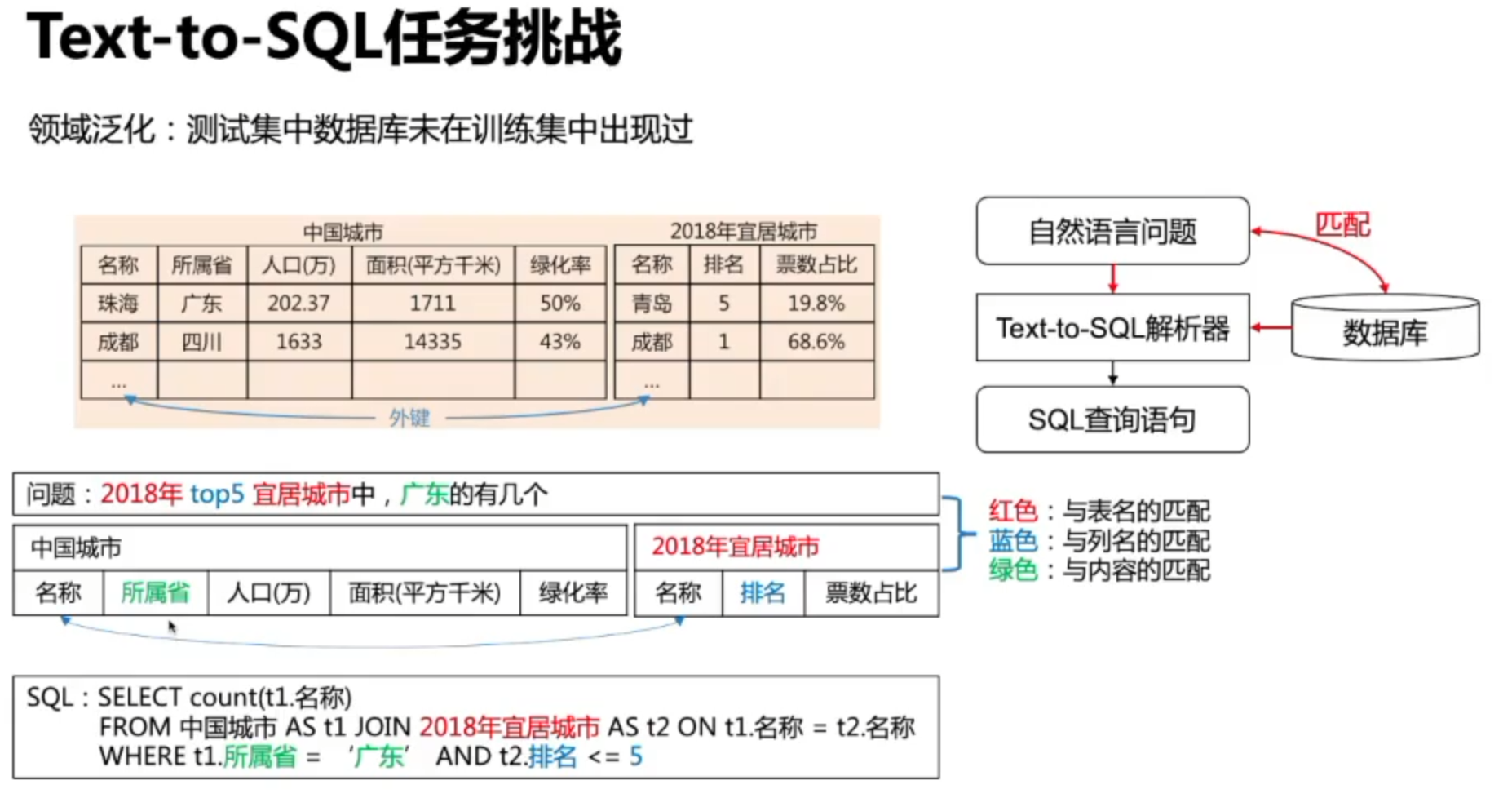
任务本质

数据库字段所使用的函数,是基于生成的,但是为了保证训练集中没有出现在测试集的字段都能学习,一般也会保留Copy选项,将输入字段中关键部分提取出来拷贝到输出字段。
任务挑战
 微信
微信 支付宝
支付宝

