
Spring+mvc+boot+maven+mybatis-plus
IDEA快捷键
Shift+Shift
- 功能:在整个项目中搜索匹配符合关键词的位置
- 亮点:Symbols支持模糊查询只要记住几个字母就能查询出位置
Ctrl+e 查看最近操作的文件
Alt + 7
- 功能:显示当前类的所有成员:方法、属性
- 亮点:显示当前类的继承关系,同时支持搜索功能快速定位到某个成员的位置上
Spring相关概念
初识Spring
在这一节,主要通过以下两个点来了解下Spring:
Spring家族
官网:https://spring.io,从官网我们可以大概了解到:
- Spring能做什么:用以开发web、微服务以及分布式系统等,光这三块就已经占了JavaEE开发的九成多。
- Spring并不是单一的一个技术,而是一个大家族,可以从官网的
Projects中查看其包含的所有技术。
Spring发展到今天已经形成了一种开发的生态圈,Spring提供了若干个项目,每个项目用于完成特定的功能。
Spring已形成了完整的生态圈,也就是说我们可以完全使用Spring技术完成整个项目的构建、设计与开发。
Spring有若干个项目,可以根据需要自行选择,把这些个项目组合起来,起了一个名称叫==全家桶==,如下图所示
说明:
图中的图标都代表什么含义,可以进入https://spring.io/projects网站进行对比查看。
这些技术并不是所有的都需要学习,额外需要重点关注Spring Framework、SpringBoot和SpringCloud:

- Spring Framework:Spring框架,是Spring中最早最核心的技术,也是所有其他技术的基础。
- SpringBoot:Spring是来简化开发,而SpringBoot是来帮助Spring在简化的基础上能更快速进行开发。
- SpringCloud:这个是用来做分布式之微服务架构的相关开发。
除了上面的这三个技术外,还有很多其他的技术,也比较流行,如SpringData,SpringSecurity等,这些都可以被应用在我们的项目中。我们今天所学习的Spring其实指的是==Spring Framework==。
Spring系统架构
前面我们说spring指的是Spring Framework,那么它其中都包含哪些内容以及我们该如何学习这个框架?
针对这些问题,我们将从系统架构图和课程学习路线来进行说明:
系统架构图
Spring Framework是Spring生态圈中最基础的项目,是其他项目的根基。
Spring Framework的发展也经历了很多版本的变更,每个版本都有相应的调整
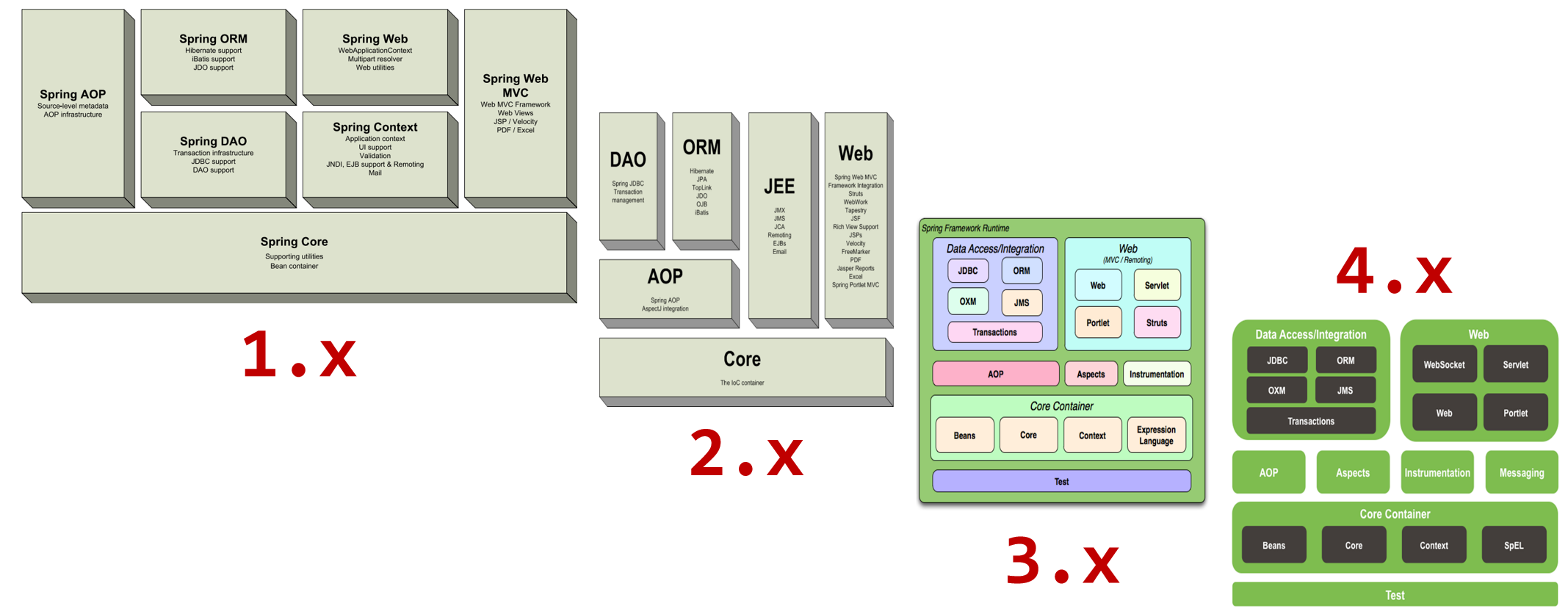
Spring Framework的5版本目前没有最新的架构图,而最新的是版本,所以接下来主要研究的是的架构图
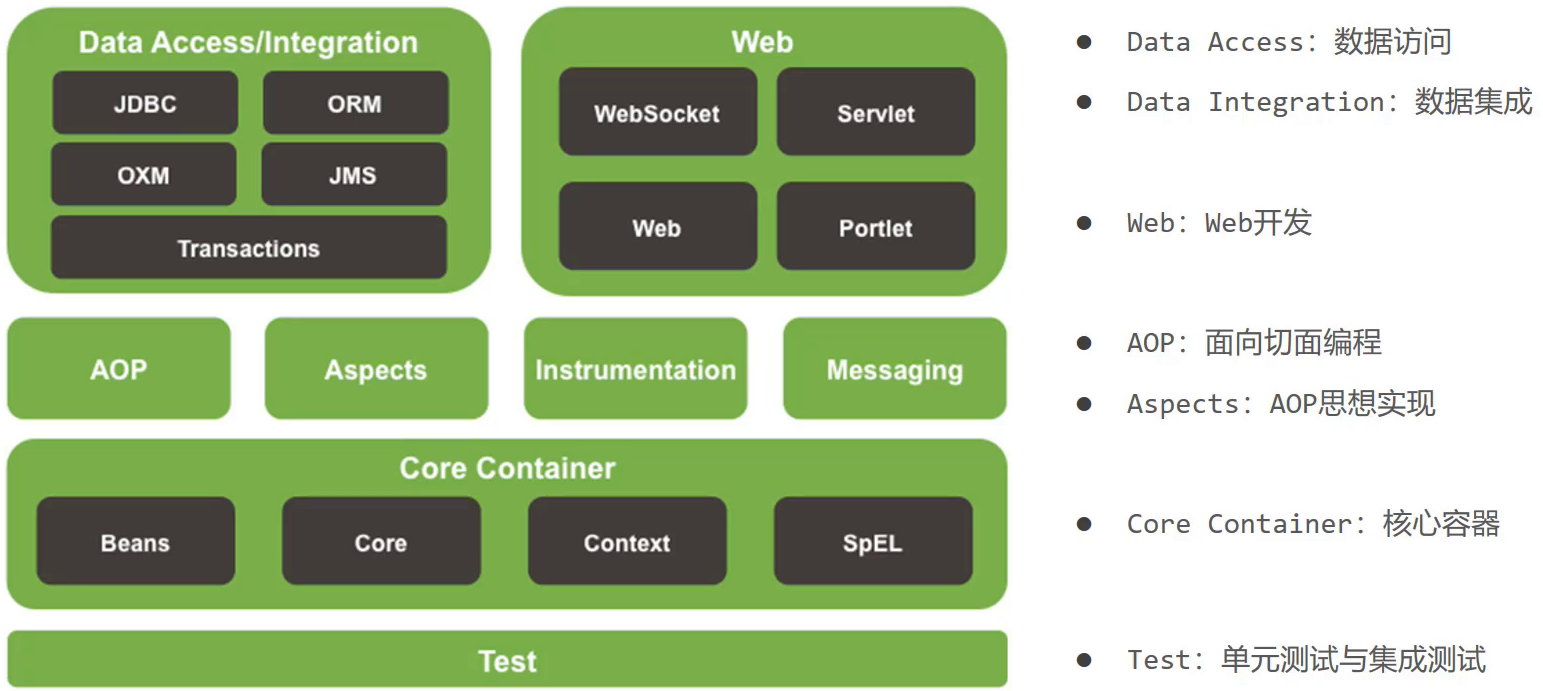
(1)核心层
- Core Container:核心容器,这个模块是Spring最核心的模块,其他的都需要依赖该模块
(2)AOP层
- AOP:面向切面编程,它依赖核心层容器,目的是==在不改变原有代码的前提下对其进行功能增强==
- Aspects:AOP是思想,Aspects是对AOP思想的具体实现
(3)数据层
- Data Access:数据访问,Spring全家桶中有对数据访问的具体实现技术
- Data Integration:数据集成,Spring支持整合其他的数据层解决方案,比如Mybatis
- Transactions:事务,Spring中事务管理是Spring AOP的一个具体实现,也是后期学习的重点内容
()Web层
- 这一层的内容将在SpringMVC框架具体学习
(5)Test层
- Spring主要整合了Junit来完成单元测试和集成测试
目前项目中的问题
要想解答这个问题,就需要先分析下目前咱们代码在编写过程中遇到的问题:

(1)业务层需要调用数据层的方法,就需要在业务层new数据层的对象
(2)如果数据层的实现类发生变化,那么业务层的代码也需要跟着改变,发生变更后,都需要进行编译打包和重部署
(3)所以,现在代码在编写的过程中存在的问题是:==耦合度偏高==
针对这个问题,该如何解决呢?

我们就想,如果能把框中的内容给去掉,不就可以降低依赖了么,但是又会引入新的问题,去掉以后程序能运行么?
答案肯定是不行,因为bookDao没有赋值为Null,强行运行就会出空指针异常。
所以现在的问题就是,业务层不想new对象,运行的时候又需要这个对象,该咋办呢?
针对这个问题,Spring就提出了一个解决方案:
- 使用对象时,在程序中不要主动使用new产生对象,转换为由==外部==提供对象
这种实现思就是Spring的一个核心概念
IOC、IOC容器、Bean、DI
- ==IOC(Inversion of Control)控制反转==
(1)什么是控制反转呢?
- 使用对象时,由主动new产生对象转换为由==外部==提供对象,此过程中对象创建控制权由程序转移到外部,此思想称为控制反转。
- 业务层要用数据层的类对象,以前是自己
new的 - 现在自己不new了,交给
别人[外部]来创建对象 别人[外部]就反转控制了数据层对象的创建权- 这种思想就是控制反转
- 别人[外部]指定是什么呢?继续往下学
- 业务层要用数据层的类对象,以前是自己
(2)Spring和IOC之间的关系是什么呢?
- Spring技术对IOC思想进行了实现
- Spring提供了一个容器,称为==IOC容器==,用来充当IOC思想中的”外部”
- IOC思想中的
别人[外部]指的就是Spring的IOC容器
(3)IOC容器的作用以及内部存放的是什么?
- IOC容器负责对象的创建、初始化等一系列工作,其中包含了数据层和业务层的类对象
- 被创建或被管理的对象在IOC容器中统称为==Bean==
- IOC容器中放的就是一个个的Bean对象
()当IOC容器中创建好service和dao对象后,程序能正确执行么?
- 不行,因为service运行需要依赖dao对象
- IOC容器中虽然有service和dao对象
- 但是service对象和dao对象没有任何关系
- 需要把dao对象交给service,也就是说要绑定service和dao对象之间的关系
像这种在容器中建立对象与对象之间的绑定关系就要用到DI:
- ==DI(Dependency Injection)依赖注入==

(1)什么是依赖注入呢?
- 在容器中建立bean与bean之间的依赖关系的整个过程,称为依赖注入
- 业务层要用数据层的类对象,以前是自己
new的 - 现在自己不new了,靠
别人[外部其实指的就是IOC容器]来给注入进来 - 这种思想就是依赖注入
- 业务层要用数据层的类对象,以前是自己
(2)IOC容器中哪些bean之间要建立依赖关系呢?
- 这个需要程序员根据业务需求提前建立好关系,如业务层需要依赖数据层,service就要和dao建立依赖关系
介绍完Spring的IOC和DI的概念后,我们会发现这两个概念的最终目标就是:==充分解耦==,具体实现靠:
- 使用IOC容器管理bean(IOC)
- 在IOC容器内将有依赖关系的bean进行关系绑定(DI)
- 最终结果为:使用对象时不仅可以直接从IOC容器中获取,并且获取到的bean已经绑定了所有的依赖关系.
小结
理解什么是IOC/DI思想、什么是IOC容器和什么是Bean:
(1)什么IOC/DI思想?
- IOC:控制反转,控制反转的是对象的创建权
- DI:依赖注入,绑定对象与对象之间的依赖关系
(2)什么是IOC容器?
Spring创建了一个容器用来存放所创建的对象,这个容器就叫IOC容器
(3)什么是Bean?
容器中所存放的一个个对象就叫Bean或Bean对象
IOC相关内容
通过前面两个案例,我们已经学习了bean如何定义配置,DI如何定义配置以及容器对象如何获取的内容,接下来主要是把这三块内容展开进行详细的讲解,深入的学习下这三部分的内容,首先是bean基础配置。
bean基础配置
对于bean的配置中,主要会讲解bean基础配置,bean的别名配置,bean的作用范围配置==(重点)==,这三部分内容:
bean基础配置(id与class)
对于bean的基础配置,在前面的案例中已经使用过:
1 | <bean id="" class=""/> |
其中,bean标签的功能、使用方式以及id和class属性的作用,我们通过一张图来描述下
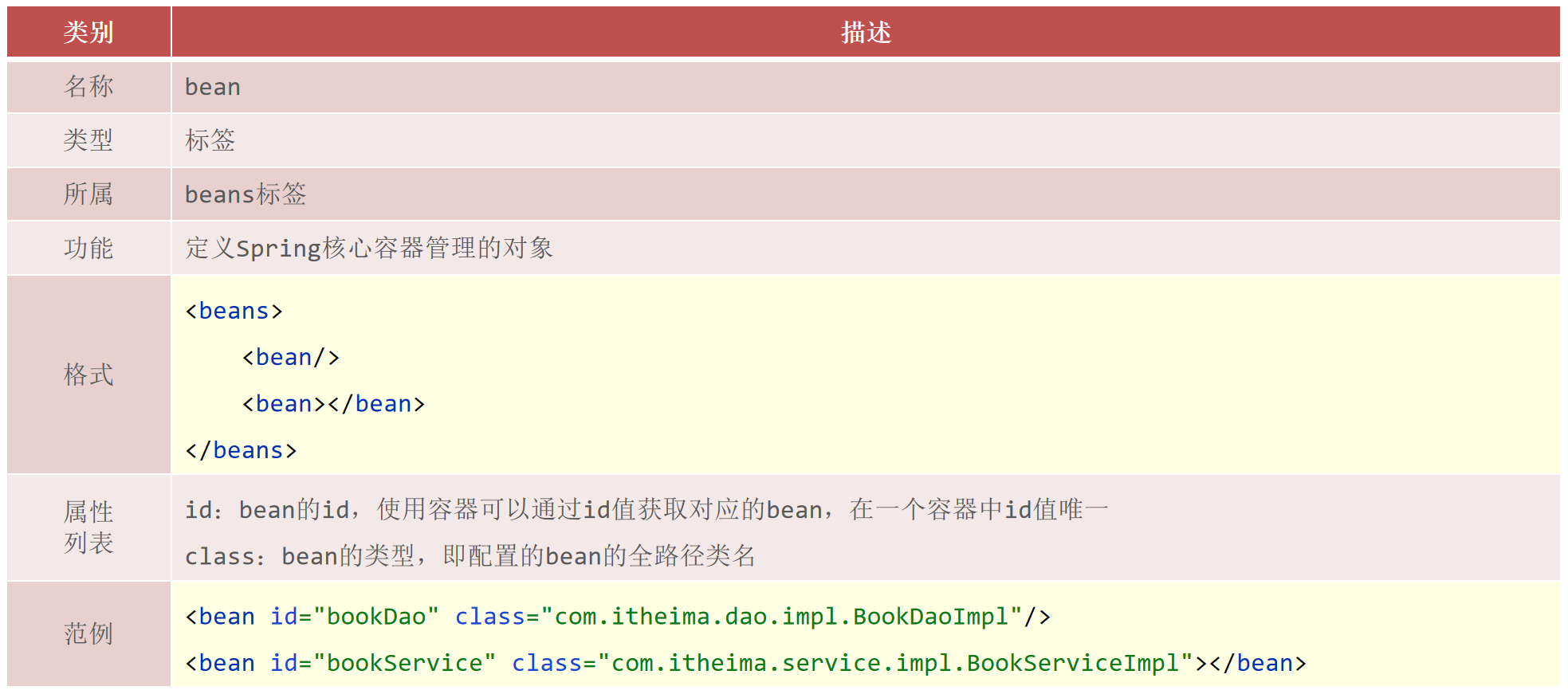
这其中需要大家重点掌握的是:==bean标签的id和class属性的使用==。
思考:
- class属性能不能写接口如
BookDao的类全名呢?
答案肯定是不行,因为接口是没办法创建对象的。
- 前面提过为bean设置id时,id必须唯一,但是如果由于命名习惯而产生了分歧后,该如何解决?
在解决这个问题之前,我们需要准备下开发环境,对于开发环境我们可以有两种解决方案:
使用前面IOC和DI的案例
重新搭建一个新的案例环境,目的是方便大家查阅代码
搭建的内容和前面的案例是一样的,内容如下:
bean的name属性
环境准备好后,接下来就可以在这个环境的基础上来学习下bean的别名配置,
首先来看下别名的配置说明:
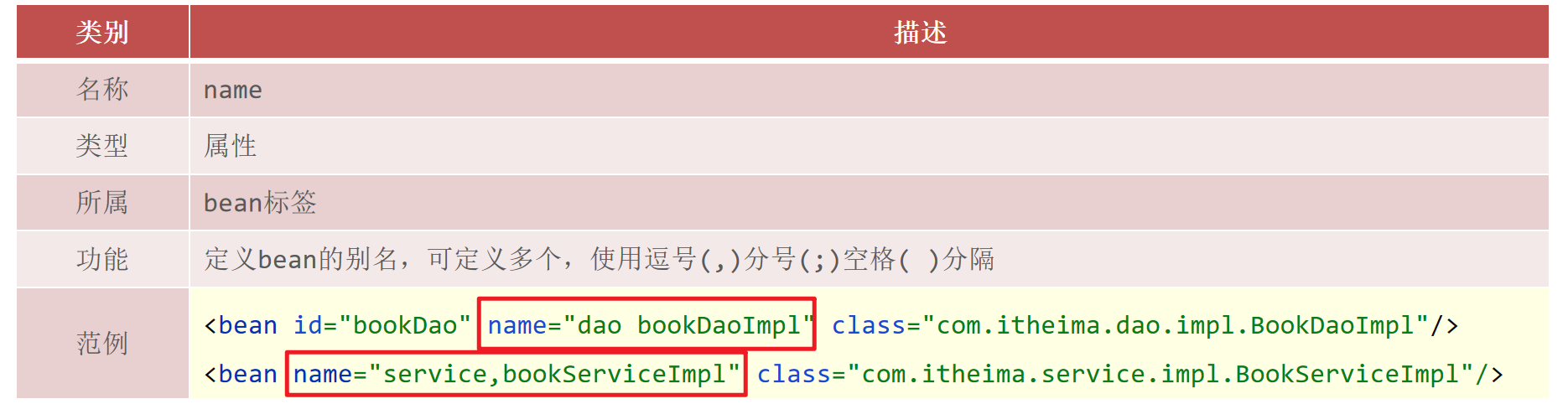
步骤1:配置别名
打开spring的配置文件applicationContext.xml
1 |
|
说明:Ebi全称Enterprise Business Interface,翻译为企业业务接口
步骤2:根据名称容器中获取bean对象
1 | public class AppForName { |
步骤3:运行程序
测试结果为:

==注意事项:==
bean依赖注入的ref属性指定bean,必须在容器中存在

如果不存在,则会报错,如下:

这个错误大家需要特别关注下:

获取bean无论是通过id还是name获取,如果无法获取到,将抛出异常==NoSuchBeanDefinitionException==
bean作用范围scope配置
关于bean的作用范围是bean属性配置的一个==重点==内容。
看到这个作用范围,我们就得思考bean的作用范围是来控制bean哪块内容的?
我们先来看下bean作用范围的配置属性:

验证IOC容器中对象是否为单例
验证思路
同一个bean获取两次,将对象打印到控制台,看打印出的地址值是否一致。
具体实现
创建一个AppForScope的类,在其main方法中来验证
1
2
3
4
5
6
7
8
9
10
11public class AppForScope {
public static void main(String[] args) {
ApplicationContext ctx = new
ClassPathXmlApplicationContext("applicationContext.xml");
BookDao bookDao1 = (BookDao) ctx.getBean("bookDao");
BookDao bookDao2 = (BookDao) ctx.getBean("bookDao");
System.out.println(bookDao1);
System.out.println(bookDao2);
}
}打印,观察控制台的打印结果

结论:默认情况下,Spring创建的bean对象都是单例的
获取到结论后,问题就来了,那如果我想创建出来非单例的bean对象,该如何实现呢?
配置bean为非单例
在Spring配置文件中,配置scope属性来实现bean的非单例创建
在Spring的配置文件中,修改
<bean>的scope属性1
<bean id="bookDao" name="dao" class="com.itheima.dao.impl.BookDaoImpl" scope=""/>
将scope设置为
singleton1
<bean id="bookDao" name="dao" class="com.itheima.dao.impl.BookDaoImpl" scope="singleton"/>
运行AppForScope,打印看结果
将scope设置为
prototype1
<bean id="bookDao" name="dao" class="com.itheima.dao.impl.BookDaoImpl" scope="prototype"/>
运行AppForScope,打印看结果

结论,使用bean的
scope属性可以控制bean的创建是否为单例:singleton默认为单例prototype为非单例
scope使用后续思考
介绍完scope属性以后,我们来思考几个问题:
- 为什么bean默认为单例?
- bean为单例的意思是在Spring的IOC容器中只会有该类的一个对象
- bean对象只有一个就避免了对象的频繁创建与销毁,达到了bean对象的复用,性能高
- bean在容器中是单例的,会不会产生线程安全问题?
- 如果对象是有状态对象,即该对象有成员变量可以用来存储数据的,
- 因为所有请求线程共用一个bean对象,所以会存在线程安全问题。
- 如果对象是无状态对象,即该对象没有成员变量没有进行数据存储的,
- 因方法中的局部变量在方法调用完成后会被销毁,所以不会存在线程安全问题。
- 哪些bean对象适合交给容器进行管理?
- 表现层对象
- 业务层对象
- 数据层对象
- 工具对象
- 哪些bean对象不适合交给容器进行管理?
- 封装实例的域对象,因为会引发线程安全问题,所以不适合。
bean基础配置小结
关于bean的基础配置中,需要大家掌握以下属性:

bean实例化
对象已经能交给Spring的IOC容器来创建了,但是容器是如何来创建对象的呢?
就需要研究下bean的实例化过程,在这块内容中主要解决两部分内容,分别是
- bean是如何创建的
- 实例化bean的三种方式,
构造方法,静态工厂和实例工厂
在讲解这三种创建方式之前,我们需要先确认一件事:
bean本质上就是对象,对象在new的时候会使用构造方法完成,那创建bean也是使用构造方法完成的。
基于这个知识点出发,我们来验证spring中bean的三种创建方式,
环境准备
为了方便大家阅读代码,重新准备个开发环境,
- 创建一个Maven项目
- pom.xml添加依赖
- resources下添加spring的配置文件applicationContext.xml
这些步骤和前面的都一致,大家可以快速的拷贝即可,最终项目的结构如下:

构造方法实例化
在上述的环境下,我们来研究下Spring中的第一种bean的创建方式构造方法实例化:
步骤1:准备需要被创建的类
准备一个BookDao和BookDaoImpl类
1 | public interface BookDao { |
步骤2:将类配置到Spring容器
1 |
|
步骤3:编写运行程序
1 | public class AppForInstanceBook { |
步骤:类中提供构造函数测试
在BookDaoImpl类中添加一个无参构造函数,并打印一句话,方便观察结果。
1 | public class BookDaoImpl implements BookDao { |
运行程序,如果控制台有打印构造函数中的输出,说明Spring容器在创建对象的时候也走的是构造函数

步骤5:将构造函数改成private测试
1 | public class BookDaoImpl implements BookDao { |
运行程序,能执行成功,说明内部走的依然是构造函数,能访问到类中的私有构造方法,显而易见Spring底层用的是反射
步骤6:构造函数中添加一个参数测试
1 | public class BookDaoImpl implements BookDao { |
运行程序,
程序会报错,说明Spring底层使用的是类的无参构造方法。
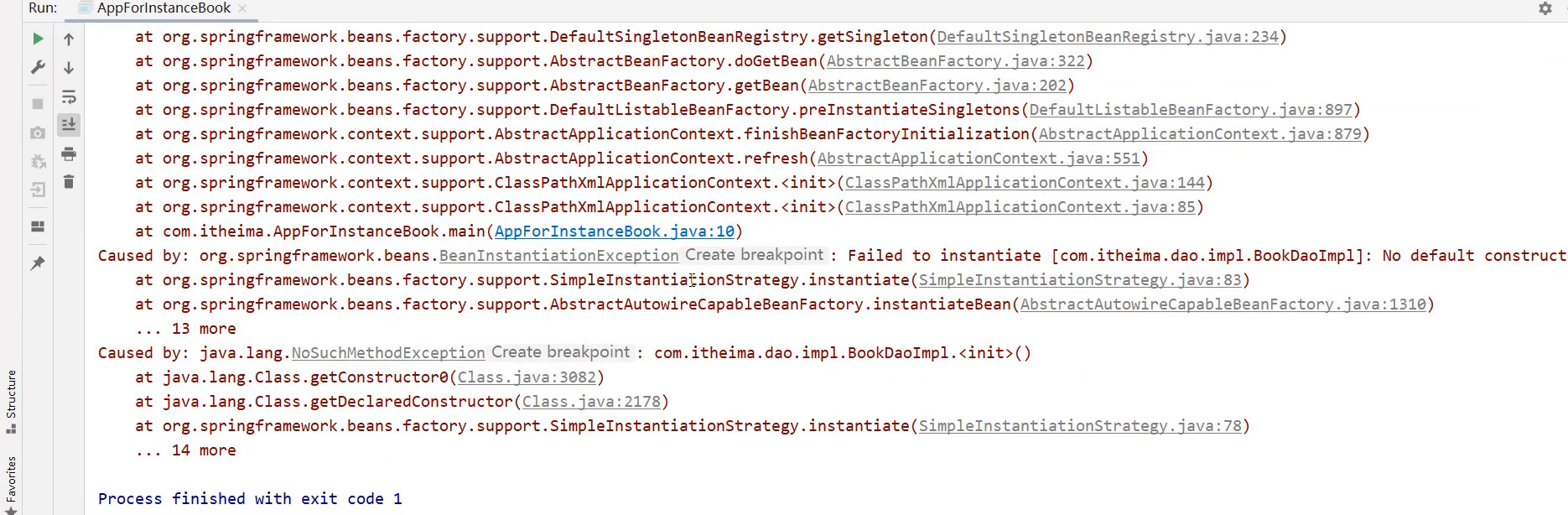
分析Spring的错误信息
接下来,我们主要研究下Spring的报错信息来学一学如阅读。
- 错误信息从下往上依次查看,因为上面的错误大都是对下面错误的一个包装,最核心错误是在最下面
- Caused by: java.lang.NoSuchMethodException: com.itheima.dao.impl.BookDaoImpl.
<init>()- Caused by 翻译为
引起,即出现错误的原因 - java.lang.NoSuchMethodException:抛出的异常为
没有这样的方法异常 - com.itheima.dao.impl.BookDaoImpl.
<init>():哪个类的哪个方法没有被找到导致的异常,<init>()指定是类的构造方法,即该类的无参构造方法
- Caused by 翻译为
如果最后一行错误获取不到错误信息,接下来查看第二层:
Caused by: org.springframework.beans.BeanInstantiationException: Failed to instantiate [com.itheima.dao.impl.BookDaoImpl]: No default constructor found; nested exception is java.lang.NoSuchMethodException: com.itheima.dao.impl.BookDaoImpl.<init>()
- nested:嵌套的意思,后面的异常内容和最底层的异常是一致的
- Caused by: org.springframework.beans.BeanInstantiationException: Failed to instantiate [com.itheima.dao.impl.BookDaoImpl]: No default constructor found;
- Caused by:
引发 - BeanInstantiationException:翻译为
bean实例化异常 - No default constructor found:没有一个默认的构造函数被发现
- Caused by:
看到这其实错误已经比较明显,给大家个练习,把倒数第三层的错误分析下吧:
Exception in thread “main” org.springframework.beans.factory.BeanCreationException: Error creating bean with name ‘bookDao’ defined in class path resource [applicationContext.xml]: Instantiation of bean failed; nested exception is org.springframework.beans.BeanInstantiationException: Failed to instantiate [com.itheima.dao.impl.BookDaoImpl]: No default constructor found; nested exception is java.lang.NoSuchMethodException: com.itheima.dao.impl.BookDaoImpl.<init>()。
至此,关于Spring的构造方法实例化就已经学习完了,因为每一个类默认都会提供一个无参构造函数,所以其实真正在使用这种方式的时候,我们什么也不需要做。这也是我们以后比较常用的一种方式。
静态工厂实例化
接下来研究Spring中的第二种bean的创建方式静态工厂实例化:
工厂方式创建bean
在讲这种方式之前,我们需要先回顾一个知识点是使用工厂来创建对象的方式:
(1)准备一个OrderDao和OrderDaoImpl类
1 | public interface OrderDao { |
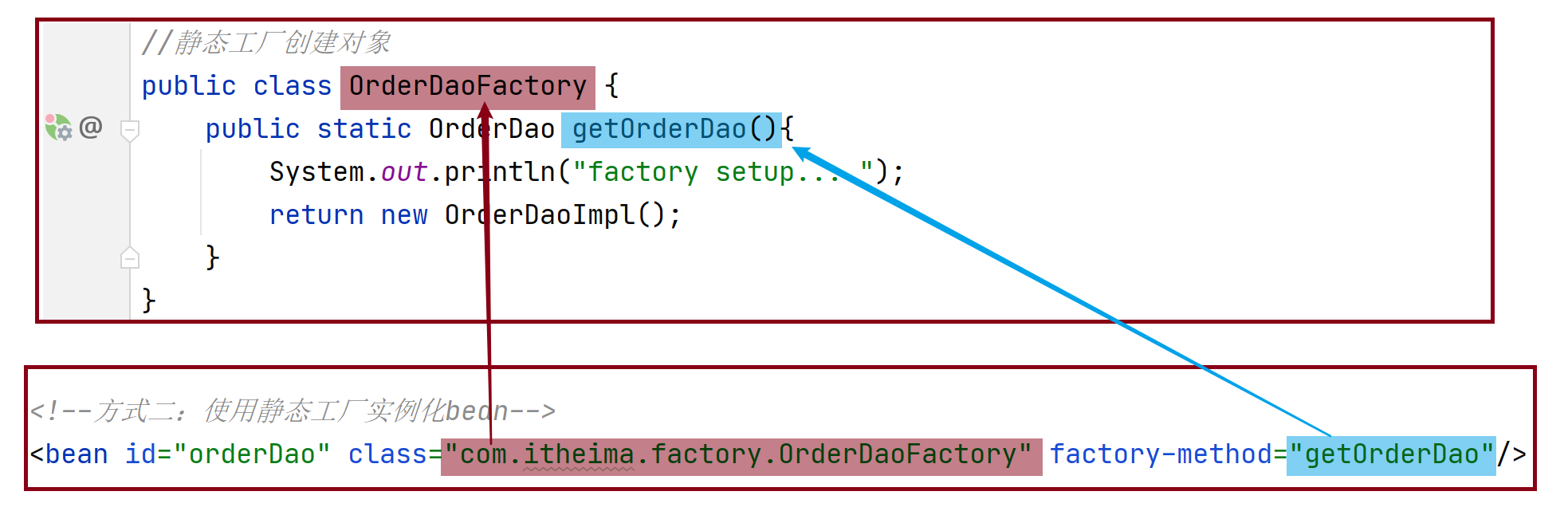
(2)创建一个工厂类OrderDaoFactory并提供一个==静态方法==
1 | //静态工厂创建对象 |
(3)编写AppForInstanceOrder运行类,在类中通过工厂获取对象
1 | public class AppForInstanceOrder { |
()运行后,可以查看到结果
如果代码中对象是通过上面的这种方式来创建的,如何将其交给Spring来管理呢?
静态工厂实例化
这就要用到Spring中的静态工厂实例化的知识了,具体实现步骤为:
(1)在spring的配置文件application.properties中添加以下内容:
1 | <bean id="orderDao" class="com.itheima.factory.OrderDaoFactory" factory-method="getOrderDao"/> |
class:工厂类的类全名
factory-mehod:具体工厂类中创建对象的方法名
对应关系如下图:
(2)在AppForInstanceOrder运行类,使用从IOC容器中获取bean的方法进行运行测试
1 | public class AppForInstanceOrder { |
(3)运行后,可以查看到结果
看到这,可能有人会问了,你这种方式在工厂类中不也是直接new对象的,和我自己直接new没什么太大的区别,而且静态工厂的方式反而更复杂,这种方式的意义是什么?
主要的原因是:
- 在工厂的静态方法中,我们除了new对象还可以做其他的一些业务操作,这些操作必不可少,如:
1 | public class OrderDaoFactory { |
之前new对象的方式就无法添加其他的业务内容,重新运行,查看结果:

介绍完静态工厂实例化后,这种方式一般是用来兼容早期的一些老系统,所以==了解为主==。
实例工厂与FactoryBean
接下来继续来研究Spring的第三种bean的创建方式实例工厂实例化:
环境准备
(1)准备一个UserDao和UserDaoImpl类
1 | public interface UserDao { |
(2)创建一个工厂类OrderDaoFactory并提供一个普通方法,注意此处和静态工厂的工厂类不一样的地方是方法不是静态方法
1 | public class UserDaoFactory { |
(3)编写AppForInstanceUser运行类,在类中通过工厂获取对象
1 | public class AppForInstanceUser { |
(4)运行后,可以查看到结果

对于上面这种实例工厂的方式如何交给Spring管理呢?
实例工厂实例化
具体实现步骤为:
(1)在spring的配置文件中添加以下内容:
1 | <bean id="userFactory" class="com.itheima.factory.UserDaoFactory"/> |
实例化工厂运行的顺序是:
创建实例化工厂对象,对应的是第一行配置
调用对象中的方法来创建bean,对应的是第二行配置
factory-bean:工厂的实例对象
factory-method:工厂对象中的具体创建对象的方法名,对应关系如下:
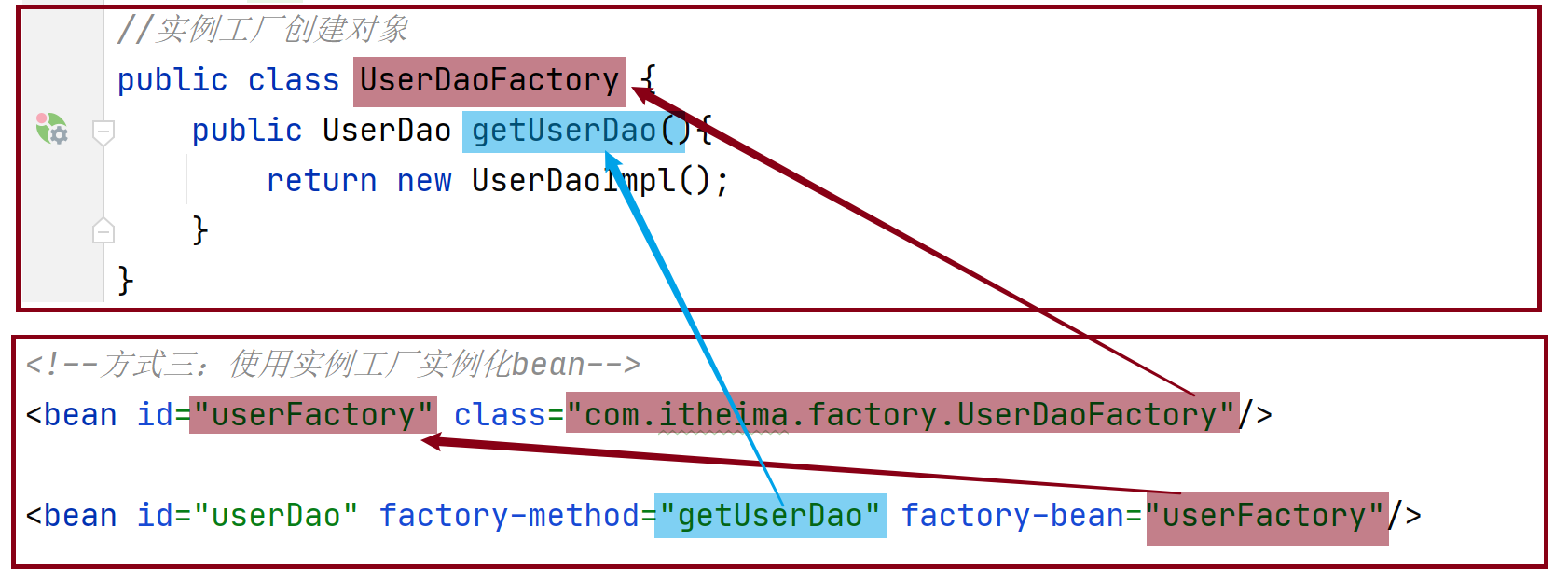
factory-mehod:具体工厂类中创建对象的方法名
(2)在AppForInstanceUser运行类,使用从IOC容器中获取bean的方法进行运行测试
1 | public class AppForInstanceUser { |
(3)运行后,可以查看到结果

实例工厂实例化的方式就已经介绍完了,配置的过程还是比较复杂,所以Spring为了简化这种配置方式就提供了一种叫FactoryBean的方式来简化开发。
FactoryBean的使用
具体的使用步骤为:
(1)创建一个UserDaoFactoryBean的类,实现FactoryBean接口,重写接口的方法
1 | public class UserDaoFactoryBean implements FactoryBean<UserDao> { |
(2)在Spring的配置文件中进行配置
1 | <bean id="userDao" class="com.itheima.factory.UserDaoFactoryBean"/> |
(3)AppForInstanceUser运行类不用做任何修改,直接运行

这种方式在Spring去整合其他框架的时候会被用到,所以这种方式需要大家理解掌握。
查看源码会发现,FactoryBean接口其实会有三个方法,分别是:
1 | T getObject() throws Exception; |
方法一:getObject(),被重写后,在方法中进行对象的创建并返回
方法二:getObjectType(),被重写后,主要返回的是被创建类的Class对象
方法三:没有被重写,因为它已经给了默认值,从方法名中可以看出其作用是设置对象是否为单例,默认true,从意思上来看,我们猜想默认应该是单例,如何来验证呢?
思路很简单,就是从容器中获取该对象的多个值,打印到控制台,查看是否为同一个对象。
1 | public class AppForInstanceUser { |
打印结果,如下:
通过验证,会发现默认是单例,那如果想改成单例具体如何实现?
只需要将isSingleton()方法进行重写,修改返回为false,即可
1 | //FactoryBean创建对象 |
重新运行AppForInstanceUser,查看结果

从结果中可以看出现在已经是非单例了,但是一般情况下我们都会采用单例,也就是采用默认即可。所以isSingleton()方法一般不需要进行重写。
bean实例化小结
通过这一节的学习,需要掌握:
(1)bean是如何创建的呢?
1 | 构造方法 |
(2)Spring的IOC实例化对象的三种方式分别是:
- 构造方法(常用)
- 静态工厂(了解)
- 实例工厂(了解)
- FactoryBean(实用)
这些方式中,重点掌握构造方法和FactoryBean即可。
需要注意的一点是,构造方法在类中默认会提供,但是如果重写了构造方法,默认的就会消失,在使用的过程中需要注意,如果需要重写构造方法,最好把默认的构造方法也重写下。
DI相关内容
前面我们已经完成了bean相关操作的讲解,接下来就进入第二个大的模块DI依赖注入,首先来介绍下Spring中有哪些注入方式?
- 向一个类中传递数据的方式有几种?
- 普通方法(set方法)
- 构造方法
- 依赖注入描述了在容器中建立bean与bean之间的依赖关系的过程,如果bean运行需要的是数字或字符串呢?
- 引用类型
- 简单类型(基本数据类型与String)
Spring就是基于上面这些知识点,为我们提供了两种注入方式,分别是:
- setter注入
- 简单类型
- ==引用类型==
- 构造器注入
- 简单类型
- 引用类型
setter注入
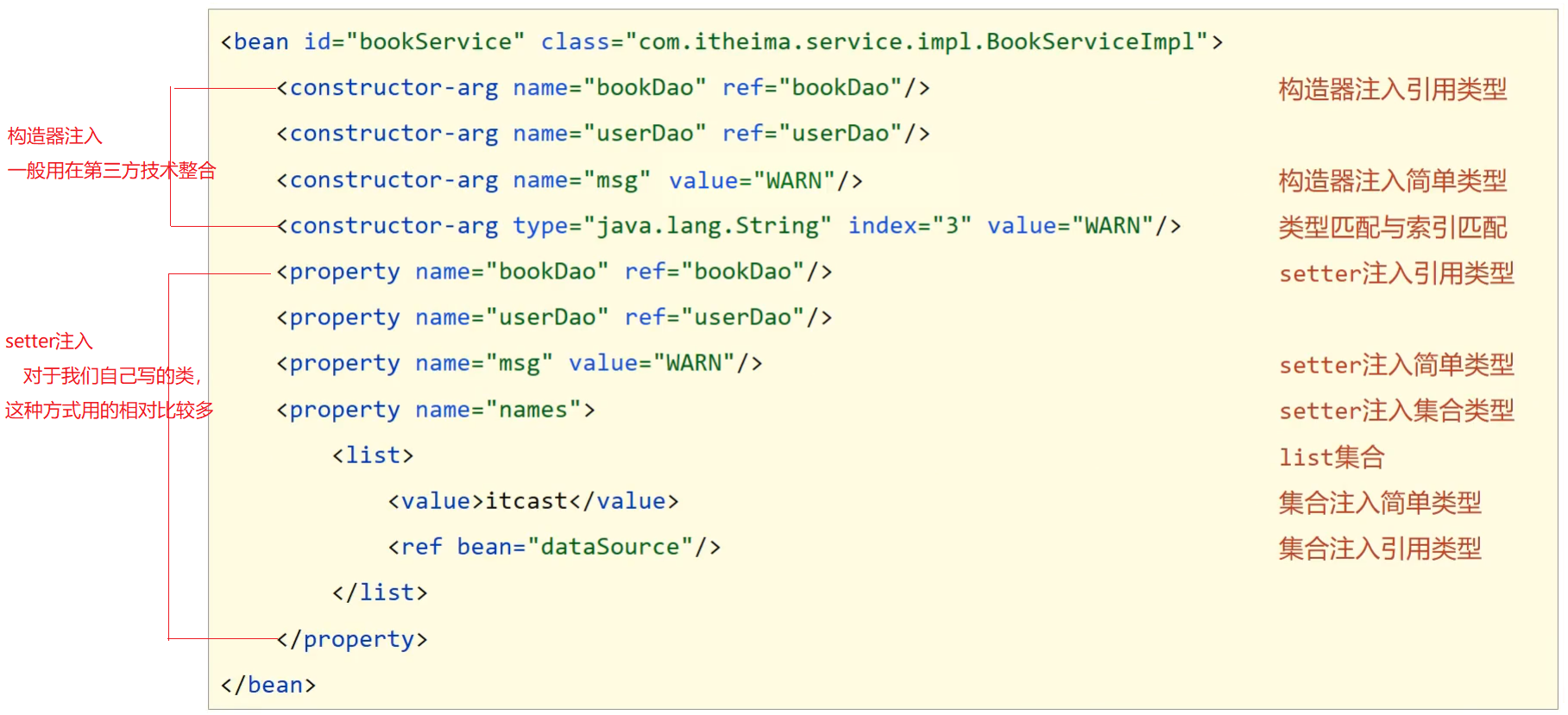
- 对于setter方式注入引用类型的方式之前已经学习过,快速回顾下:
- 在bean中定义引用类型属性,并提供可访问的==set==方法
1 | public class BookServiceImpl implements BookService { |
- 配置中使用==property==标签==ref==属性注入引用类型对象
1 | <bean id="bookService" class="com.itheima.service.impl.BookServiceImpl"> |
自动配置
前面花了大量的时间把Spring的注入去学习了下,总结起来就一个字==麻烦==。
问:麻烦在哪?
答:配置文件的编写配置上。
问:有更简单方式么?
答:有,自动配置
什么是自动配置以及如何实现自动配置,就是接下来要学习的内容:
什么是依赖自动装配?
- IoC容器根据bean所依赖的资源在容器中自动查找并注入到bean中的过程称为自动装配
自动装配方式有哪些?
- ==按类型(常用)==
- 按名称
- 按构造方法
- 不启用自动装配
准备下案例环境
- 创建一个Maven项目
- pom.xml添加依赖
- resources下添加spring的配置文件
这些步骤和前面的都一致,大家可以快速的拷贝即可,最终项目的结构如下:

(1)项目中添加BookDao、BookDaoImpl、BookService和BookServiceImpl类
1 | public interface BookDao { |
(2)resources下提供spring的配置文件
1 |
|
(3)编写AppForAutoware运行类,加载Spring的IOC容器,并从中获取对应的bean对象
1 | public class AppForAutoware { |
完成自动装配的配置
接下来,在上面这个环境中来完成自动装配的学习:
自动装配只需要修改applicationContext.xml配置文件即可:
(1)将<property>标签删除
(2)在<bean>标签中添加autowire属性
首先来实现按照类型注入的配置
1 |
|
==注意事项:==
- 需要注入属性的类中对应属性的setter方法不能省略
- 被注入的对象必须要被Spring的IOC容器管理
- 按照类型在Spring的IOC容器中如果找到多个对象,会报
NoUniqueBeanDefinitionException
一个类型在IOC中有多个对象,还想要注入成功,这个时候就需要按照名称注入,配置方式为:
1 |
|
==注意事项:==
按照名称注入中的名称指的是什么?

- bookDao是private修饰的,外部类无法直接方法
- 外部类只能通过属性的set方法进行访问
- 对外部类来说,setBookDao方法名,去掉set后首字母小写是其属性名
- 为什么是去掉set首字母小写?
- 这个规则是set方法生成的默认规则,set方法的生成是把属性名首字母大写前面加set形成的方法名
- 所以按照名称注入,其实是和对应的set方法有关,但是如果按照标准起名称,属性名和set对应的名是一致的
如果按照名称去找对应的bean对象,找不到则注入Null
当某一个类型在IOC容器中有多个对象,按照名称注入只找其指定名称对应的bean对象,不会报错
两种方式介绍完后,以后用的更多的是==按照类型==注入。
最后对于依赖注入,需要注意一些其他的配置特征:
- 自动装配用于引用类型依赖注入,不能对简单类型进行操作
- 使用按类型装配时(byType)必须保障容器中相同类型的bean唯一,推荐使用
- 使用按名称装配时(byName)必须保障容器中具有指定名称的bean,因变量名与配置耦合,不推荐使用
- 自动装配优先级低于setter注入与构造器注入,同时出现时自动装配配置失效
加载properties文件
本节主要讲解的是properties配置文件的加载,需要掌握的内容有:
如何开启
context命名空间
如何加载properties配置文件
1
<context:property-placeholder location="" system-properties-mode="NEVER"/>
如何在applicationContext.xml引入properties配置文件中的值
1
${key}
核心容器
前面已经完成bean与依赖注入的相关知识学习,接下来我们主要学习的是IOC容器中的==核心容器==。
这里所说的核心容器,大家可以把它简单的理解为ApplicationContext,前面虽然已经用到过,但是并没有系统的学习,接下来咱们从以下几个问题入手来学习下容器的相关知识:
- 如何创建容器?
- 创建好容器后,如何从容器中获取bean对象?
- 容器类的层次结构是什么?
- BeanFactory是什么?
这节中没有新的知识点,只是对前面知识的一个大总结,共包含如下内容:
容器相关
- BeanFactory是IoC容器的顶层接口,初始化BeanFactory对象时,加载的bean延迟加载
- ApplicationContext接口是Spring容器的核心接口,初始化时bean立即加载
- ApplicationContext接口提供基础的bean操作相关方法,通过其他接口扩展其功能
- ApplicationContext接口常用初始化类
- ==ClassPathXmlApplicationContext(常用)==
- FileSystemXmlApplicationContext
bean相关

其实整个配置中最常用的就两个属性==id==和==class==。
把scope、init-method、destroy-method框起来的原因是,后面注解在讲解的时候还会用到,所以大家对这三个属性关注下。
依赖注入相关
IOC/DI注解开发
Spring的IOC/DI对应的配置开发就已经讲解完成,但是使用起来相对来说还是比较复杂的,复杂的地方在==配置文件==。
前面咱们聊Spring的时候说过,Spring可以简化代码的开发,到现在并没有体会到。
所以Spring到底是如何简化代码开发的呢?
要想真正简化开发,就需要用到Spring的注解开发,Spring对注解支持的版本历程:
- 2.0版开始支持注解
- 2.5版注解功能趋于完善
- 3.0版支持纯注解开发
关于注解开发,我们会讲解两块内容注解开发定义bean和纯注解开发。
注解开发定义bean用的是2.5版提供的注解,纯注解开发用的是3.0版提供的注解。
1 环境准备
在学习注解开发之前,先来准备下案例环境:
创建一个Maven项目
pom.xml添加Spring的依赖
1
2
3
4
5
6
7<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
</dependencies>resources下添加applicationContext.xml
1
2
3
4
5
6
7
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="bookDao" class="com.itheima.dao.impl.BookDaoImpl"/>
</beans>添加BookDao、BookDaoImpl、BookService、BookServiceImpl类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public interface BookDao {
public void save();
}
public class BookDaoImpl implements BookDao {
public void save() {
System.out.println("book dao save ..." );
}
}
public interface BookService {
public void save();
}
public class BookServiceImpl implements BookService {
public void save() {
System.out.println("book service save ...");
}
}创建运行类App
1
2
3
4
5
6
7public class App {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
BookDao bookDao = (BookDao) ctx.getBean("bookDao");
bookDao.save();
}
}
最终创建好的项目结构如下:

2 注解开发定义bean
在上述环境的基础上,我们来学一学Spring是如何通过注解实现bean的定义开发?
步骤1:删除原XML配置
将配置文件中的<bean>标签删除掉
1 | <bean id="bookDao" class="com.itheima.dao.impl.BookDaoImpl"/> |
步骤2:Dao上添加注解
在BookDaoImpl类上添加@Component注解
1 |
|
==注意:@Component注解不可以添加在接口上,因为接口是无法创建对象的。==
XML与注解配置的对应关系:

步骤3:配置Spring的注解包扫描
为了让Spring框架能够扫描到写在类上的注解,需要在配置文件上进行包扫描
1 |
|
说明:
component-scan
- component:组件,Spring将管理的bean视作自己的一个组件
- scan:扫描
base-package指定Spring框架扫描的包路径,它会扫描指定包及其子包中的所有类上的注解。
- 包路径越多[如:com.itheima.dao.impl],扫描的范围越小速度越快
- 包路径越少[如:com.itheima],扫描的范围越大速度越慢
- 一般扫描到项目的组织名称即Maven的groupId下[如:com.itheima]即可。
步骤4:运行程序
运行App类查看打印结果
步骤5:Service上添加注解
在BookServiceImpl类上也添加@Component交给Spring框架管理
1 |
|
步骤6:运行程序
在App类中,从IOC容器中获取BookServiceImpl对应的bean对象,打印
1 | public class App { |
打印观察结果,两个bean对象都已经打印到控制台

说明:
BookServiceImpl类没有起名称,所以在App中是按照类型来获取bean对象
@Component注解如果不起名称,会有一个默认值就是
当前类名首字母小写,所以也可以按照名称获取,如1
2BookService bookService = (BookService)ctx.getBean("bookServiceImpl");
System.out.println(bookService);
对于@Component注解,还衍生出了其他三个注解@Controller、@Service、@Repository
通过查看源码会发现:

这三个注解和@Component注解的作用是一样的,为什么要衍生出这三个呢?
方便我们后期在编写类的时候能很好的区分出这个类是属于表现层、业务层还是数据层的类。
知识点1:@Component等
| 名称 | @Component/@Controller/@Service/@Repository |
|---|---|
| 类型 | 类注解 |
| 位置 | 类定义上方 |
| 作用 | 设置该类为spring管理的bean |
| 属性 | value(默认):定义bean的id |
3 纯注解开发模式
上面已经可以使用注解来配置bean,但是依然有用到配置文件,在配置文件中对包进行了扫描,Spring在3.0版已经支持纯注解开发
- Spring3.0开启了纯注解开发模式,使用Java类替代配置文件,开启了Spring快速开发赛道
具体如何实现?
1 思路分析
实现思路为:
- 将配置文件applicationContext.xml删除掉,使用类来替换。
2 实现步骤
步骤1:创建配置类
创建一个配置类SpringConfig
1 | public class SpringConfig { |
步骤2:标识该类为配置类
在配置类上添加@Configuration注解,将其标识为一个配置类,替换applicationContext.xml
1 |
|
步骤3:用注解替换包扫描配置
在配置类上添加包扫描注解@ComponentScan替换<context:component-scan base-package=""/>
1 |
|
步骤4:创建运行类并执行
创建一个新的运行类AppForAnnotation
1 | public class AppForAnnotation { |
运行AppForAnnotation,可以看到两个对象依然被获取成功

至此,纯注解开发的方式就已经完成了,主要内容包括:
Java类替换Spring核心配置文件
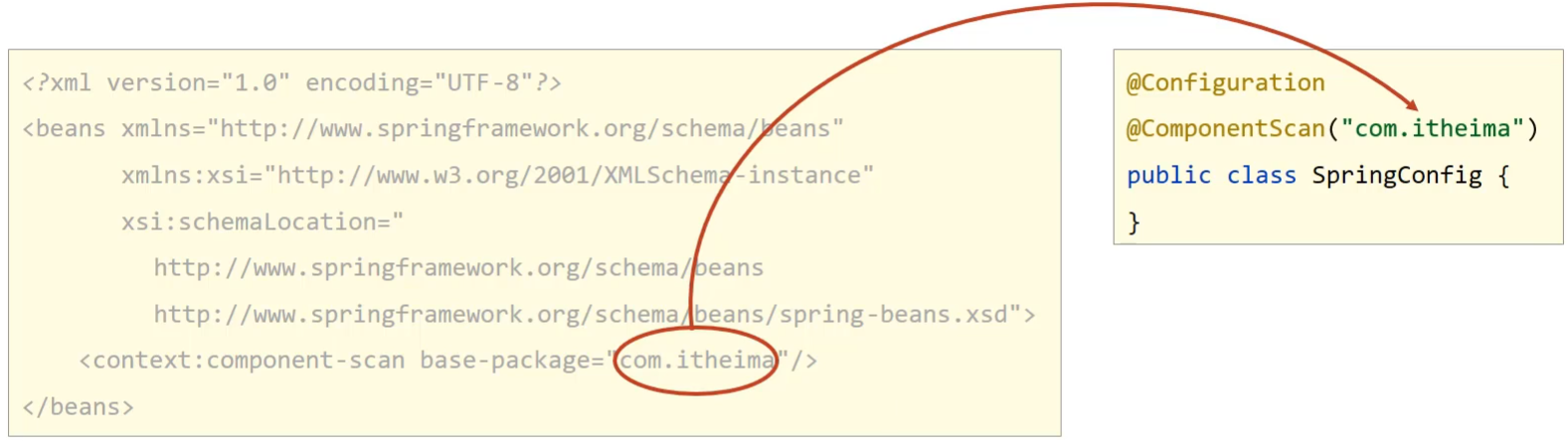
@Configuration注解用于设定当前类为配置类
@ComponentScan注解用于设定扫描路径,此注解只能添加一次,多个数据请用数组格式
1
@ComponentScan({com.itheima.service","com.itheima.dao"})
读取Spring核心配置文件初始化容器对象切换为读取Java配置类初始化容器对象
1
2
3
4//加载配置文件初始化容器
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
//加载配置类初始化容器
ApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);
知识点1:@Configuration
| 名称 | @Configuration |
|---|---|
| 类型 | 类注解 |
| 位置 | 类定义上方 |
| 作用 | 设置该类为spring配置类 |
| 属性 | value(默认):定义bean的id |
知识点2:@ComponentScan
| 名称 | @ComponentScan |
|---|---|
| 类型 | 类注解 |
| 位置 | 类定义上方 |
| 作用 | 设置spring配置类扫描路径,用于加载使用注解格式定义的bean |
| 属性 | value(默认):扫描路径,此路径可以逐层向下扫描 |
小结:
这一节重点掌握的是使用注解完成Spring的bean管理,需要掌握的内容为:
- 记住@Component、@Controller、@Service、@Repository这四个注解
- applicationContext.xml中
<context:component-san/>的作用是指定扫描包路径,注解为@ComponentScan - @Configuration标识该类为配置类,使用类替换applicationContext.xml文件
- ClassPathXmlApplicationContext是加载XML配置文件
- AnnotationConfigApplicationContext是加载配置类
4 注解开发bean作用范围与生命周期管理
使用注解已经完成了bean的管理,接下来按照前面所学习的内容,将通过配置实现的内容都换成对应的注解实现,包含两部分内容:bean作用范围和bean生命周期。
1 环境准备
老规矩,学习之前先来准备环境:
创建一个Maven项目
pom.xml添加Spring的依赖
1
2
3
4
5
6
7<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
</dependencies>添加一个配置类
SpringConfig1
2
3
4
public class SpringConfig {
}添加BookDao、BookDaoImpl类
1
2
3
4
5
6
7
8
9public interface BookDao {
public void save();
}
public class BookDaoImpl implements BookDao {
public void save() {
System.out.println("book dao save ..." );
}
}创建运行类App
1
2
3
4
5
6
7
8
9public class App {
public static void main(String[] args) {
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);
BookDao bookDao1 = ctx.getBean(BookDao.class);
BookDao bookDao2 = ctx.getBean(BookDao.class);
System.out.println(bookDao1);
System.out.println(bookDao2);
}
}
最终创建好的项目结构如下:

2 Bean的作用范围
(1)先运行App类,在控制台打印两个一摸一样的地址,说明默认情况下bean是单例
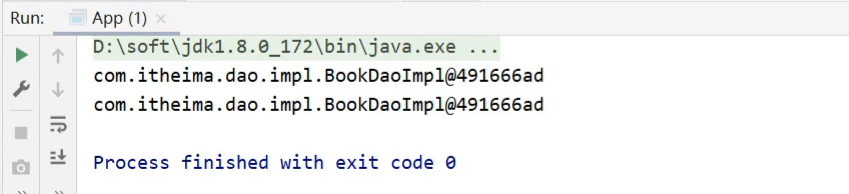
(2)要想将BookDaoImpl变成非单例,只需要在其类上添加@scope注解
1 |
|
再次执行App类,打印结果:
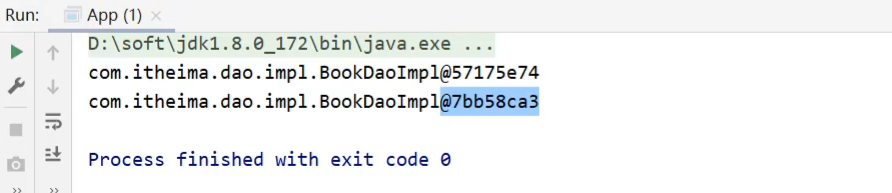
知识点1:@Scope
| 名称 | @Scope |
|---|---|
| 类型 | 类注解 |
| 位置 | 类定义上方 |
| 作用 | 设置该类创建对象的作用范围 可用于设置创建出的bean是否为单例对象 |
| 属性 | value(默认):定义bean作用范围, ==默认值singleton(单例),可选值prototype(非单例)== |
3 Bean的生命周期
(1)在BookDaoImpl中添加两个方法,init和destroy,方法名可以任意
1 |
|
(2)如何对方法进行标识,哪个是初始化方法,哪个是销毁方法?
只需要在对应的方法上添加@PostConstruct和@PreDestroy注解即可。
1 |
|
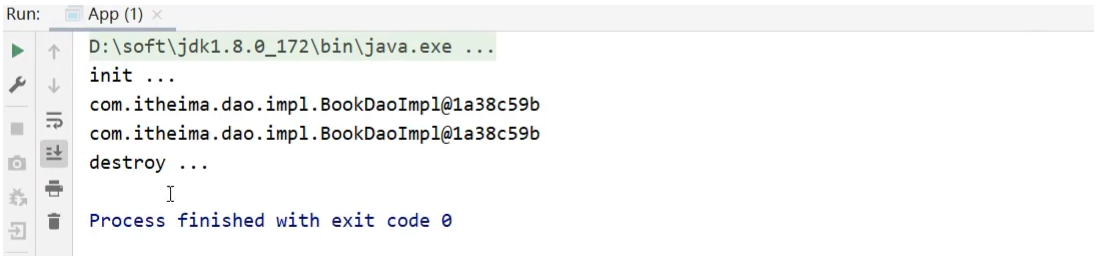
(3)要想看到两个方法执行,需要注意的是destroy只有在容器关闭的时候,才会执行,所以需要修改App的类
1 | public class App { |
(4)运行App,类查看打印结果,证明init和destroy方法都被执行了。
==注意:@PostConstruct和@PreDestroy注解如果找不到,需要导入下面的jar包==
1 | <dependency> |
找不到的原因是,从JDK9以后jdk中的javax.annotation包被移除了,这两个注解刚好就在这个包中。
知识点1:@PostConstruct
| 名称 | @PostConstruct |
|---|---|
| 类型 | 方法注解 |
| 位置 | 方法上 |
| 作用 | 设置该方法为初始化方法 |
| 属性 | 无 |
知识点2:@PreDestroy
| 名称 | @PreDestroy |
|---|---|
| 类型 | 方法注解 |
| 位置 | 方法上 |
| 作用 | 设置该方法为销毁方法 |
| 属性 | 无 |
小结

5 注解开发依赖注入
Spring为了使用注解简化开发,并没有提供构造函数注入、setter注入对应的注解,只提供了自动装配的注解实现。
1 环境准备
在学习之前,把案例环境介绍下:
创建一个Maven项目
pom.xml添加Spring的依赖
1
2
3
4
5
6
7<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
</dependencies>添加一个配置类
SpringConfig1
2
3
4
public class SpringConfig {
}添加BookDao、BookDaoImpl、BookService、BookServiceImpl类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public interface BookDao {
public void save();
}
public class BookDaoImpl implements BookDao {
public void save() {
System.out.println("book dao save ..." );
}
}
public interface BookService {
public void save();
}
public class BookServiceImpl implements BookService {
private BookDao bookDao;
public void setBookDao(BookDao bookDao) {
this.bookDao = bookDao;
}
public void save() {
System.out.println("book service save ...");
bookDao.save();
}
}创建运行类App
1
2
3
4
5
6
7public class App {
public static void main(String[] args) {
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);
BookService bookService = ctx.getBean(BookService.class);
bookService.save();
}
}
最终创建好的项目结构如下:

环境准备好后,运行后会发现有问题
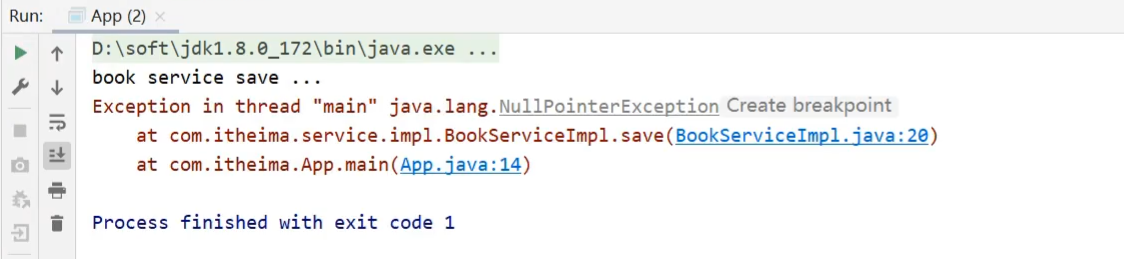
出现问题的原因是,在BookServiceImpl类中添加了BookDao的属性,并提供了setter方法,但是目前是没有提供配置注入BookDao的,所以bookDao对象为Null,调用其save方法就会报控指针异常。
2 注解实现按照类型注入
对于这个问题使用注解该如何解决?
(1) 在BookServiceImpl类的bookDao属性上添加@Autowired注解
1 |
|
注意:
- @Autowired可以写在属性上,也可也写在setter方法上,最简单的处理方式是
写在属性上并将setter方法删除掉 - 为什么setter方法可以删除呢?
- 自动装配基于反射设计创建对象并通过暴力反射为私有属性进行设值
- 普通反射只能获取public修饰的内容
- 暴力反射除了获取public修饰的内容还可以获取private修改的内容
- 所以此处无需提供setter方法
(2)@Autowired是按照类型注入,那么对应BookDao接口如果有多个实现类,比如添加BookDaoImpl2
1 |
|
这个时候再次运行App,就会报错

此时,按照类型注入就无法区分到底注入哪个对象,解决方案:按照名称注入
先给两个Dao类分别起个名称
1
2
3
4
5
6
7
8
9
10
11
12
public class BookDaoImpl implements BookDao {
public void save() {
System.out.println("book dao save ..." );
}
}
public class BookDaoImpl2 implements BookDao {
public void save() {
System.out.println("book dao save ...2" );
}
}此时就可以注入成功,但是得思考个问题:
@Autowired是按照类型注入的,给BookDao的两个实现起了名称,它还是有两个bean对象,为什么不报错?
@Autowired默认按照类型自动装配,如果IOC容器中同类的Bean找到多个,就按照变量名和Bean的名称匹配。因为变量名叫
bookDao而容器中也有一个booDao,所以可以成功注入。分析下面这种情况是否能完成注入呢?

不行,因为按照类型会找到多个bean对象,此时会按照
bookDao名称去找,因为IOC容器只有名称叫bookDao1和bookDao2,所以找不到,会报NoUniqueBeanDefinitionException
3 注解实现按照名称注入
当根据类型在容器中找到多个bean,注入参数的属性名又和容器中bean的名称不一致,这个时候该如何解决,就需要使用到@Qualifier来指定注入哪个名称的bean对象。
1 |
|
@Qualifier注解后的值就是需要注入的bean的名称。
==注意:@Qualifier不能独立使用,必须和@Autowired一起使用==
4 简单数据类型注入
引用类型看完,简单类型注入就比较容易懂了。简单类型注入的是基本数据类型或者字符串类型,下面在BookDaoImpl类中添加一个name属性,用其进行简单类型注入
1 |
|
数据类型换了,对应的注解也要跟着换,这次使用@Value注解,将值写入注解的参数中就行了
1 |
|
注意数据格式要匹配,如将”abc”注入给int值,这样程序就会报错。
介绍完后,会有一种感觉就是这个注解好像没什么用,跟直接赋值是一个效果,还没有直接赋值简单,所以这个注解存在的意义是什么?
5 注解读取properties配置文件
@Value一般会被用在从properties配置文件中读取内容进行使用,具体如何实现?
步骤1:resource下准备properties文件
jdbc.properties
1 | name=itheima888 |
步骤2: 使用注解加载properties配置文件
在配置类上添加@PropertySource注解
1 |
|
步骤3:使用@Value读取配置文件中的内容
1 |
|
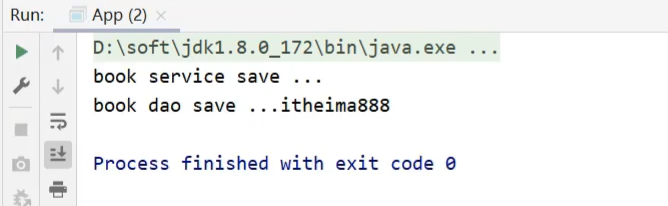
步骤4:运行程序
运行App类,查看运行结果,说明配置文件中的内容已经被加载到
注意:
如果读取的properties配置文件有多个,可以使用
@PropertySource的属性来指定多个1
@PropertySource注解属性中不支持使用通配符*,运行会报错1
@PropertySource注解属性中可以把classpath:加上,代表从当前项目的根路径找文件1
知识点1:@Autowired
| 名称 | @Autowired |
|---|---|
| 类型 | 属性注解 或 方法注解(了解) 或 方法形参注解(了解) |
| 位置 | 属性定义上方 或 标准set方法上方 或 类set方法上方 或 方法形参前面 |
| 作用 | 为引用类型属性设置值 |
| 属性 | required:true/false,定义该属性是否允许为null |
知识点2:@Qualifier
| 名称 | @Qualifier |
|---|---|
| 类型 | 属性注解 或 方法注解(了解) |
| 位置 | 属性定义上方 或 标准set方法上方 或 类set方法上方 |
| 作用 | 为引用类型属性指定注入的beanId |
| 属性 | value(默认):设置注入的beanId |
知识点3:@Value
| 名称 | @Value |
|---|---|
| 类型 | 属性注解 或 方法注解(了解) |
| 位置 | 属性定义上方 或 标准set方法上方 或 类set方法上方 |
| 作用 | 为 基本数据类型 或 字符串类型 属性设置值 |
| 属性 | value(默认):要注入的属性值 |
知识点4:@PropertySource
| 名称 | @PropertySource |
|---|---|
| 类型 | 类注解 |
| 位置 | 类定义上方 |
| 作用 | 加载properties文件中的属性值 |
| 属性 | value(默认):设置加载的properties文件对应的文件名或文件名组成的数组 |
IOC/DI注解开发管理第三方bean
前面定义bean的时候都是在自己开发的类上面写个注解就完成了,但如果是第三方的类,这些类都是在jar包中,我们没有办法在类上面添加注解,这个时候该怎么办?
遇到上述问题,我们就需要有一种更加灵活的方式来定义bean,这种方式不能在原始代码上面书写注解,一样能定义bean,这就用到了一个全新的注解==@Bean==。
这个注解该如何使用呢?
咱们把之前使用配置方式管理的数据源使用注解再来一遍,通过这个案例来学习下@Bean的使用。
1 环境准备
学习@Bean注解之前先来准备环境:
创建一个Maven项目
pom.xml添加Spring的依赖
1
2
3
4
5
6
7<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
</dependencies>添加一个配置类
SpringConfig1
2
3
public class SpringConfig {
}添加BookDao、BookDaoImpl类
1
2
3
4
5
6
7
8
9public interface BookDao {
public void save();
}
public class BookDaoImpl implements BookDao {
public void save() {
System.out.println("book dao save ..." );
}
}创建运行类App
1
2
3
4
5public class App {
public static void main(String[] args) {
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);
}
}
最终创建好的项目结构如下:

2 注解开发管理第三方bean
在上述环境中完成对Druid数据源的管理,具体的实现步骤为:
步骤1:导入对应的jar包
1 | <dependency> |
步骤2:在配置类中添加一个方法
注意该方法的返回值就是要创建的Bean对象类型
1 |
|
步骤3:在方法上添加@Bean注解
@Bean注解的作用是将方法的返回值制作为Spring管理的一个bean对象
1 |
|
注意:不能使用DataSource ds = new DruidDataSource()
因为DataSource接口中没有对应的setter方法来设置属性。
步骤4:从IOC容器中获取对象并打印
1 | public class App { |
至此使用@Bean来管理第三方bean的案例就已经完成。
如果有多个bean要被Spring管理,直接在配置类中多些几个方法,方法上添加@Bean注解即可。
注解开发实现为第三方bean注入资源
在使用@Bean创建bean对象的时候,如果方法在创建的过程中需要其他资源该怎么办?
这些资源会有两大类,分别是简单数据类型 和引用数据类型。
1 简单数据类型
1.1 需求分析
对于下面代码关于数据库的四要素不应该写死在代码中,应该是从properties配置文件中读取。如何来优化下面的代码?
1 | public class JdbcConfig { |
1.2 注入简单数据类型步骤
步骤1:类中提供四个属性
1 | public class JdbcConfig { |
步骤2:使用@Value注解引入值
1 | public class JdbcConfig { |
扩展
现在的数据库连接四要素还是写在代码中,需要做的是将这些内容提
取到jdbc.properties配置文件,大家思考下该如何实现?
1.resources目录下添加jdbc.properties
2.配置文件中提供四个键值对分别是数据库的四要素
3.使用@PropertySource加载jdbc.properties配置文件
4.修改@Value注解属性的值,将其修改为
${key},key就是键值对中的键的值
具体的实现就交由大家自行实现下。
2 引用数据类型
2.1 需求分析
假设在构建DataSource对象的时候,需要用到BookDao对象,该如何把BookDao对象注入进方法内让其使用呢?
1 | public class JdbcConfig { |
2.2 注入引用数据类型步骤
步骤1:在SpringConfig中扫描BookDao
扫描的目的是让Spring能管理到BookDao,也就是说要让IOC容器中有一个bookDao对象
1 |
|
步骤2:在JdbcConfig类的方法上添加参数
1 |
|
==引用类型注入只需要为bean定义方法设置形参即可,容器会根据类型自动装配对象。==
步骤3:运行程序
注解开发总结
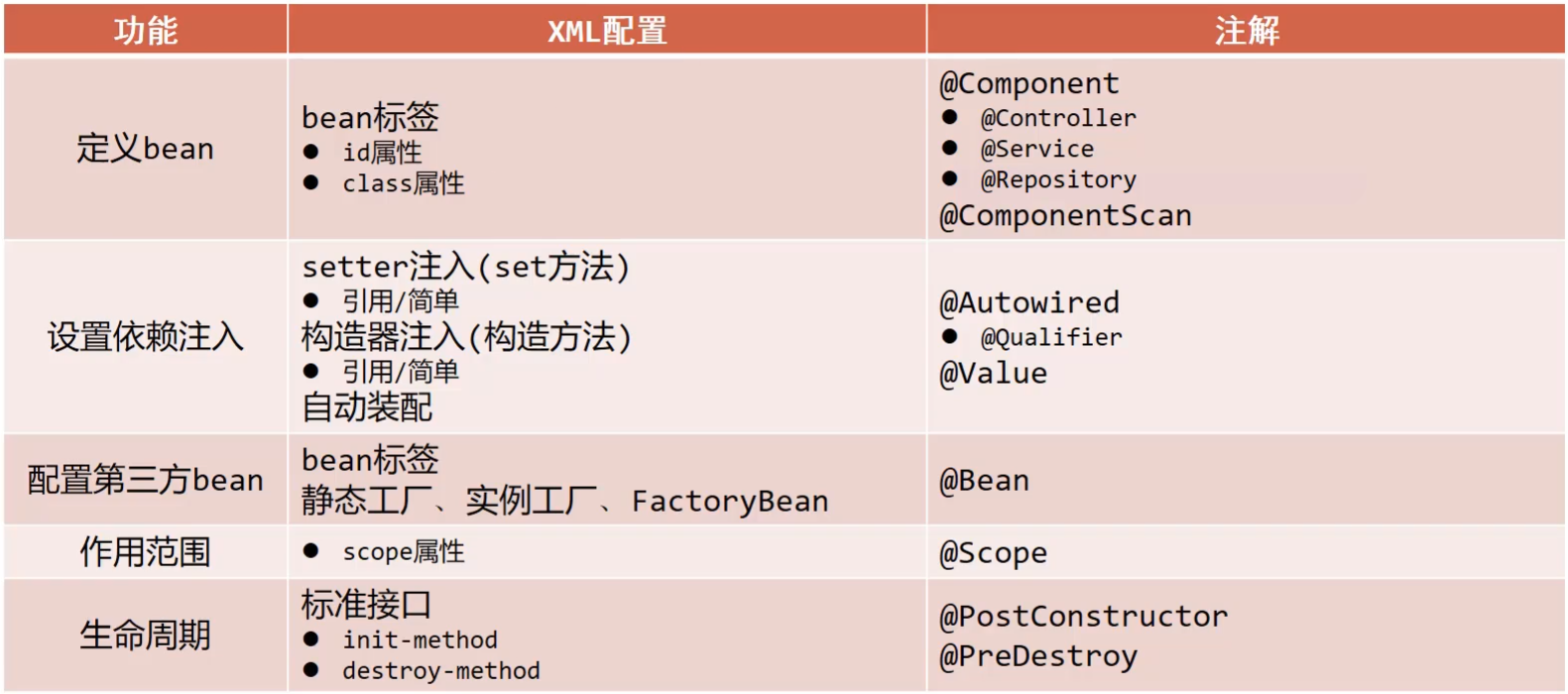
两者之间的差异,咱们放在一块去对比回顾下:
Spring整合
课程学习到这里,已经对Spring有一个简单的认识了,Spring有一个容器,叫做IoC容器,里面保存bean。在进行企业级开发的时候,其实除了将自己写的类让Spring管理之外,还有一部分重要的工作就是使用第三方的技术。前面已经讲了如何管理第三方bean了,下面结合IoC和DI,整合2个常用技术,进一步加深对Spring的使用理解。
6.1 Spring整合Mybatis思路分析
1 环境准备
在准备环境的过程中,我们也来回顾下Mybatis开发的相关内容:
步骤1:准备数据库表
Mybatis是来操作数据库表,所以先创建一个数据库及表
1 | create database spring_db character set utf8; |
步骤2:创建项目导入jar包
项目的pom.xml添加相关依赖
1 | <dependencies> |
步骤3:根据表创建模型类
1 | public class Account implements Serializable { |
步骤4:创建Dao接口
1 | public interface AccountDao { |
步骤5:创建Service接口和实现类
1 | public interface AccountService { |
步骤6:添加jdbc.properties文件
resources目录下添加,用于配置数据库连接四要素
1 | =com.mysql.jdbc.Driver |
useSSL:关闭MySQL的SSL连接
步骤7:添加Mybatis核心配置文件
1 |
|
步骤8:编写应用程序
1 | public class App { |
步骤9:运行程序
2 整合思路分析
Mybatis的基础环境我们已经准备好了,接下来就得分析下在上述的内容中,哪些对象可以交给Spring来管理?
Mybatis程序核心对象分析

从图中可以获取到,真正需要交给Spring管理的是==SqlSessionFactory==
整合Mybatis,就是将Mybatis用到的内容交给Spring管理,分析下配置文件

说明:
- 第一行读取外部properties配置文件,Spring有提供具体的解决方案
@PropertySource,需要交给Spring - 第二行起别名包扫描,为SqlSessionFactory服务的,需要交给Spring
- 第三行主要用于做连接池,Spring之前我们已经整合了Druid连接池,这块也需要交给Spring
- 前面三行一起都是为了创建SqlSession对象用的,那么用Spring管理SqlSession对象吗?回忆下SqlSession是由SqlSessionFactory创建出来的,所以只需要将SqlSessionFactory交给Spring管理即可。
- 第四行是Mapper接口和映射文件[如果使用注解就没有该映射文件],这个是在获取到SqlSession以后执行具体操作的时候用,所以它和SqlSessionFactory创建的时机都不在同一个时间,可能需要单独管理。
- 第一行读取外部properties配置文件,Spring有提供具体的解决方案
Spring整合Mybatis
前面我们已经分析了Spring与Mybatis的整合,大体需要做两件事,
第一件事是:Spring要管理MyBatis中的SqlSessionFactory
第二件事是:Spring要管理Mapper接口的扫描
具体该如何实现,具体的步骤为:
步骤1:项目中导入整合需要的jar包
1 | <dependency> |
步骤2:创建Spring的主配置类
1 | //配置类注解 |
步骤3:创建数据源的配置类
在配置类中完成数据源的创建
1 | public class JdbcConfig { |
步骤4:主配置类中读properties并引入数据源配置类
1 |
|
步骤5:创建Mybatis配置类并配置SqlSessionFactory
1 | public class MybatisConfig { |
说明:
使用SqlSessionFactoryBean封装SqlSessionFactory需要的环境信息
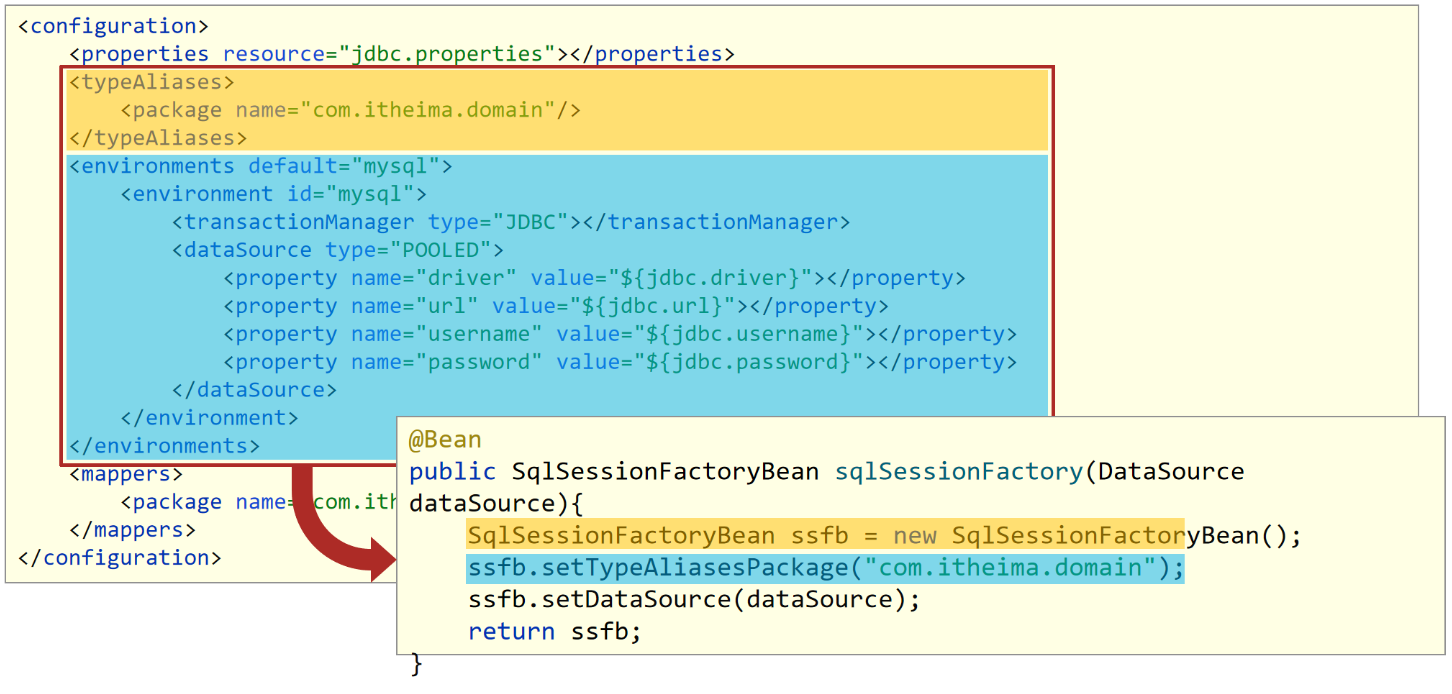
- SqlSessionFactoryBean是前面我们讲解FactoryBean的一个子类,在该类中将SqlSessionFactory的创建进行了封装,简化对象的创建,我们只需要将其需要的内容设置即可。
- 方法中有一个参数为dataSource,当前Spring容器中已经创建了Druid数据源,类型刚好是DataSource类型,此时在初始化SqlSessionFactoryBean这个对象的时候,发现需要使用DataSource对象,而容器中刚好有这么一个对象,就自动加载了DruidDataSource对象。
使用MapperScannerConfigurer加载Dao接口,创建代理对象保存到IOC容器中
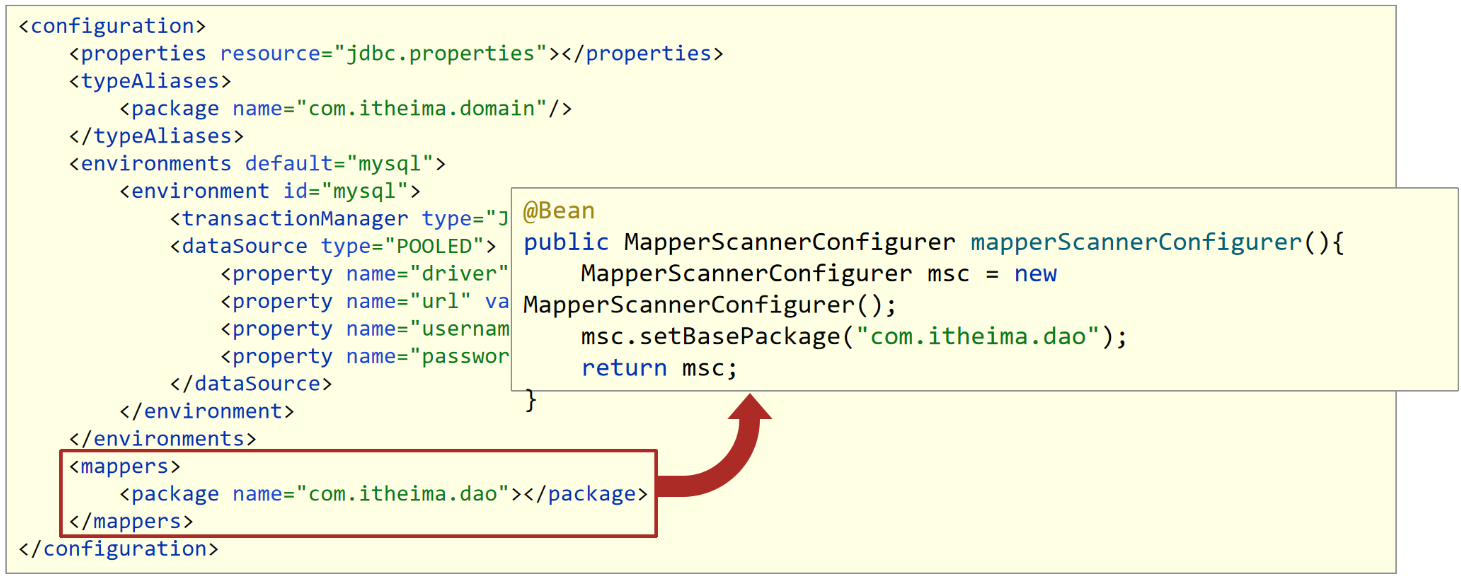
- 这个MapperScannerConfigurer对象也是MyBatis提供的专用于整合的jar包中的类,用来处理原始配置文件中的mappers相关配置,加载数据层的Mapper接口类
- MapperScannerConfigurer有一个核心属性basePackage,就是用来设置所扫描的包路径
步骤6:主配置类中引入Mybatis配置类
1 |
|
步骤7:编写运行类
在运行类中,从IOC容器中获取Service对象,调用方法获取结果
1 | public class App2 { |
步骤8:运行程序

支持Spring与Mybatis的整合就已经完成了,其中主要用到的两个类分别是:
- ==SqlSessionFactoryBean==
- ==MapperScannerConfigurer==
Spring整合Junit
整合Junit与整合Druid和MyBatis差异比较大,为什么呢?Junit是一个搞单元测试用的工具,它不是我们程序的主体,也不会参加最终程序的运行,从作用上来说就和之前的东西不一样,它不是做功能的,看做是一个辅助工具就可以了。
1 环境准备
这块环境,大家可以直接使用Spring与Mybatis整合的环境即可。当然也可以重新创建一个,因为内容是一模一样,所以我们直接来看下项目结构即可:
2 整合Junit步骤
在上述环境的基础上,我们来对Junit进行整合。
步骤1:引入依赖
pom.xml
1 | <dependency> |
步骤2:编写测试类
在test\java下创建一个AccountServiceTest,这个名字任意
1 | //设置类运行器 |
注意:
- 单元测试,如果测试的是注解配置类,则使用
@ContextConfiguration(classes = 配置类.class) - 单元测试,如果测试的是配置文件,则使用
@ContextConfiguration(locations={配置文件名,...}) - Junit运行后是基于Spring环境运行的,所以Spring提供了一个专用的类运行器,这个务必要设置,这个类运行器就在Spring的测试专用包中提供的,导入的坐标就是这个东西
SpringJUnit4ClassRunner - 上面两个配置都是固定格式,当需要测试哪个bean时,使用自动装配加载对应的对象,下面的工作就和以前做Junit单元测试完全一样了
知识点1:@RunWith
| 名称 | @RunWith |
|---|---|
| 类型 | 测试类注解 |
| 位置 | 测试类定义上方 |
| 作用 | 设置JUnit运行器 |
| 属性 | value(默认):运行所使用的运行期 |
知识点2:@ContextConfiguration
| 名称 | @ContextConfiguration |
|---|---|
| 类型 | 测试类注解 |
| 位置 | 测试类定义上方 |
| 作用 | 设置JUnit加载的Spring核心配置 |
| 属性 | classes:核心配置类,可以使用数组的格式设定加载多个配置类 locations:配置文件,可以使用数组的格式设定加载多个配置文件名称 |
AOP简介
前面我们在介绍Spring的时候说过,Spring有两个核心的概念,一个是IOC/DI,一个是AOP。
前面已经对IOC/DI进行了系统的学习,接下来要学习它的另一个核心内容,就是==AOP==。
对于AOP,我们前面提过一句话是:==AOP是在不改原有代码的前提下对其进行增强。==
对于下面的内容,我们主要就是围绕着这一句话进行展开学习,主要学习两方面内容AOP核心概念,AOP作用:
1 什么是AOP?
- AOP(Aspect Oriented Programming)面向切面编程,一种编程范式,指导开发者如何组织程序结构。
- OOP(Object Oriented Programming)面向对象编程
我们都知道OOP是一种编程思想,那么AOP也是一种编程思想,编程思想主要的内容就是指导程序员该如何编写程序,所以它们两个是不同的编程范式。
2 AOP作用
- 作用:在不惊动原始设计的基础上为其进行功能增强,前面咱们有技术就可以实现这样的功能即代理模式。
前面咱们有技术就可以实现这样的功能即代理模式。
3 AOP核心概念
为了能更好的理解AOP的相关概念,我们准备了一个环境,整个环境的内容我们暂时可以不用关注,最主要的类为:BookDaoImpl
1 |
|
代码的内容相信大家都能够读懂,对于save方法中有计算万次执行消耗的时间。
当在App类中从容器中获取bookDao对象后,分别执行其save,delete,update和select方法后会有如下的打印结果:
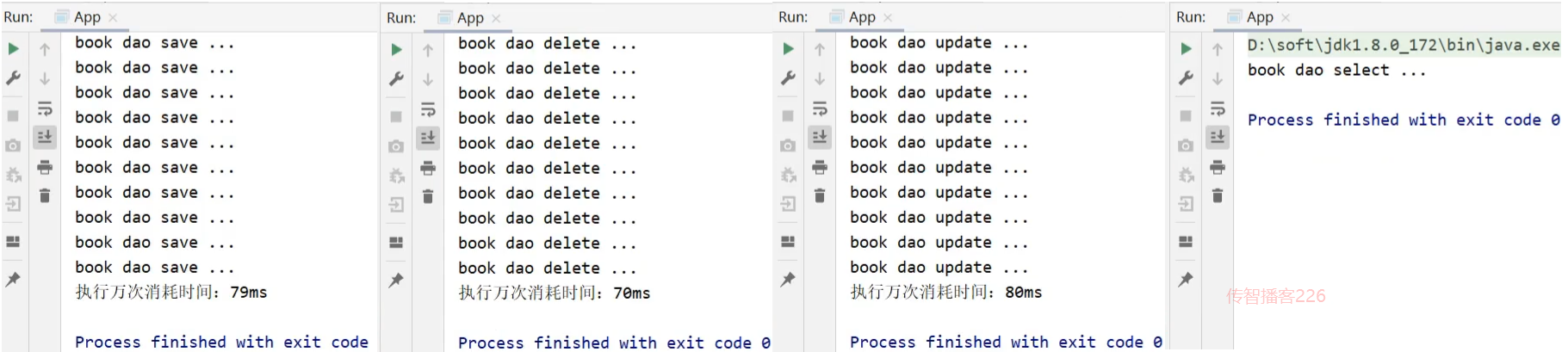
这个时候,我们就应该有些疑问?
- 对于计算万次执行消耗的时间只有save方法有,为什么delete和update方法也会有呢?
- delete和update方法有,那什么select方法为什么又没有呢?
这个案例中其实就使用了Spring的AOP,在不惊动(改动)原有设计(代码)的前提下,想给谁添加功能就给谁添加。这个也就是Spring的理念:
- 无入侵式/无侵入式
说了这么多,Spring到底是如何实现的呢?

(1)前面一直在强调,Spring的AOP是对一个类的方法在不进行任何修改的前提下实现增强。对于上面的案例中BookServiceImpl中有save,update,delete和select方法,这些方法我们给起了一个名字叫==连接点==
(2)在BookServiceImpl的四个方法中,update和delete只有打印没有计算万次执行消耗时间,但是在运行的时候已经有该功能,那也就是说update和delete方法都已经被增强,所以对于需要增强的方法我们给起了一个名字叫==切入点==
(3)执行BookServiceImpl的update和delete方法的时候都被添加了一个计算万次执行消耗时间的功能,将这个功能抽取到一个方法中,换句话说就是存放共性功能的方法,我们给起了个名字叫==通知==
(4)通知是要增强的内容,会有多个,切入点是需要被增强的方法,也会有多个,那哪个切入点需要添加哪个通知,就需要提前将它们之间的关系描述清楚,那么对于通知和切入点之间的关系描述,我们给起了个名字叫==切面==
(5)通知是一个方法,方法不能独立存在需要被写在一个类中,这个类我们也给起了个名字叫==通知类==
至此AOP中的核心概念就已经介绍完了,总结下:
- 连接点(JoinPoint):程序执行过程中的任意位置,粒度为执行方法、抛出异常、设置变量等
- 在SpringAOP中,理解为方法的执行
- 切入点(Pointcut):匹配连接点的式子
- 在SpringAOP中,一个切入点可以描述一个具体方法,也可也匹配多个方法
- 一个具体的方法:如com.itheima.dao包下的BookDao接口中的无形参无返回值的save方法
- 匹配多个方法:所有的save方法,所有的get开头的方法,所有以Dao结尾的接口中的任意方法,所有带有一个参数的方法
- 连接点范围要比切入点范围大,是切入点的方法也一定是连接点,但是是连接点的方法就不一定要被增强,所以可能不是切入点。
- 在SpringAOP中,一个切入点可以描述一个具体方法,也可也匹配多个方法
- 通知(Advice):在切入点处执行的操作,也就是共性功能
- 在SpringAOP中,功能最终以方法的形式呈现
- 通知类:定义通知的类
- 切面(Aspect):描述通知与切入点的对应关系。
小结
这一节中主要讲解了AOP的概念与作用,以及AOP中的核心概念,学完以后大家需要能说出:
- 什么是AOP?
- AOP的作用是什么?
- AOP中核心概念分别指的是什么?
- 连接点
- 切入点
- 通知
- 通知类
- 切面
知识点1:@EnableAspectJAutoProxy
| 名称 | @EnableAspectJAutoProxy |
|---|---|
| 类型 | 配置类注解 |
| 位置 | 配置类定义上方 |
| 作用 | 开启注解格式AOP功能 |
知识点2:@Aspect
| 名称 | @Aspect |
|---|---|
| 类型 | 类注解 |
| 位置 | 切面类定义上方 |
| 作用 | 设置当前类为AOP切面类 |
知识点3:@Pointcut
| 名称 | @Pointcut |
|---|---|
| 类型 | 方法注解 |
| 位置 | 切入点方法定义上方 |
| 作用 | 设置切入点方法 |
| 属性 | value(默认):切入点表达式 |
知识点4:@Before
| 名称 | @Before |
|---|---|
| 类型 | 方法注解 |
| 位置 | 通知方法定义上方 |
| 作用 | 设置当前通知方法与切入点之间的绑定关系,当前通知方法在原始切入点方法前运行 |
AOP工作流程
AOP的入门案例已经完成,对于刚才案例的执行过程,我们就得来分析分析,这一节我们主要讲解两个知识点:AOP工作流程和AOP核心概念。其中核心概念是对前面核心概念的补充。
1 AOP工作流程
由于AOP是基于Spring容器管理的bean做的增强,所以整个工作过程需要从Spring加载bean说起:
流程1:Spring容器启动
- 容器启动就需要去加载bean,哪些类需要被加载呢?
- 需要被增强的类,如:BookServiceImpl
- 通知类,如:MyAdvice
- 注意此时bean对象还没有创建成功
流程2:读取所有切面配置中的切入点
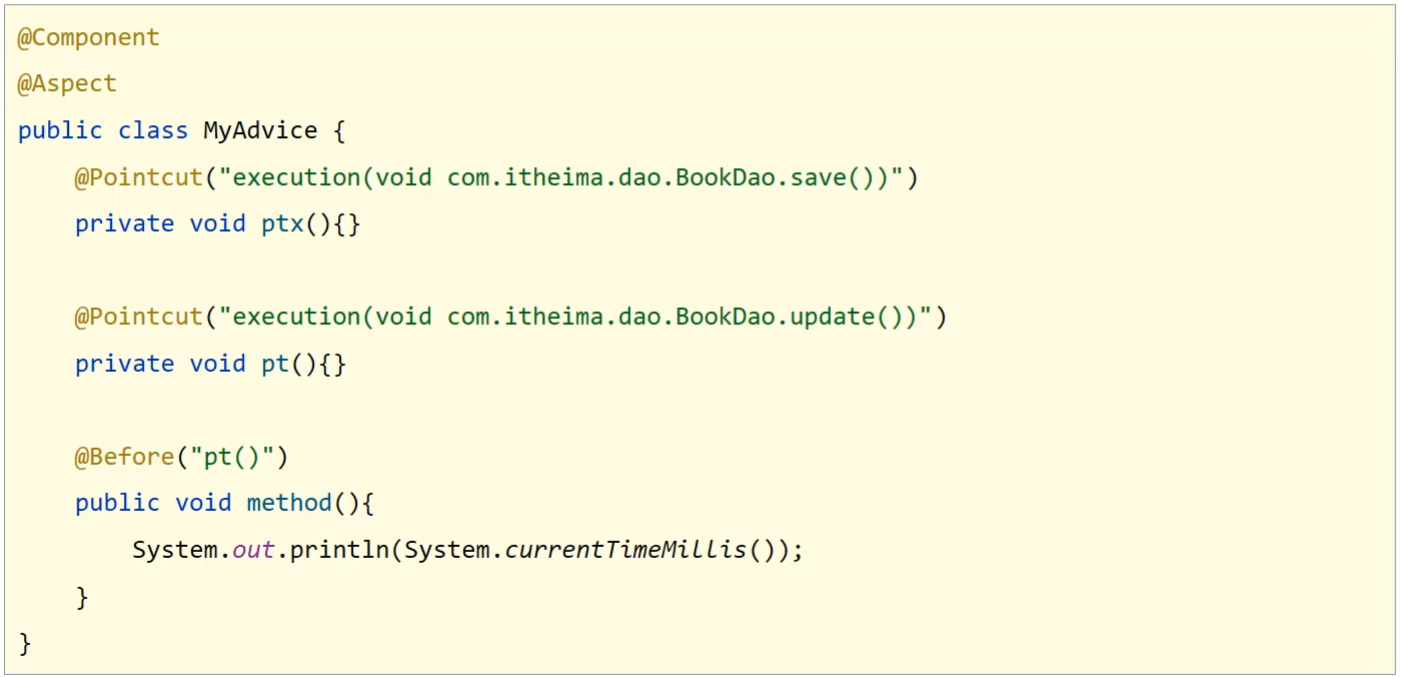
- 上面这个例子中有两个切入点的配置,但是第一个
ptx()并没有被使用,所以不会被读取。
流程3:初始化bean,
判定bean对应的类中的方法是否匹配到任意切入点
注意第1步在容器启动的时候,bean对象还没有被创建成功。
要被实例化bean对象的类中的方法和切入点进行匹配

- 匹配失败,创建原始对象,如
UserDao- 匹配失败说明不需要增强,直接调用原始对象的方法即可。
- 匹配成功,创建原始对象(==目标对象==)的==代理==对象,如:
BookDao- 匹配成功说明需要对其进行增强
- 对哪个类做增强,这个类对应的对象就叫做目标对象
- 因为要对目标对象进行功能增强,而采用的技术是动态代理,所以会为其创建一个代理对象
- 最终运行的是代理对象的方法,在该方法中会对原始方法进行功能增强
- 匹配失败,创建原始对象,如
流程4:获取bean执行方法
- 获取的bean是原始对象时,调用方法并执行,完成操作
- 获取的bean是代理对象时,根据代理对象的运行模式运行原始方法与增强的内容,完成操作
验证容器中是否为代理对象
为了验证IOC容器中创建的对象和我们刚才所说的结论是否一致,首先先把结论理出来:
- 如果目标对象中的方法会被增强,那么容器中将存入的是目标对象的代理对象
- 如果目标对象中的方法不被增强,那么容器中将存入的是目标对象本身。
2 AOP核心概念
在上面介绍AOP的工作流程中,我们提到了两个核心概念,分别是:
- 目标对象(Target):原始功能去掉共性功能对应的类产生的对象,这种对象是无法直接完成最终工作的
- 代理(Proxy):目标对象无法直接完成工作,需要对其进行功能回填,通过原始对象的代理对象实现
上面这两个概念比较抽象,简单来说,
目标对象就是要增强的类[如:BookServiceImpl类]对应的对象,也叫原始对象,不能说它不能运行,只能说它在运行的过程中对于要增强的内容是缺失的。
SpringAOP是在不改变原有设计(代码)的前提下对其进行增强的,它的底层采用的是代理模式实现的,所以要对原始对象进行增强,就需要对原始对象创建代理对象,在代理对象中的方法把通知[如:MyAdvice中的method方法]内容加进去,就实现了增强,这就是我们所说的代理(Proxy)。
AOP配置管理
1 AOP切入点表达式
前面的案例中,有涉及到如下内容:
对于AOP中切入点表达式,我们总共会学习三个内容,分别是语法格式、通配符和书写技巧。
1 语法格式
首先我们先要明确两个概念:
- 切入点:要进行增强的方法
- 切入点表达式:要进行增强的方法的描述方式
对于切入点的描述,我们其实是有两中方式的,先来看下前面的例子

描述方式一:执行com.itheima.dao包下的BookDao接口中的无参数update方法
1 | execution(void com.itheima.dao.BookDao.update()) |
描述方式二:执行com.itheima.dao.impl包下的BookDaoImpl类中的无参数update方法
1 | execution(void com.itheima.dao.impl.BookDaoImpl.update()) |
因为调用接口方法的时候最终运行的还是其实现类的方法,所以上面两种描述方式都是可以的。
对于切入点表达式的语法为:
- 切入点表达式标准格式:动作关键字(访问修饰符 返回值 包名.类/接口名.方法名(参数) 异常名)
对于这个格式,我们不需要硬记,通过一个例子,理解它:
1 | execution(public User com.itheima.service.UserService.findById(int)) |
- execution:动作关键字,描述切入点的行为动作,例如execution表示执行到指定切入点
- public:访问修饰符,还可以是public,private等,可以省略
- User:返回值,写返回值类型
- com.itheima.service:包名,多级包使用点连接
- UserService:类/接口名称
- findById:方法名
- int:参数,直接写参数的类型,多个类型用逗号隔开
- 异常名:方法定义中抛出指定异常,可以省略
切入点表达式就是要找到需要增强的方法,所以它就是对一个具体方法的描述,但是方法的定义会有很多,所以如果每一个方法对应一个切入点表达式,想想这块就会觉得将来编写起来会比较麻烦,有没有更简单的方式呢?
就需要用到下面所学习的通配符。
2 通配符
我们使用通配符描述切入点,主要的目的就是简化之前的配置,具体都有哪些通配符可以使用?
*:单个独立的任意符号,可以独立出现,也可以作为前缀或者后缀的匹配符出现1
execution(public * com.itheima.*.UserService.find*(*))
匹配com.itheima包下的任意包中的UserService类或接口中所有find开头的带有一个参数的方法
..:多个连续的任意符号,可以独立出现,常用于简化包名与参数的书写1
execution(public User com..UserService.findById(..))
匹配com包下的任意包中的UserService类或接口中所有名称为findById的方法
+:专用于匹配子类类型1
execution(* *..*Service+.*(..))
这个使用率较低,描述子类的,咱们做JavaEE开发,继承机会就一次,使用都很慎重,所以很少用它。*Service+,表示所有以Service结尾的接口的子类。
接下来,我们把案例中使用到的切入点表达式来分析下:

1 | execution(void com.itheima.dao.BookDao.update()) |
后面两种更符合我们平常切入点表达式的编写规则
3 书写技巧
对于切入点表达式的编写其实是很灵活的,那么在编写的时候,有没有什么好的技巧让我们用用:
- 所有代码按照标准规范开发,否则以下技巧全部失效
- 描述切入点通**==常描述接口==**,而不描述实现类,如果描述到实现类,就出现紧耦合了
- 访问控制修饰符针对接口开发均采用public描述(**==可省略访问控制修饰符描述==**)
- 返回值类型对于增删改类使用精准类型加速匹配,对于查询类使用*通配快速描述
- **==包名==书写==尽量不使用..匹配==**,效率过低,常用*做单个包描述匹配,或精准匹配
- **==接口名/类名==书写名称与模块相关的==采用*匹配==**,例如UserService书写成*Service,绑定业务层接口名
- **==方法名==书写以==动词==进行==精准匹配==*,名词采用匹配,例如getById书写成getBy*,selectAll书写成selectAll
- 参数规则较为复杂,根据业务方法灵活调整
- 通常**==不使用异常==作为==匹配==**规则
2 AOP通知类型
前面的案例中,有涉及到如下内容:

它所代表的含义是将通知添加到切入点方法执行的==前面==。
除了这个注解外,还有没有其他的注解,换个问题就是除了可以在前面加,能不能在其他的地方加?
1 类型介绍
我们先来回顾下AOP通知:
- AOP通知描述了抽取的共性功能,根据共性功能抽取的位置不同,最终运行代码时要将其加入到合理的位置
通知具体要添加到切入点的哪里?
共提供了5种通知类型:
- 前置通知
- 后置通知
- ==环绕通知(重点)==
- 返回后通知(了解)
- 抛出异常后通知(了解)
为了更好的理解这几种通知类型,我们来看一张图

(1)前置通知,追加功能到方法执行前,类似于在代码1或者代码2添加内容
(2)后置通知,追加功能到方法执行后,不管方法执行的过程中有没有抛出异常都会执行,类似于在代码5添加内容
(3)返回后通知,追加功能到方法执行后,只有方法正常执行结束后才进行,类似于在代码3添加内容,如果方法执行抛出异常,返回后通知将不会被添加
(4)抛出异常后通知,追加功能到方法抛出异常后,只有方法执行出异常才进行,类似于在代码4添加内容,只有方法抛出异常后才会被添加
(5)环绕通知,环绕通知功能比较强大,它可以追加功能到方法执行的前后,这也是比较常用的方式,它可以实现其他四种通知类型的功能,具体是如何实现的,需要我们往下学习。
2 环境准备
创建一个Maven项目
pom.xml添加Spring依赖
1
2
3
4
5
6
7
8
9
10
11
12<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.9.4</version>
</dependency>
</dependencies>添加BookDao和BookDaoImpl类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public interface BookDao {
public void update();
public int select();
}
public class BookDaoImpl implements BookDao {
public void update(){
System.out.println("book dao update ...");
}
public int select() {
System.out.println("book dao select is running ...");
return 100;
}
}创建Spring的配置类
1
2
3
4
5
public class SpringConfig {
}创建通知类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public class MyAdvice {
private void pt(){}
public void before() {
System.out.println("before advice ...");
}
public void after() {
System.out.println("after advice ...");
}
public void around(){
System.out.println("around before advice ...");
System.out.println("around after advice ...");
}
public void afterReturning() {
System.out.println("afterReturning advice ...");
}
public void afterThrowing() {
System.out.println("afterThrowing advice ...");
}
}编写App运行类
1
2
3
4
5
6
7public class App {
public static void main(String[] args) {
ApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);
BookDao bookDao = ctx.getBean(BookDao.class);
bookDao.update();
}
}
最终创建好的项目结构如下:

3 通知类型的使用
前置通知
修改MyAdvice,在before方法上添加@Before注解
1 |
|
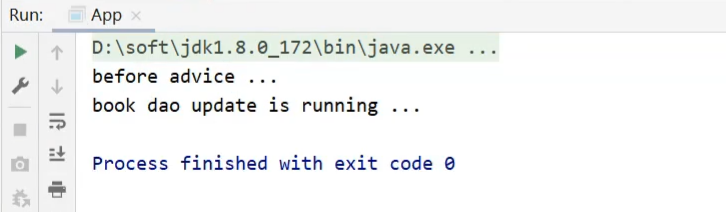
后置通知
1 |
|
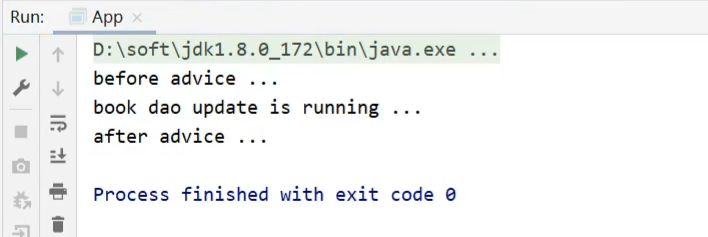
环绕通知
基本使用
1 |
|
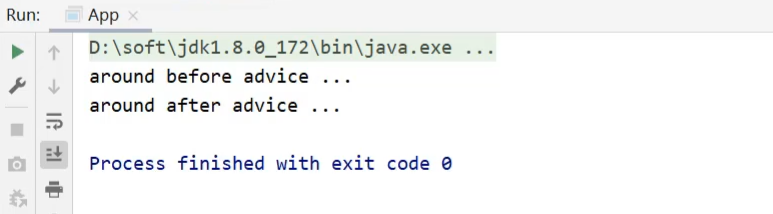
运行结果中,通知的内容打印出来,但是原始方法的内容却没有被执行。
因为环绕通知需要在原始方法的前后进行增强,所以环绕通知就必须要能对原始操作进行调用,具体如何实现?
1 |
|
**说明:**proceed()为什么要抛出异常?
原因很简单,看下源码就知道了

再次运行,程序可以看到原始方法已经被执行了
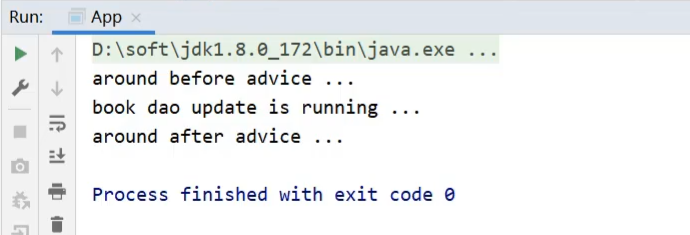
注意事项
(1)原始方法有返回值的处理
- 修改MyAdvice,对BookDao中的select方法添加环绕通知,
1 |
|
- 修改App类,调用select方法
1 | public class App { |
运行后会报错,错误内容为:
Exception in thread “main” org.springframework.aop.AopInvocationException: ==Null return value from advice does not match primitive return type for: public abstract int com.itheima.dao.BookDao.select()==
at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:226)
at com.sun.proxy.$Proxy19.select(Unknown Source)
at com.itheima.App.main(App.java:12)
错误大概的意思是:空的返回不匹配原始方法的int返回
- void就是返回Null
- 原始方法就是BookDao下的select方法
所以如果我们使用环绕通知的话,要根据原始方法的返回值来设置环绕通知的返回值,具体解决方案为:
1 |
|
说明:
为什么返回的是Object而不是int的主要原因是Object类型更通用。
在环绕通知中是可以对原始方法返回值就行修改的。
返回后通知
1 |
|
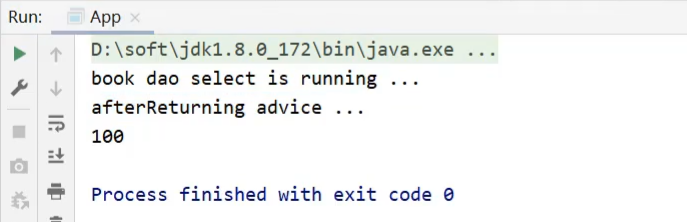
注意:返回后通知是需要在原始方法select正常执行后才会被执行,如果select()方法执行的过程中出现了异常,那么返回后通知是不会被执行。后置通知是不管原始方法有没有抛出异常都会被执行。这个案例大家下去可以自己练习验证下。
异常后通知
1 |
|
注意:异常后通知是需要原始方法抛出异常,可以在select()方法中添加一行代码int i = 1/0即可。如果没有抛异常,异常后通知将不会被执行。
学习完这5种通知类型,我们来思考下环绕通知是如何实现其他通知类型的功能的?
因为环绕通知是可以控制原始方法执行的,所以我们把增强的代码写在调用原始方法的不同位置就可以实现不同的通知类型的功能,如:

通知类型总结
知识点1:@After
| 名称 | @After |
|---|---|
| 类型 | 方法注解 |
| 位置 | 通知方法定义上方 |
| 作用 | 设置当前通知方法与切入点之间的绑定关系,当前通知方法在原始切入点方法后运行 |
知识点2:@AfterReturning
| 名称 | @AfterReturning |
|---|---|
| 类型 | 方法注解 |
| 位置 | 通知方法定义上方 |
| 作用 | 设置当前通知方法与切入点之间绑定关系,当前通知方法在原始切入点方法正常执行完毕后执行 |
知识点3:@AfterThrowing
| 名称 | @AfterThrowing |
|---|---|
| 类型 | 方法注解 |
| 位置 | 通知方法定义上方 |
| 作用 | 设置当前通知方法与切入点之间绑定关系,当前通知方法在原始切入点方法运行抛出异常后执行 |
知识点4:@Around
| 名称 | @Around |
|---|---|
| 类型 | 方法注解 |
| 位置 | 通知方法定义上方 |
| 作用 | 设置当前通知方法与切入点之间的绑定关系,当前通知方法在原始切入点方法前后运行 |
==环绕通知注意事项==
- 环绕通知必须依赖形参ProceedingJoinPoint才能实现对原始方法的调用,进而实现原始方法调用前后同时添加通知
- 通知中如果未使用ProceedingJoinPoint对原始方法进行调用将跳过原始方法的执行
- 对原始方法的调用可以不接收返回值,通知方法设置成void即可,如果接收返回值,最好设定为Object类型
- 原始方法的返回值如果是void类型,通知方法的返回值类型可以设置成void,也可以设置成Object
- 由于无法预知原始方法运行后是否会抛出异常,因此环绕通知方法必须要处理Throwable异常
介绍完这么多种通知类型,具体该选哪一种呢?
我们可以通过一些案例加深下对通知类型的学习。
程序优化
程序所面临的问题是,多个方法一起执行测试的时候,控制台都打印的是:
业务层接口万次执行时间:xxxms
我们没有办法区分到底是哪个接口的哪个方法执行的具体时间,具体如何优化?
对方法的形参ProceedingJoinPoint pjp使用getSignature()获取类名啥的
1 |
|
运行单元测试类

==补充说明==
当前测试的接口执行效率仅仅是一个理论值,并不是一次完整的执行过程。
这块只是通过该案例把AOP的使用进行了学习,具体的实际值是有很多因素共同决定的。
AOP总结
AOP的知识就已经讲解完了,接下来对于AOP的知识进行一个总结:
1 AOP的核心概念
- 概念:AOP(Aspect Oriented Programming)面向切面编程,一种编程范式
- 作用:在不惊动原始设计的基础上为方法进行功能==增强==
- 核心概念
- 代理(Proxy):SpringAOP的核心本质是采用代理模式实现的
- 连接点(JoinPoint):在SpringAOP中,理解为任意方法的执行
- 切入点(Pointcut):匹配连接点的式子,也是具有共性功能的方法描述
- 通知(Advice):若干个方法的共性功能,在切入点处执行,最终体现为一个方法
- 切面(Aspect):描述通知与切入点的对应关系
- 目标对象(Target):被代理的原始对象成为目标对象
2 切入点表达式
切入点表达式标准格式:动作关键字(访问修饰符 返回值 包名.类/接口名.方法名(参数)异常名)
1
execution(* com.itheima.service.*Service.*(..))
切入点表达式描述通配符:
- 作用:用于快速描述,范围描述
*:匹配任意符号(常用)..:匹配多个连续的任意符号(常用)+:匹配子类类型
切入点表达式书写技巧
1.按==标准规范==开发
2.查询操作的返回值建议使用*匹配
3.减少使用..的形式描述包
4.==对接口进行描述==,使用*表示模块名,例如UserService的匹配描述为*Service
5.方法名书写保留动词,例如get,使用*表示名词,例如getById匹配描述为getBy*
6.参数根据实际情况灵活调整
3 五种通知类型
- 前置通知
- 后置通知
- 环绕通知(重点)
- 环绕通知依赖形参ProceedingJoinPoint才能实现对原始方法的调用
- 环绕通知可以隔离原始方法的调用执行
- 环绕通知返回值设置为Object类型
- 环绕通知中可以对原始方法调用过程中出现的异常进行处理
- 返回后通知
- 抛出异常后通知
4 通知中获取参数
- 获取切入点方法的参数,所有的通知类型都可以获取参数
- JoinPoint:适用于前置、后置、返回后、抛出异常后通知
- ProceedingJoinPoint:适用于环绕通知
- 获取切入点方法返回值,前置和抛出异常后通知是没有返回值,后置通知可有可无,所以不做研究
- 返回后通知
- 环绕通知
- 获取切入点方法运行异常信息,前置和返回后通知是不会有,后置通知可有可无,所以不做研究
- 抛出异常后通知
- 环绕通知
AOP事务管理
Spring事务简介
1 相关概念介绍
- 事务作用:在数据层保障一系列的数据库操作同成功同失败
- Spring事务作用:在数据层或**==业务层==**保障一系列的数据库操作同成功同失败
数据层有事务我们可以理解,为什么业务层也需要处理事务呢?
举个简单的例子,
- 转账业务会有两次数据层的调用,一次是加钱一次是减钱
- 把事务放在数据层,加钱和减钱就有两个事务
- 没办法保证加钱和减钱同时成功或者同时失败
- 这个时候就需要将事务放在业务层进行处理。
Spring为了管理事务,提供了一个平台事务管理器PlatformTransactionManager

commit是用来提交事务,rollback是用来回滚事务。
PlatformTransactionManager只是一个接口,Spring还为其提供了一个具体的实现:

从名称上可以看出,我们只需要给它一个DataSource对象,它就可以帮你去在业务层管理事务。其内部采用的是JDBC的事务。所以说如果你持久层采用的是JDBC相关的技术,就可以采用这个事务管理器来管理你的事务。而Mybatis内部采用的就是JDBC的事务,所以后期我们Spring整合Mybatis就采用的这个DataSourceTransactionManager事务管理器。
4 事务管理
上述环境,运行单元测试类,会执行转账操作,Tom的账户会减少100,Jerry的账户会加100。
这是正常情况下的运行结果,但是如果在转账的过程中出现了异常,如:
1 |
|
这个时候就模拟了转账过程中出现异常的情况,正确的操作应该是转账出问题了,Tom应该还是900,Jerry应该还是1100,但是真正运行后会发现,并没有像我们想象的那样,Tom账户为800而Jerry还是1100,100块钱凭空消息了,银行乐疯了。如果把转账换个顺序,银行就该哭了。
不管哪种情况,都是不允许出现的,对刚才的结果我们做一个分析:
①:程序正常执行时,账户金额A减B加,没有问题
②:程序出现异常后,转账失败,但是异常之前操作成功,异常之后操作失败,整体业务失败
当程序出问题后,我们需要让事务进行回滚,而且这个事务应该是加在业务层上,而Spring的事务管理就是用来解决这类问题的。
Spring事务管理具体的实现步骤为:
步骤1:在需要被事务管理的方法上添加注解
1 | public interface AccountService { |
==注意:==
@Transactional可以写在接口类上、接口方法上、实现类上和实现类方法上
- 写在接口类上,该接口的所有实现类的所有方法都会有事务
- 写在接口方法上,该接口的所有实现类的该方法都会有事务
- 写在实现类上,该类中的所有方法都会有事务
- 写在实现类方法上,该方法上有事务
- ==建议写在实现类或实现类的方法上==
步骤2:在JdbcConfig类中配置事务管理器
1 | public class JdbcConfig { |
注意:事务管理器要根据使用技术进行选择,Mybatis框架使用的是JDBC事务,可以直接使用DataSourceTransactionManager
步骤3:开启事务注解
在SpringConfig的配置类中开启
1 |
步骤4:运行测试类
会发现在转换的业务出现错误后,事务就可以控制回顾,保证数据的正确性。
知识点1:@EnableTransactionManagement
| 名称 | @EnableTransactionManagement |
|---|---|
| 类型 | 配置类注解 |
| 位置 | 配置类定义上方 |
| 作用 | 设置当前Spring环境中开启注解式事务支持 |
知识点2:@Transactional
| 名称 | @Transactional |
|---|---|
| 类型 | 接口注解 类注解 方法注解 |
| 位置 | 业务层接口上方 业务层实现类上方 业务方法上方 |
| 作用 | 为当前业务层方法添加事务(如果设置在类或接口上方则类或接口中所有方法均添加事务) |
Spring事务角色
这节中我们重点要理解两个概念,分别是事务管理员和事务协调员。
- 未开启Spring事务之前:
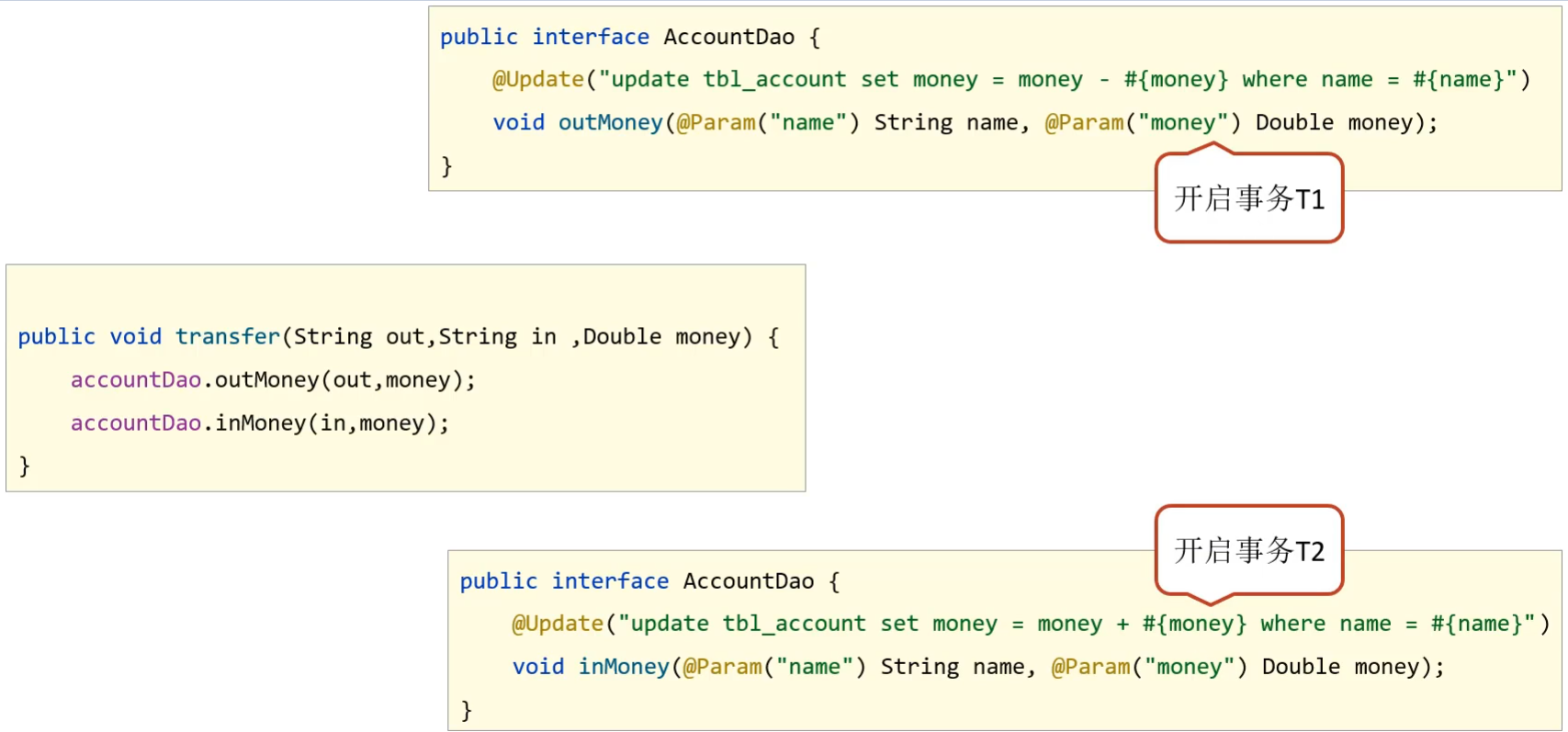
- AccountDao的outMoney因为是修改操作,会开启一个事务T1
- AccountDao的inMoney因为是修改操作,会开启一个事务T2
- AccountService的transfer没有事务,
- 运行过程中如果没有抛出异常,则T1和T2都正常提交,数据正确
- 如果在两个方法中间抛出异常,T1因为执行成功提交事务,T2因为抛异常不会被执行
- 就会导致数据出现错误
- 开启Spring的事务管理后
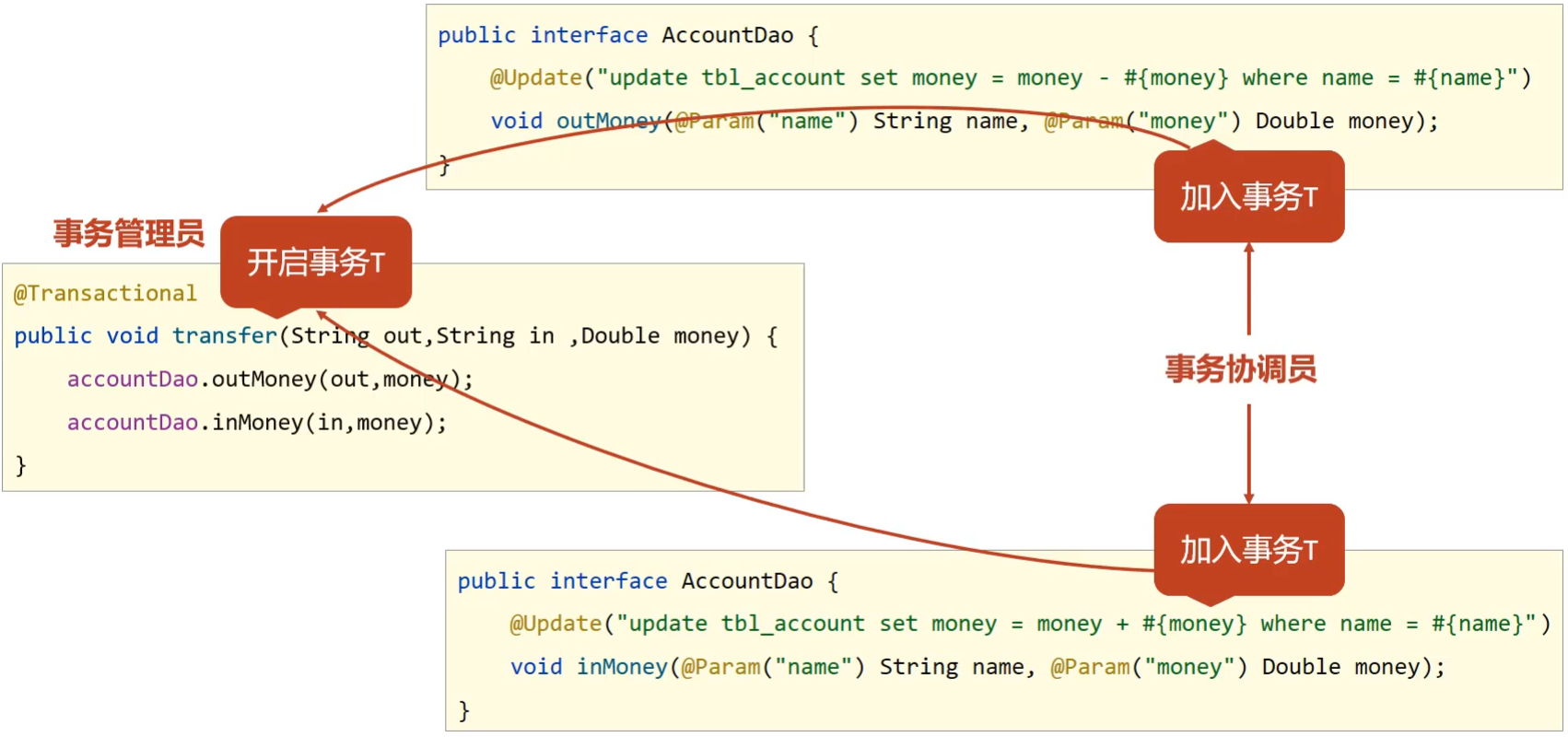
- transfer上添加了@Transactional注解,在该方法上就会有一个事务T
- AccountDao的outMoney方法的事务T1加入到transfer的事务T中
- AccountDao的inMoney方法的事务T2加入到transfer的事务T中
- 这样就保证他们在同一个事务中,当业务层中出现异常,整个事务就会回滚,保证数据的准确性。
通过上面例子的分析,我们就可以得到如下概念:
- 事务管理员:发起事务方,在Spring中通常指代业务层开启事务的方法
- 事务协调员:加入事务方,在Spring中通常指代数据层方法,也可以是业务层方法
==注意:==
目前的事务管理是基于DataSourceTransactionManager和SqlSessionFactoryBean使用的是同一个数据源。
Spring事务属性
上一节我们介绍了两个概念,事务的管理员和事务的协同员,对于这两个概念具体做什么的,我们待会通过案例来使用下。除了这两个概念,还有就是事务的其他相关配置都有哪些,就是我们接下来要学习的内容。
在这一节中,我们主要学习三部分内容事务配置、转账业务追加日志、事务传播行为。
1 事务配置
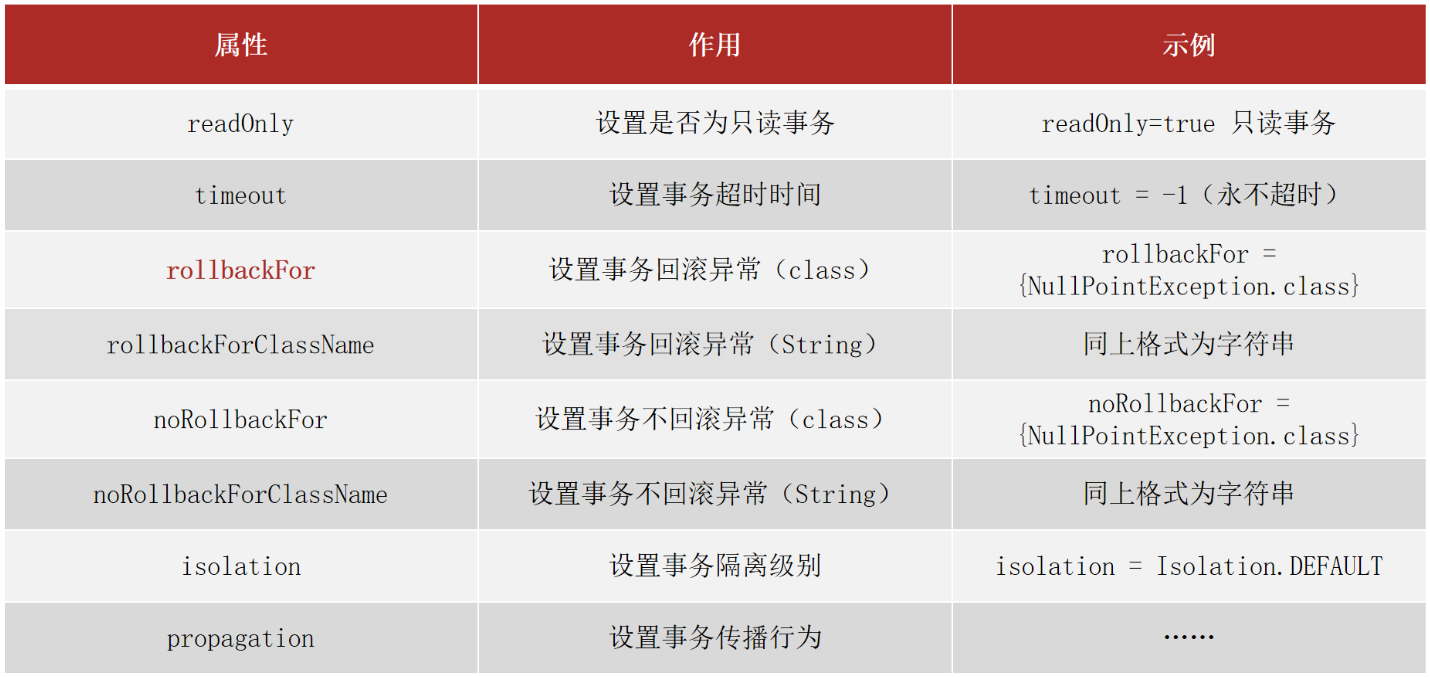
上面这些属性都可以在@Transactional注解的参数上进行设置。
readOnly:true只读事务,false读写事务,增删改要设为false,查询设为true。
timeout:设置超时时间单位秒,在多长时间之内事务没有提交成功就自动回滚,-1表示不设置超时时间。
rollbackFor:当出现指定异常进行事务回滚
noRollbackFor:当出现指定异常不进行事务回滚
思考:出现异常事务会自动回滚,这个是我们之前就已经知道的
noRollbackFor是设定对于指定的异常不回滚,这个好理解
rollbackFor是指定回滚异常,对于异常事务不应该都回滚么,为什么还要指定?
这块需要更正一个知识点,并不是所有的异常都会回滚事务,比如下面的代码就不会回滚
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public interface AccountService {
/**
* 转账操作
* @param out 传出方
* @param in 转入方
* @param money 金额
*/
//配置当前接口方法具有事务
public void transfer(String out,String in ,Double money) throws IOException;
}
public class AccountServiceImpl implements AccountService {
private AccountDao accountDao;
public void transfer(String out,String in ,Double money) throws IOException{
accountDao.outMoney(out,money);
//int i = 1/0; //这个异常事务会回滚
if(true){
throw new IOException(); //这个异常事务就不会回滚
}
accountDao.inMoney(in,money);
}
}
出现这个问题的原因是,Spring的事务只会对
Error异常和RuntimeException异常及其子类进行事务回顾,其他的异常类型是不会回滚的,对应IOException不符合上述条件所以不回滚此时就可以使用rollbackFor属性来设置出现IOException异常不回滚
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class AccountServiceImpl implements AccountService {
private AccountDao accountDao;
public void transfer(String out,String in ,Double money) throws IOException{
accountDao.outMoney(out,money);
//int i = 1/0; //这个异常事务会回滚
if(true){
throw new IOException(); //这个异常事务就不会回滚
}
accountDao.inMoney(in,money);
}
}
rollbackForClassName等同于rollbackFor,只不过属性为异常的类全名字符串
noRollbackForClassName等同于noRollbackFor,只不过属性为异常的类全名字符串
isolation设置事务的隔离级别
- DEFAULT :默认隔离级别, 会采用数据库的隔离级别
- READ_UNCOMMITTED : 读未提交
- READ_COMMITTED : 读已提交
- REPEATABLE_READ : 重复读取
- SERIALIZABLE: 串行化
2 事务传播行为
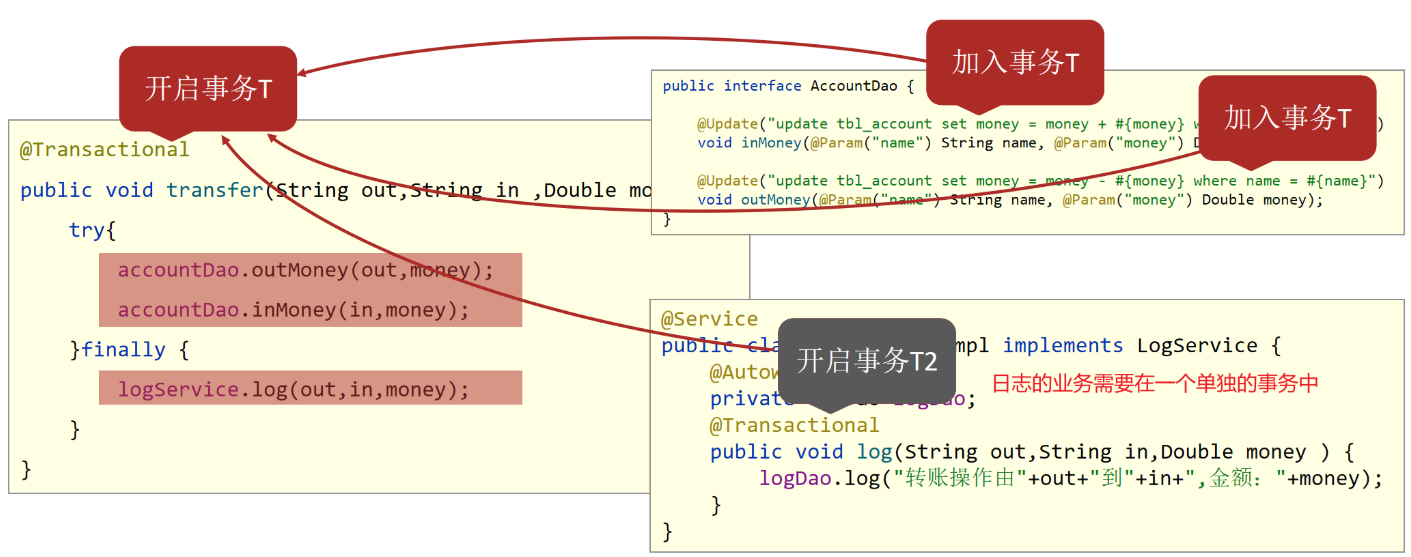
对于上述案例的分析:
- log方法、inMoney方法和outMoney方法都属于增删改,分别有事务T1,T2,T3
- transfer因为加了@Transactional注解,也开启了事务T
- 前面我们讲过Spring事务会把T1,T2,T3都加入到事务T中
- 所以当转账失败后,所有的事务都回滚,导致日志没有记录下来
- 这和我们的需求不符,这个时候我们就想能不能让log方法单独是一个事务呢?
要想解决这个问题,就需要用到事务传播行为,所谓的事务传播行为指的是:
事务传播行为:事务协调员对事务管理员所携带事务的处理态度。
具体如何解决,就需要用到之前我们没有说的propagation属性。
1.修改logService改变事务的传播行为
1 |
|
运行后,就能实现我们想要的结果,不管转账是否成功,都会记录日志。
2.事务传播行为的可选值
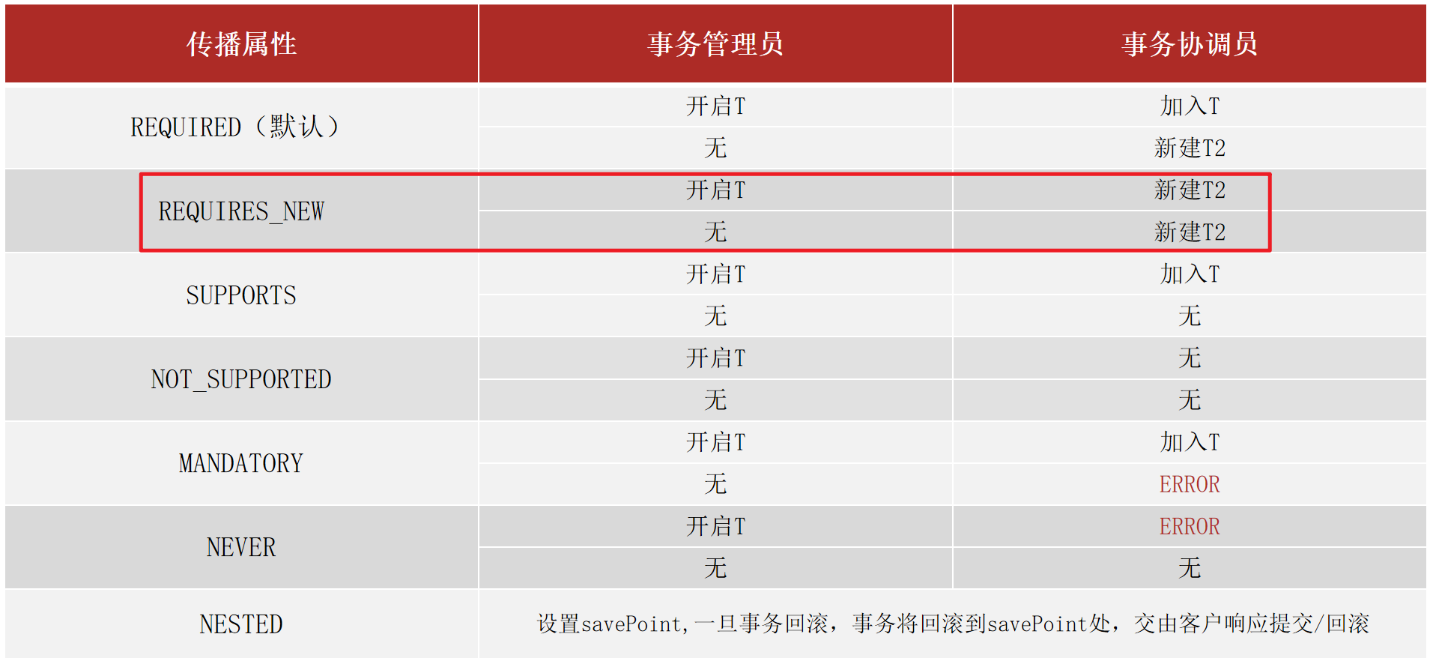
对于我们开发实际中使用的话,因为默认值需要事务是常态的。根据开发过程选择其他的就可以了,例如案例中需要新事务就需要手工配置。其实入账和出账操作上也有事务,采用的就是默认值。
SpringMVC
今日内容
- 理解SpringMVC相关概念
- 完成SpringMVC的入门案例
- 学会使用PostMan工具发送请求和数据
- 掌握SpringMVC如何接收请求、数据和响应结果
- 掌握RESTful风格及其使用
- 完成基于RESTful的案例编写
SpringMVC是隶属于Spring框架的一部分,主要是用来进行Web开发,是对Servlet进行了封装。
对于SpringMVC我们主要学习如下内容:
- SpringMVC简介
- ==请求与响应==
- ==REST风格==
- ==SSM整合(注解版)==
- 拦截器
SpringMVC是处于Web层的框架,所以其主要的作用就是用来接收前端发过来的请求和数据然后经过处理并将处理的结果响应给前端,所以如何处理请求和响应是SpringMVC中非常重要的一块内容。
REST是一种软件架构风格,可以降低开发的复杂性,提高系统的可伸缩性,后期的应用也是非常广泛。
SSM整合是把咱们所学习的SpringMVC+Spring+Mybatis整合在一起来完成业务开发,是对我们所学习这三个框架的一个综合应用。
对于SpringMVC的学习,最终要达成的目标:
- ==掌握基于SpringMVC获取请求参数和响应json数据操作==
- ==熟练应用基于REST风格的请求路径设置与参数传递==
- 能够根据实际业务建立前后端开发通信协议并进行实现
- ==基于SSM整合技术开发任意业务模块功能==
概述
学习SpringMVC我们先来回顾下现在web程序是如何做的,咱们现在web程序大都基于三层架构来实现。
三层架构
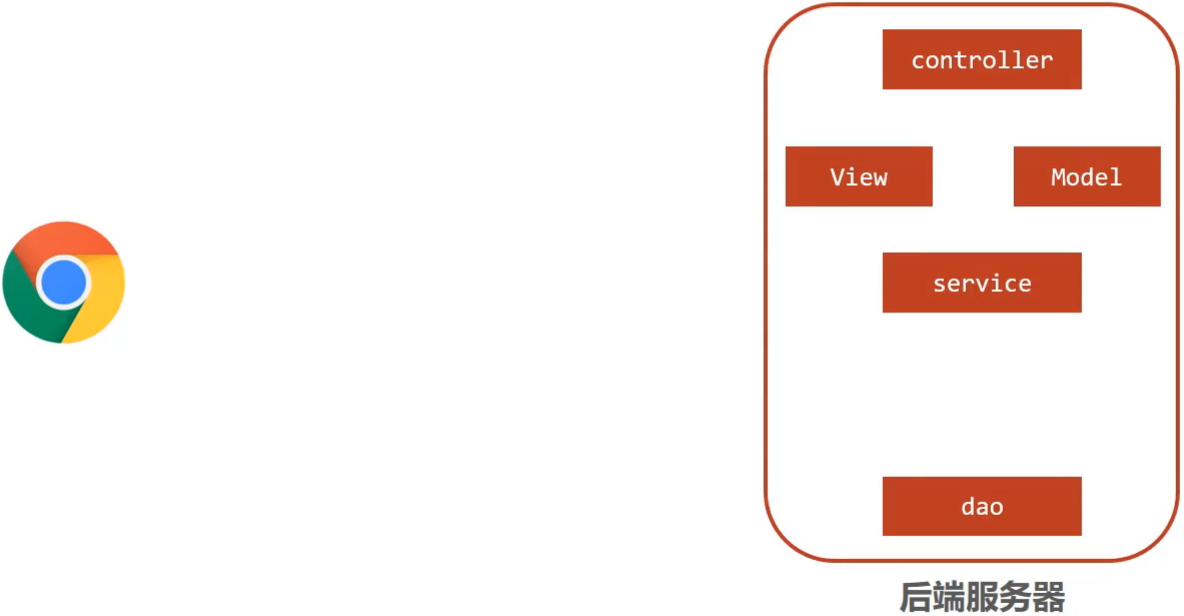
浏览器发送一个请求给后端服务器,后端服务器现在是使用Servlet来接收请求和数据
如果所有的处理都交给Servlet来处理的话,所有的东西都耦合在一起,对后期的维护和扩展极为不利
将后端服务器Servlet拆分成三层,分别是
web、service和dao- web层主要由servlet来处理,负责页面请求和数据的收集以及响应结果给前端
- service层主要负责业务逻辑的处理
- dao层主要负责数据的增删改查操作
servlet处理请求和数据的时候,存在的问题是一个servlet只能处理一个请求
针对web层进行了优化,采用了MVC设计模式,将其设计为
controller、view和Model- controller负责请求和数据的接收,接收后将其转发给service进行业务处理
- service根据需要会调用dao对数据进行增删改查
- dao把数据处理完后将结果交给service,service再交给controller
- controller根据需求组装成Model和View,Model和View组合起来生成页面转发给前端浏览器
- 这样做的好处就是controller可以处理多个请求,并对请求进行分发,执行不同的业务操作。
随着互联网的发展,上面的模式因为是同步调用,性能慢慢的跟不是需求,所以异步调用慢慢的走到了前台,是现在比较流行的一种处理方式。
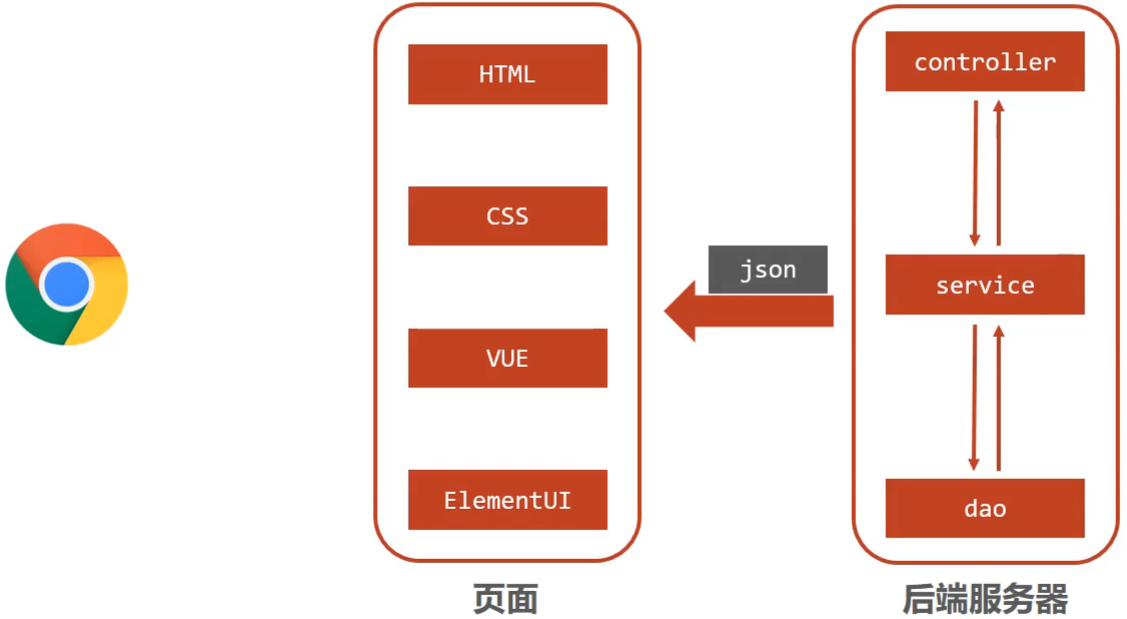
- 因为是异步调用,所以后端不需要返回view视图,将其去除
- 前端如果通过异步调用的方式进行交互,后台就需要将返回的数据转换成json格式进行返回
- SpringMVC==主要==负责的就是
- controller如何接收请求和数据
- 如何将请求和数据转发给业务层
- 如何将响应数据转换成json发回到前端
介绍了这么多,对SpringMVC进行一个定义
SpringMVC是一种基于Java实现MVC模型的轻量级Web框架
优点
- 使用简单、开发便捷(相比于Servlet)
- 灵活性强
这里所说的优点,就需要我们在使用的过程中慢慢体会。
另外,因为SpringMVC是一个Web框架,将来是要替换Servlet,所以先来回顾下以前Servlet是如何进行开发的?
1.创建web工程(Maven结构)
2.设置tomcat服务器,加载web工程(tomcat插件)
3.导入坐标(Servlet)
4.定义处理请求的功能类(UserServlet)
5.设置请求映射(配置映射关系)
SpringMVC的制作过程和上述流程几乎是一致的,具体的实现流程是什么?
1.创建web工程(Maven结构)
2.设置tomcat服务器,加载web工程(tomcat插件)
3.导入坐标(==SpringMVC==+Servlet)
4.定义处理请求的功能类(==UserController==)
5.==设置请求映射(配置映射关系)==
6.==将SpringMVC设定加载到Tomcat容器中==
入门案例总结
- 一次性工作
- 创建工程,设置服务器,加载工程
- 导入坐标
- 创建web容器启动类,加载SpringMVC配置,并设置SpringMVC请求拦截路径
- SpringMVC核心配置类(设置配置类,扫描controller包,加载Controller控制器bean)
- 多次工作
- 定义处理请求的控制器类
- 定义处理请求的控制器方法,并配置映射路径(@RequestMapping)与返回json数据(@ResponseBody)
知识点1:@Controller
| 名称 | @Controller |
|---|---|
| 类型 | 类注解 |
| 位置 | SpringMVC控制器类定义上方 |
| 作用 | 设定SpringMVC的核心控制器bean |
知识点2:@RequestMapping
| 名称 | @RequestMapping |
|---|---|
| 类型 | 类注解或方法注解 |
| 位置 | SpringMVC控制器类或方法定义上方 |
| 作用 | 设置当前控制器方法请求访问路径 |
| 相关属性 | value(默认),请求访问路径 |
知识点3:@ResponseBody
| 名称 | @ResponseBody |
|---|---|
| 类型 | 类注解或方法注解 |
| 位置 | SpringMVC控制器类或方法定义上方 |
| 作用 | 设置当前控制器方法响应内容为当前返回值,无需解析 |
知识点4:@ComponentScan
| 名称 | @ComponentScan |
|---|---|
| 类型 | 类注解 |
| 位置 | 类定义上方 |
| 作用 | 设置spring配置类扫描路径,用于加载使用注解格式定义的bean |
| 相关属性 | excludeFilters:排除扫描路径中加载的bean,需要指定类别(type)和具体项(classes) includeFilters:加载指定的bean,需要指定类别(type)和具体项(classes) |
知识点5:@RequestParam
| 名称 | @RequestParam |
|---|---|
| 类型 | 形参注解 |
| 位置 | SpringMVC控制器方法形参定义前面 |
| 作用 | 绑定请求参数与处理器方法形参间的关系 |
| 相关参数 | required:是否为必传参数 defaultValue:参数默认值 |
知识点6:@EnableWebMvc
| 名称 | @EnableWebMvc |
|---|---|
| 类型 | ==配置类注解== |
| 位置 | SpringMVC配置类定义上方 |
| 作用 | 开启SpringMVC多项辅助功能 |
知识点7:@RequestBody
| 名称 | @RequestBody |
|---|---|
| 类型 | ==形参注解== |
| 位置 | SpringMVC控制器方法形参定义前面 |
| 作用 | 将请求中请求体所包含的数据传递给请求参数,此注解一个处理器方法只能使用一次 |
@RequestBody与@RequestParam区别
区别
- @RequestParam用于接收url地址传参,表单传参【application/x-www-form-urlencoded】
- @RequestBody用于接收json数据【application/json】
应用
- 后期开发中,发送json格式数据为主,@RequestBody应用较广
- 如果发送非json格式数据,选用@RequestParam接收请求参数
知识点8:@DateTimeFormat
| 名称 | @DateTimeFormat |
|---|---|
| 类型 | ==形参注解== |
| 位置 | SpringMVC控制器方法形参前面 |
| 作用 | 设定日期时间型数据格式 |
| 相关属性 | pattern:指定日期时间格式字符串 |
知识点9:@ResponseBody
| 名称 | @ResponseBody |
|---|---|
| 类型 | ==方法\类注解== |
| 位置 | SpringMVC控制器方法定义上方和控制类上 |
| 作用 | 设置当前控制器返回值作为响应体, 写在类上,该类的所有方法都有该注解功能 |
| 相关属性 | pattern:指定日期时间格式字符串 |
说明:
- 该注解可以写在类上或者方法上
- 写在类上就是该类下的所有方法都有@ReponseBody功能
- 当方法上有@ReponseBody注解后
- 方法的返回值为字符串,会将其作为文本内容直接响应给前端
- 方法的返回值为对象,会将对象转换成JSON响应给前端
此处又使用到了类型转换,内部还是通过Converter接口的实现类完成的,所以Converter除了前面所说的功能外,它还可以实现:
- 对象转Json数据(POJO -> json)
- 集合转Json数据(Collection -> json)
知识点10:@RestController
| 名称 | @RestController |
|---|---|
| 类型 | ==类注解== |
| 位置 | 基于SpringMVC的RESTful开发控制器类定义上方 |
| 作用 | 设置当前控制器类为RESTful风格, 等同于@Controller与@ResponseBody两个注解组合功能 |
知识点11:@GetMapping @PostMapping @PutMapping @DeleteMapping
| 名称 | @GetMapping @PostMapping @PutMapping @DeleteMapping |
|---|---|
| 类型 | ==方法注解== |
| 位置 | 基于SpringMVC的RESTful开发控制器方法定义上方 |
| 作用 | 设置当前控制器方法请求访问路径与请求动作,每种对应一个请求动作, 例如@GetMapping对应GET请求 |
| 相关属性 | value(默认):请求访问路径 |
知识点12:@PathVariable
| 名称 | @PathVariable |
|---|---|
| 类型 | ==形参注解== |
| 位置 | SpringMVC控制器方法形参定义前面 |
| 作用 | 绑定路径参数与处理器方法形参间的关系,要求路径参数名与形参名一一对应 |
关于接收参数,我们学过三个注解@RequestBody、@RequestParam、@PathVariable,这三个注解之间的区别和应用分别是什么?
- 区别
- @RequestParam用于接收url地址传参或表单传参
- @RequestBody用于接收json数据
- @PathVariable用于接收路径参数,使用{参数名称}描述路径参数
- 应用
- 后期开发中,发送请求参数超过1个时,以json格式为主,@RequestBody应用较广
- 如果发送非json格式数据,选用@RequestParam接收请求参数
- 采用RESTful进行开发,当参数数量较少时,例如1个,可以采用@PathVariable接收请求路径变量,通常用于传递id值
Rest风格
对于Rest风格,我们需要学习的内容包括:
- REST简介
- REST入门案例
- REST快速开发
- 案例:基于RESTful页面数据交互
REST简介
==REST==(Representational State Transfer),表现形式状态转换,它是一种软件架构==风格==
当我们想表示一个网络资源的时候,可以使用两种方式:
- 传统风格资源描述形式
http://localhost/user/getById?id=1查询id为1的用户信息http://localhost/user/saveUser保存用户信息
- REST风格描述形式
http://localhost/user/1http://localhost/user
- 传统风格资源描述形式
传统方式一般是一个请求url对应一种操作,这样做不仅麻烦,也不安全,因为会程序的人读取了你的请求url地址,就大概知道该url实现的是一个什么样的操作。
查看REST风格的描述,你会发现请求地址变的简单了,并且光看请求URL并不是很能猜出来该URL的具体功能
所以REST的优点有:
- 隐藏资源的访问行为,无法通过地址得知对资源是何种操作
- 书写简化
但是我们的问题也随之而来了,一个相同的url地址即可以是新增也可以是修改或者查询,那么到底我们该如何区分该请求到底是什么操作呢?
- 按照REST风格访问资源时使用==行为动作==区分对资源进行了何种操作
http://localhost/users查询全部用户信息 GET(查询)http://localhost/users/1查询指定用户信息 GET(查询)http://localhost/users添加用户信息 POST(新增/保存)http://localhost/users修改用户信息 PUT(修改/更新)http://localhost/users/1删除用户信息 DELETE(删除)
请求的方式比较多,但是比较常用的就4种,分别是GET,POST,PUT,DELETE。
按照不同的请求方式代表不同的操作类型。
- 发送GET请求是用来做查询
- 发送POST请求是用来做新增
- 发送PUT请求是用来做修改
- 发送DELETE请求是用来做删除
但是==注意==:
- 上述行为是约定方式,约定不是规范,可以打破,所以称REST风格,而不是REST规范
- REST提供了对应的架构方式,按照这种架构设计项目可以降低开发的复杂性,提高系统的可伸缩性
- REST中规定GET/POST/PUT/DELETE针对的是查询/新增/修改/删除,但是我们如果非要用GET请求做删除,这点在程序上运行是可以实现的
- 但是如果绝大多数人都遵循这种风格,你写的代码让别人读起来就有点莫名其妙了。
- 描述模块的名称通常使用复数,也就是加s的格式描述,表示此类资源,而非单个资源,例如:users、books、accounts……
清楚了什么是REST风格后,我们后期会经常提到一个概念叫RESTful,那什么又是RESTful呢?
- 根据REST风格对资源进行访问称为==RESTful==。
后期我们在进行开发的过程中,大多是都是遵从REST风格来访问我们的后台服务,所以可以说咱们以后都是基于RESTful来进行开发的。
SSM整合
前面我们已经把Mybatis、Spring和SpringMVC三个框架进行了学习,今天主要的内容就是把这三个框架整合在一起完成我们的业务功能开发,具体如何来整合,我们一步步来学习。
1 流程分析
(1) 创建工程
- 创建一个Maven的web工程
- pom.xml添加SSM需要的依赖jar包
- 编写Web项目的入口配置类,实现
AbstractAnnotationConfigDispatcherServletInitializer重写以下方法- getRootConfigClasses() :返回Spring的配置类->需要==SpringConfig==配置类
- getServletConfigClasses() :返回SpringMVC的配置类->需要==SpringMvcConfig==配置类
- getServletMappings() : 设置SpringMVC请求拦截路径规则
- getServletFilters() :设置过滤器,解决POST请求中文乱码问题
(2)SSM整合[==重点是各个配置的编写==]
- SpringConfig
- 标识该类为配置类 @Configuration
- 扫描Service所在的包 @ComponentScan
- 在Service层要管理事务 @EnableTransactionManagement
- 读取外部的properties配置文件 @PropertySource
- 整合Mybatis需要引入Mybatis相关配置类 @Import
- 第三方数据源配置类 JdbcConfig
- 构建DataSource数据源,DruidDataSouroce,需要注入数据库连接四要素, @Bean @Value
- 构建平台事务管理器,DataSourceTransactionManager,@Bean
- Mybatis配置类 MybatisConfig
- 构建SqlSessionFactoryBean并设置别名扫描与数据源,@Bean
- 构建MapperScannerConfigurer并设置DAO层的包扫描
- 第三方数据源配置类 JdbcConfig
- SpringMvcConfig
- 标识该类为配置类 @Configuration
- 扫描Controller所在的包 @ComponentScan
- 开启SpringMVC注解支持 @EnableWebMvc
(3)功能模块[与具体的业务模块有关]
- 创建数据库表
- 根据数据库表创建对应的模型类
- 通过Dao层完成数据库表的增删改查(接口+自动代理)
- 编写Service层[Service接口+实现类]
- @Service
- @Transactional
- 整合Junit对业务层进行单元测试
- @RunWith
- @ContextConfiguration
- @Test
- 编写Controller层
- 接收请求 @RequestMapping @GetMapping @PostMapping @PutMapping @DeleteMapping
- 接收数据 简单、POJO、嵌套POJO、集合、数组、JSON数据类型
- @RequestParam
- @PathVariable
- @RequestBody
- 转发业务层
- @Autowired
- 响应结果
- @ResponseBody
2 整合配置
掌握上述的知识点后,接下来,我们就可以按照上述的步骤一步步的来完成SSM的整合。
步骤1:创建Maven的web项目
可以使用Maven的骨架创建
步骤2:添加依赖
pom.xml添加SSM所需要的依赖jar包
1 |
|
步骤3:创建项目包结构
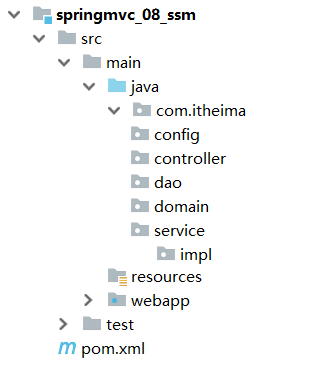
- config目录存放的是相关的配置类
- controller编写的是Controller类
- dao存放的是Dao接口,因为使用的是Mapper接口代理方式,所以没有实现类包
- service存的是Service接口,impl存放的是Service实现类
- resources:存入的是配置文件,如Jdbc.properties
- webapp:目录可以存放静态资源
- test/java:存放的是测试类
步骤4:创建SpringConfig配置类
1 |
|
步骤5:创建JdbcConfig配置类
1 | public class JdbcConfig { |
步骤6:创建MybatisConfig配置类
1 | public class MyBatisConfig { |
步骤7:创建jdbc.properties
在resources下提供jdbc.properties,设置数据库连接四要素
1 | =com.mysql.jdbc.Driver |
步骤8:创建SpringMVC配置类
1 |
|
步骤9:创建Web项目入口配置类
1 | public class ServletConfig extends AbstractAnnotationConfigDispatcherServletInitializer { |
至此SSM整合的环境就已经搭建好了。在这个环境上,我们如何进行功能模块的开发呢?
3 功能模块开发
需求:对表tbl_book进行新增、修改、删除、根据ID查询和查询所有
步骤1:创建数据库及表
1 | create database ssm_db character set utf8; |
步骤2:编写模型类
1 | public class Book { |
步骤3:编写Dao接口
1 | public interface BookDao { |
步骤4:编写Service接口和实现类
1 |
|
1 |
|
说明:
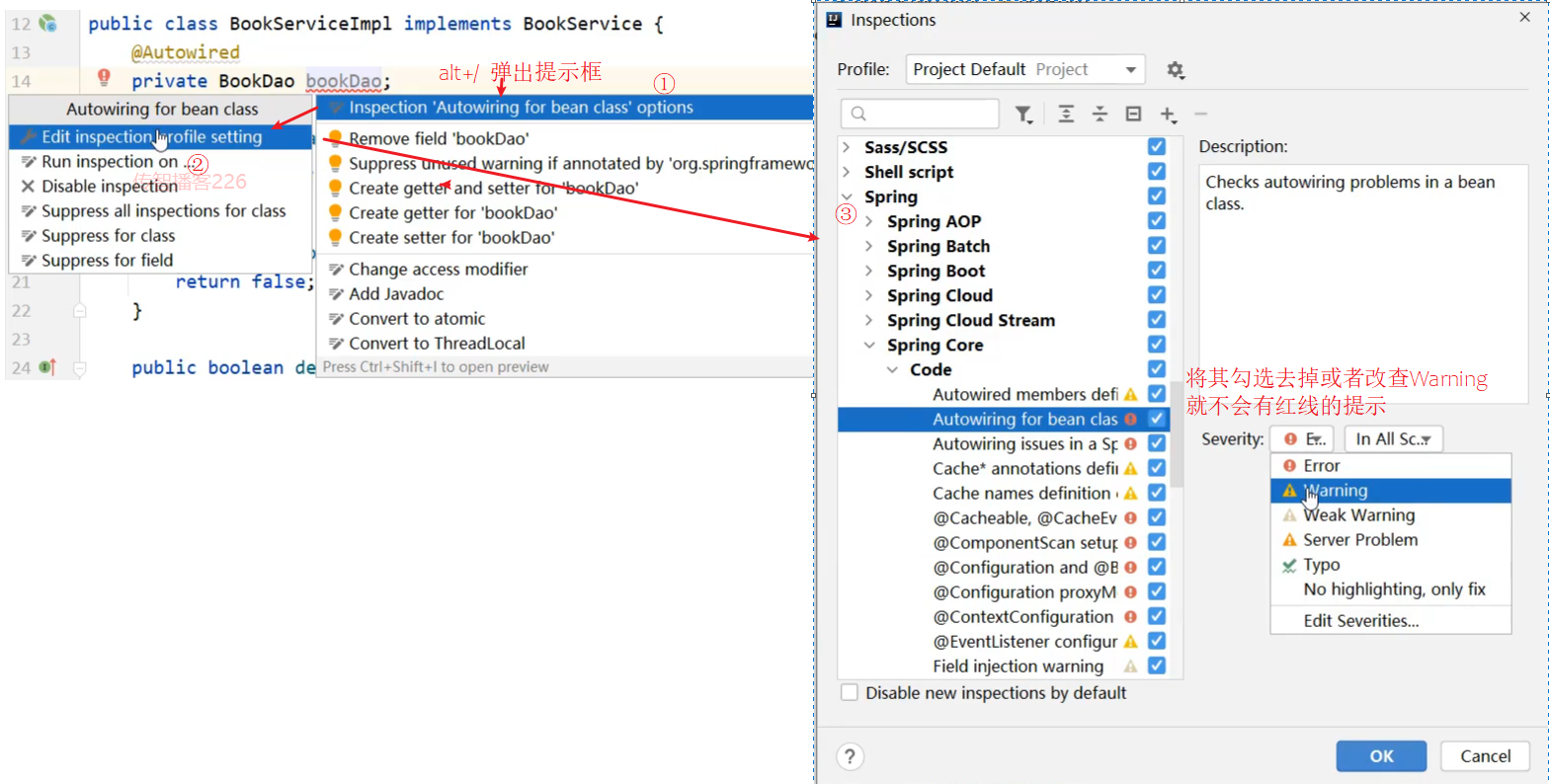
bookDao在Service中注入的会提示一个红线提示,为什么呢?
- BookDao是一个接口,没有实现类,接口是不能创建对象的,所以最终注入的应该是代理对象
- 代理对象是由Spring的IOC容器来创建管理的
- IOC容器又是在Web服务器启动的时候才会创建
- IDEA在检测依赖关系的时候,没有找到适合的类注入,所以会提示错误提示
- 但是程序运行的时候,代理对象就会被创建,框架会使用DI进行注入,所以程序运行无影响。
如何解决上述问题?
可以不用理会,因为运行是正常的
设置错误提示级别
步骤5:编写Contorller类
1 |
|
对于图书模块的增删改查就已经完成了编写,我们可以从后往前写也可以从前往后写,最终只需要能把功能实现即可。
接下来我们就先把业务层的代码使用Spring整合Junit的知识点进行单元测试:
4 单元测试
步骤1:新建测试类
1 |
|
步骤2:注入Service类
1 |
|
步骤3:编写测试方法
我们先来对查询进行单元测试。
1 |
|
根据ID查询,测试的结果为:

查询所有,测试的结果为:

5 PostMan测试
新增
http://localhost/books
1 | { |
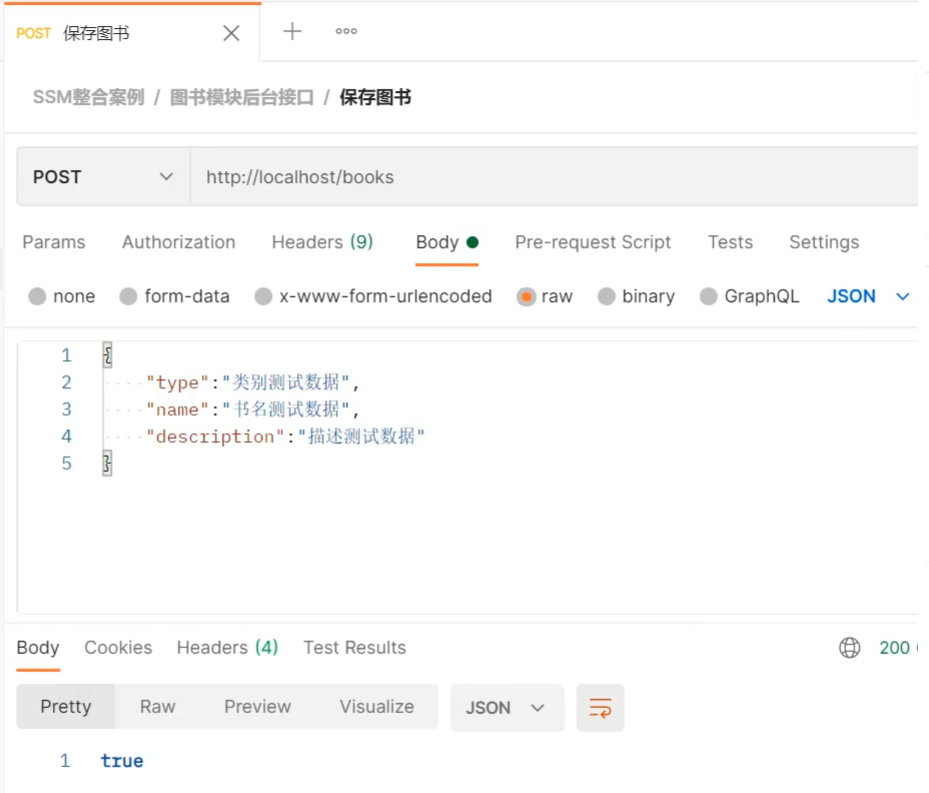
统一结果封装
1 表现层与前端数据传输协议定义
SSM整合以及功能模块开发完成后,接下来,我们在上述案例的基础上分析下有哪些问题需要我们去解决下。首先第一个问题是:
在Controller层增删改返回给前端的是boolean类型数据

在Controller层查询单个返回给前端的是对象

在Controller层查询所有返回给前端的是集合对象

目前我们就已经有三种数据类型返回给前端,如果随着业务的增长,我们需要返回的数据类型会越来越多。对于前端开发人员在解析数据的时候就比较凌乱了,所以对于前端来说,如果后台能够返回一个统一的数据结果,前端在解析的时候就可以按照一种方式进行解析。开发就会变得更加简单。
所以我们就想能不能将返回结果的数据进行统一,具体如何来做,大体的思路为:
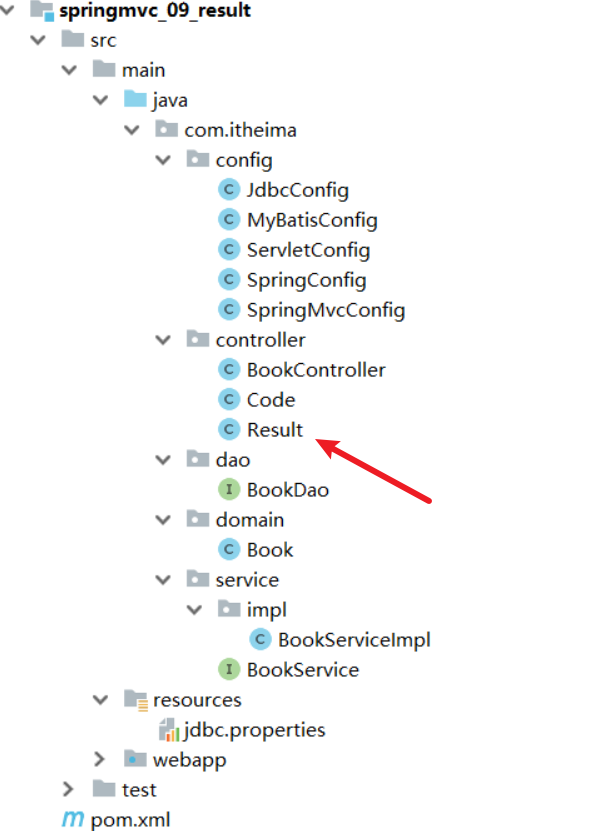
- 为了封装返回的结果数据:==创建结果模型类,封装数据到data属性中==
- 为了封装返回的数据是何种操作及是否操作成功:==封装操作结果到code属性中==
- 操作失败后为了封装返回的错误信息:==封装特殊消息到message(msg)属性中==

根据分析,我们可以设置统一数据返回结果类
1 | public class Result{ |
**注意:**Result类名及类中的字段并不是固定的,可以根据需要自行增减提供若干个构造方法,方便操作。
2 结果封装
对于结果封装,我们应该是在表现层进行处理,所以我们把结果类放在controller包下,当然你也可以放在domain包,这个都是可以的,具体如何实现结果封装,具体的步骤为:
步骤1:创建Result类
1 | public class Result { |
步骤2:定义返回码Code类
1 | //状态码 |
**注意:**code类中的常量设计也不是固定的,可以根据需要自行增减,例如将查询再进行细分为GET_OK,GET_ALL_OK,GET_PAGE_OK等。
步骤3:修改Controller类的返回值
1 | //统一每一个控制器方法返回值 |
步骤4:启动服务测试
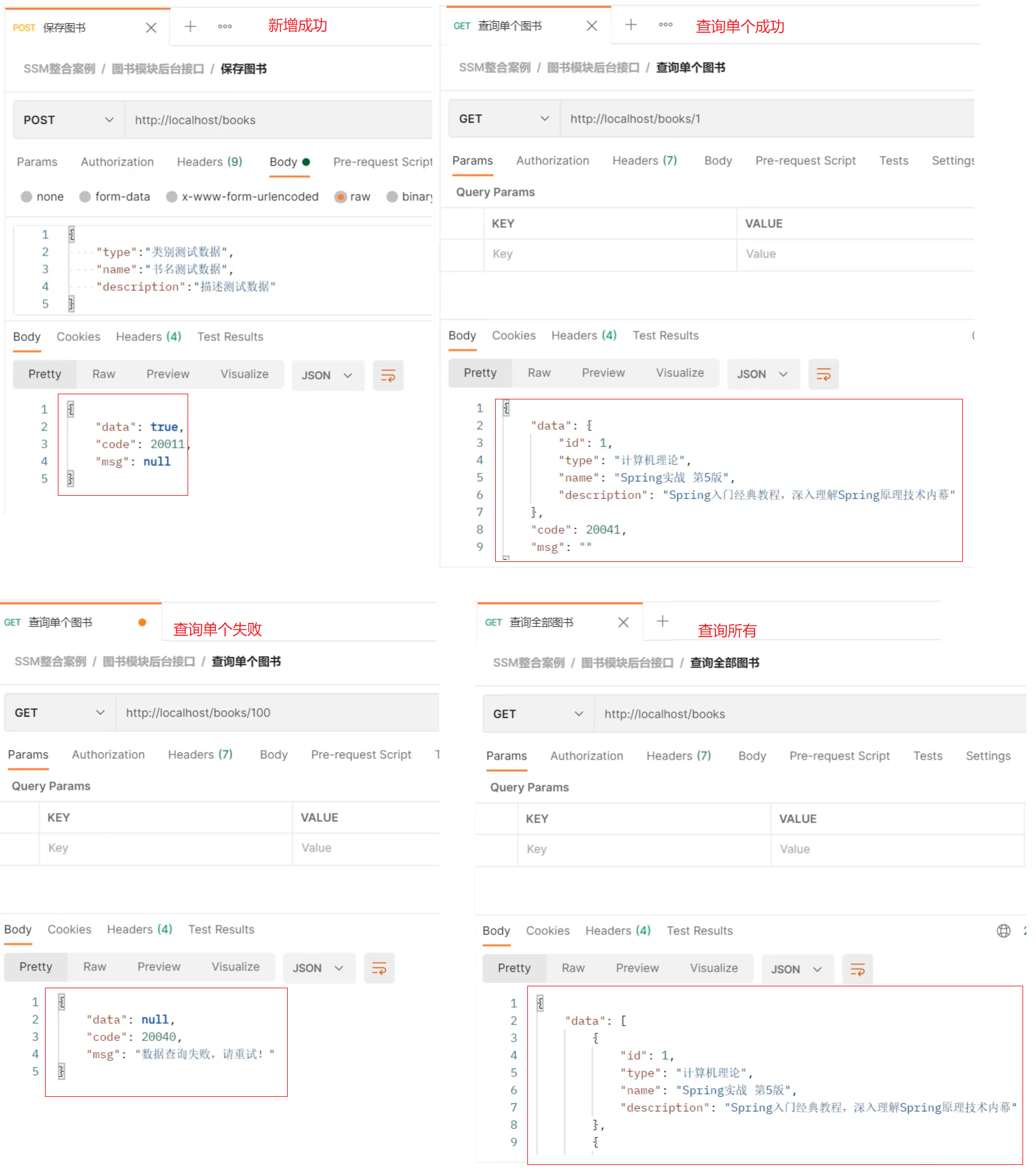
至此,我们的返回结果就已经能以一种统一的格式返回给前端。前端根据返回的结果,先从中获取code,根据code判断,如果成功则取data属性的值,如果失败,则取msg中的值做提示。
统一异常处理
1 问题描述
在讲解这一部分知识点之前,我们先来演示个效果,修改BookController类的getById方法
1 |
|
重新启动运行项目,使用PostMan发送请求,当传入的id为1,则会出现如下效果:
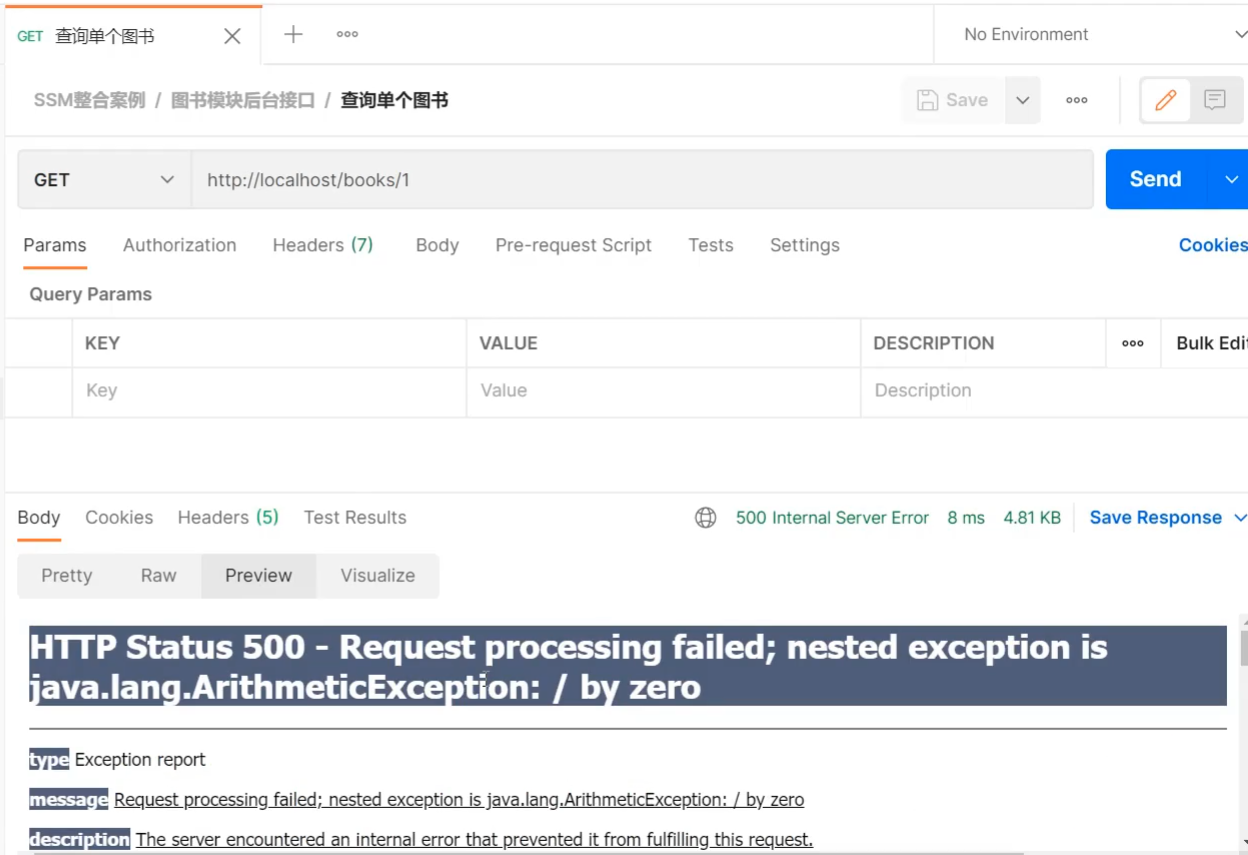
前端接收到这个信息后和之前我们约定的格式不一致,这个问题该如何解决?
在解决问题之前,我们先来看下异常的种类及出现异常的原因:
- 框架内部抛出的异常:因使用不合规导致
- 数据层抛出的异常:因外部服务器故障导致(例如:服务器访问超时)
- 业务层抛出的异常:因业务逻辑书写错误导致(例如:遍历业务书写操作,导致索引异常等)
- 表现层抛出的异常:因数据收集、校验等规则导致(例如:不匹配的数据类型间导致异常)
- 工具类抛出的异常:因工具类书写不严谨不够健壮导致(例如:必要释放的连接长期未释放等)
看完上面这些出现异常的位置,你会发现,在我们开发的任何一个位置都有可能出现异常,而且这些异常是不能避免的。所以我们就得将异常进行处理。
思考
各个层级均出现异常,异常处理代码书写在哪一层?
==所有的异常均抛出到表现层进行处理==
异常的种类很多,表现层如何将所有的异常都处理到呢?
==异常分类==
表现层处理异常,每个方法中单独书写,代码书写量巨大且意义不强,如何解决?
==AOP==
对于上面这些问题及解决方案,SpringMVC已经为我们提供了一套解决方案:
异常处理器:
集中的、统一的处理项目中出现的异常。

知识点1:@RestControllerAdvice
| 名称 | @RestControllerAdvice |
|---|---|
| 类型 | ==类注解== |
| 位置 | Rest风格开发的控制器增强类定义上方 |
| 作用 | 为Rest风格开发的控制器类做增强 |
**说明:**此注解自带@ResponseBody注解与@Component注解,具备对应的功能

知识点2:@ExceptionHandler
| 名称 | @ExceptionHandler |
|---|---|
| 类型 | ==方法注解== |
| 位置 | 专用于异常处理的控制器方法上方 |
| 作用 | 设置指定异常的处理方案,功能等同于控制器方法, 出现异常后终止原始控制器执行,并转入当前方法执行 |
说明:此类方法可以根据处理的异常不同,制作多个方法分别处理对应的异常
项目异常处理方案
1 异常分类
异常处理器我们已经能够使用了,那么在咱们的项目中该如何来处理异常呢?
因为异常的种类有很多,如果每一个异常都对应一个@ExceptionHandler,那得写多少个方法来处理各自的异常,所以我们在处理异常之前,需要对异常进行一个分类:
业务异常(BusinessException)
规范的用户行为产生的异常
用户在页面输入内容的时候未按照指定格式进行数据填写,如在年龄框输入的是字符串
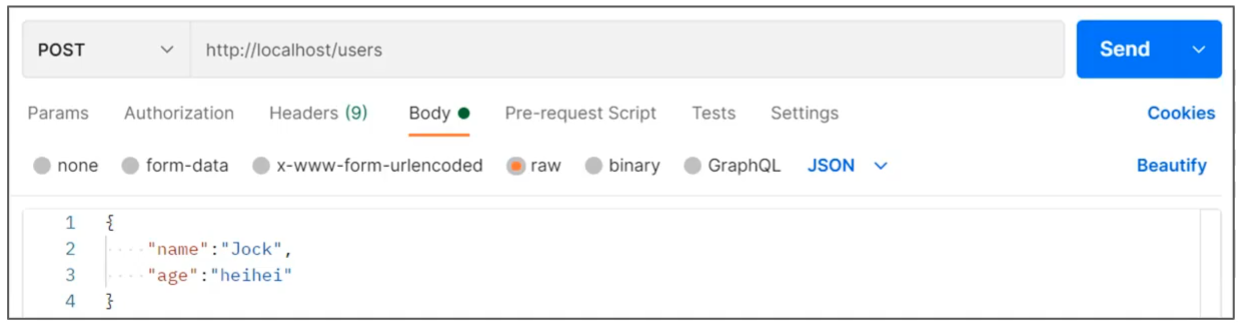
不规范的用户行为操作产生的异常
如用户故意传递错误数据

系统异常(SystemException)
- 项目运行过程中可预计但无法避免的异常
- 比如数据库或服务器宕机
- 项目运行过程中可预计但无法避免的异常
其他异常(Exception)
编程人员未预期到的异常,如:用到的文件不存在
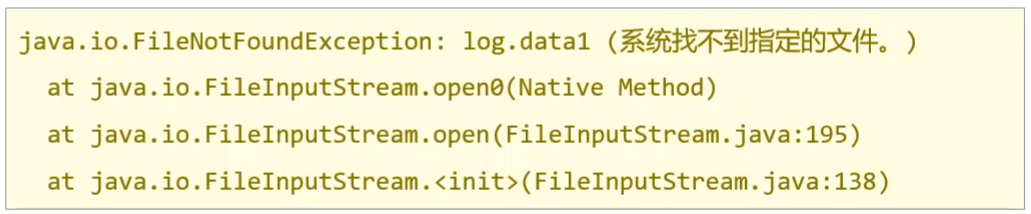
将异常分类以后,针对不同类型的异常,要提供具体的解决方案:
2 异常解决方案
- 业务异常(BusinessException)
- 发送对应消息传递给用户,提醒规范操作
- 大家常见的就是提示用户名已存在或密码格式不正确等
- 发送对应消息传递给用户,提醒规范操作
- 系统异常(SystemException)
- 发送固定消息传递给用户,安抚用户
- 系统繁忙,请稍后再试
- 系统正在维护升级,请稍后再试
- 系统出问题,请联系系统管理员等
- 发送特定消息给运维人员,提醒维护
- 可以发送短信、邮箱或者是公司内部通信软件
- 记录日志
- 发消息和记录日志对用户来说是不可见的,属于后台程序
- 发送固定消息传递给用户,安抚用户
- 其他异常(Exception)
- 发送固定消息传递给用户,安抚用户
- 发送特定消息给编程人员,提醒维护(纳入预期范围内)
- 一般是程序没有考虑全,比如未做非空校验等
- 记录日志
前后台协议联调
列表功能

需求:页面加载完后发送异步请求到后台获取列表数据进行展示。
1.找到页面的钩子函数,
created()2.
created()方法中调用了this.getAll()方法3.在getAll()方法中使用axios发送异步请求从后台获取数据
4.访问的路径为
http://localhost/books5.返回数据
返回数据res.data的内容如下:
1 | { |
发送方式:
1 | getAll() { |
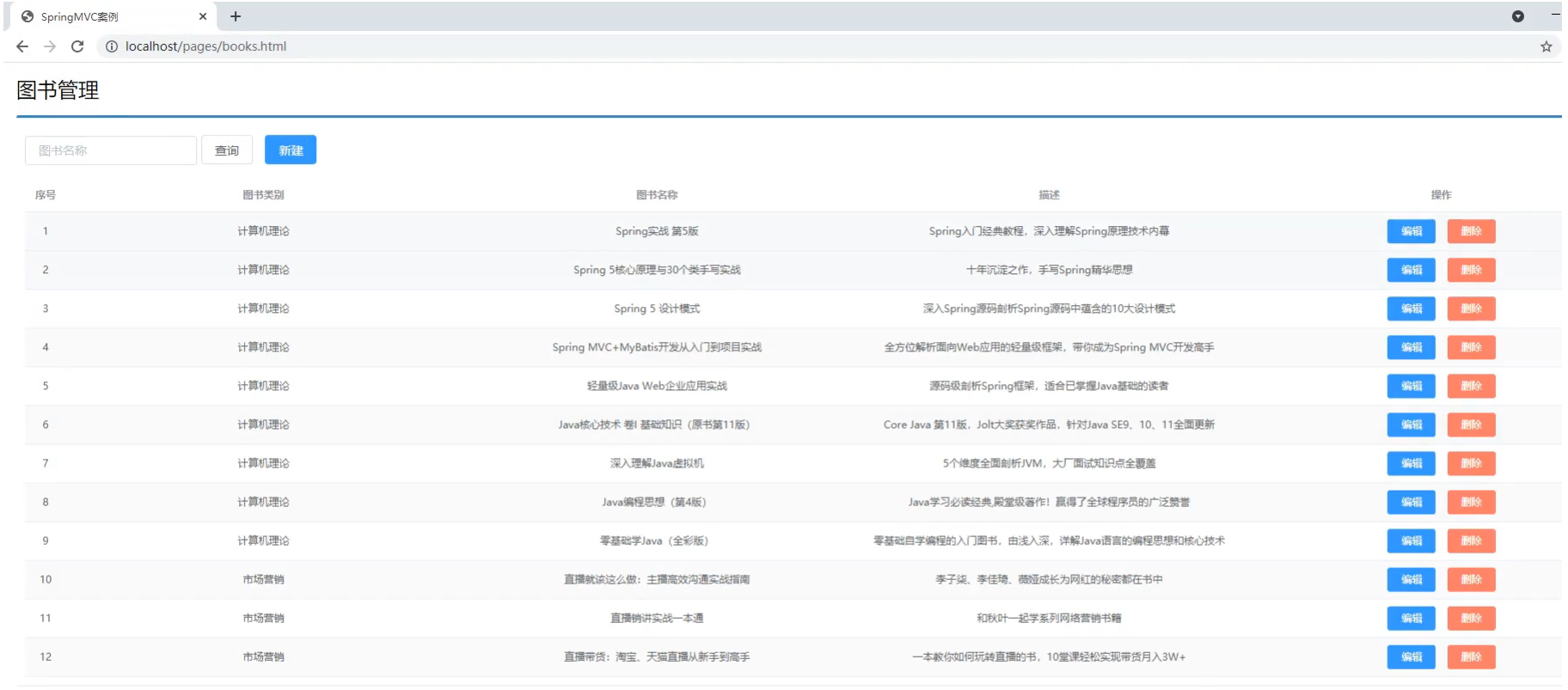
添加功能
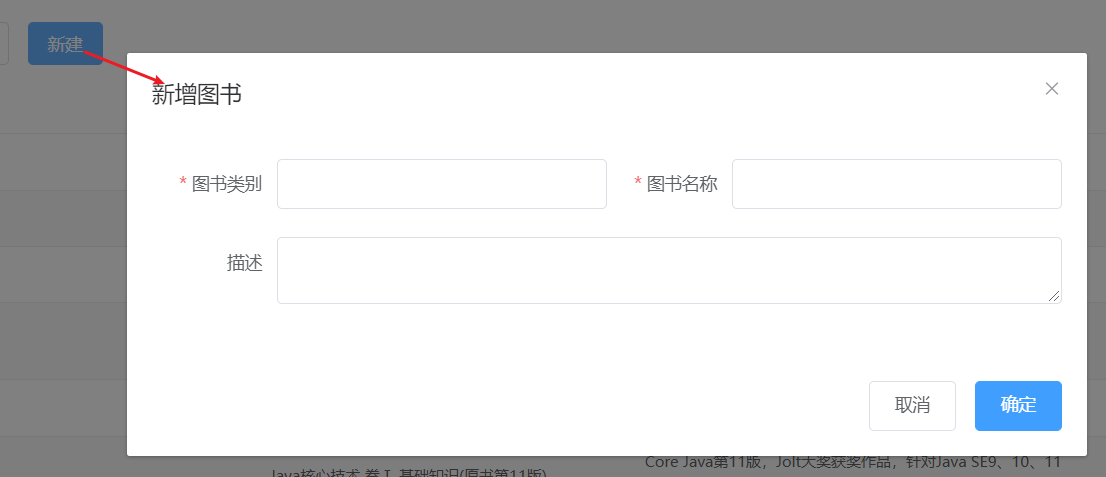
需求:完成图片的新增功能模块
1.找到页面上的
新建按钮,按钮上绑定了@click="handleCreate()"方法2.在method中找到
handleCreate方法,方法中打开新增面板3.新增面板中找到
确定按钮,按钮上绑定了@click="handleAdd()"方法4.在method中找到
handleAdd方法5.在方法中发送请求和数据,响应成功后将新增面板关闭并重新查询数据
handleCreate打开新增面板
1 | handleCreate() { |
handleAdd方法发送异步请求并携带数据
1 | handleAdd () { |
添加功能状态处理
基础的新增功能已经完成,但是还有一些问题需要解决下:
需求:新增成功是关闭面板,重新查询数据,那么新增失败以后该如何处理?
1.在handlerAdd方法中根据后台返回的数据来进行不同的处理
2.如果后台返回的是成功,则提示成功信息,并关闭面板
3.如果后台返回的是失败,则提示错误信息
(1)修改前端页面
1 | handleAdd () { |
(2)后台返回操作结果,将Dao层的增删改方法返回值从void改成int
1 | public interface BookDao { |
(3)在BookServiceImpl中,增删改方法根据DAO的返回值来决定返回true/false
1 |
|
(4)测试错误情况,将图书类别长度设置超出范围即可
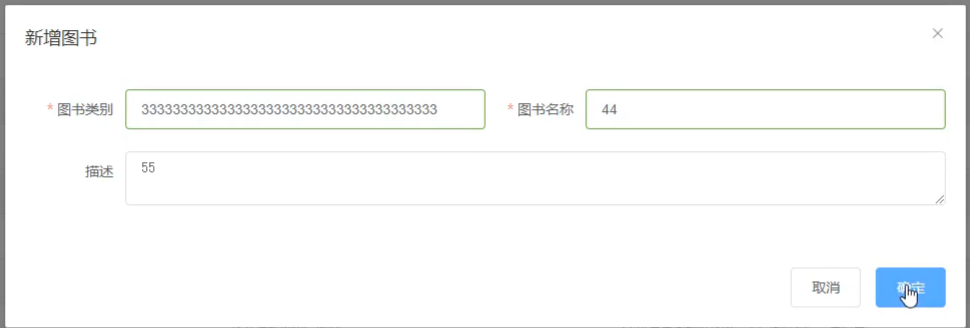
处理完新增后,会发现新增还存在一个问题,
新增成功后,再次点击新增按钮会发现之前的数据还存在,这个时候就需要在新增的时候将表单内容清空。
1 | resetForm(){ |
修改功能
需求:完成图书信息的修改功能
1.找到页面中的
编辑按钮,该按钮绑定了@click="handleUpdate(scope.row)"2.在method的
handleUpdate方法中发送异步请求根据ID查询图书信息3.根据后台返回的结果,判断是否查询成功
如果查询成功打开修改面板回显数据,如果失败提示错误信息
4.修改完成后找到修改面板的
确定按钮,该按钮绑定了@click="handleEdit()"5.在method的
handleEdit方法中发送异步请求提交修改数据6.根据后台返回的结果,判断是否修改成功
如果成功提示错误信息,关闭修改面板,重新查询数据,如果失败提示错误信息
scope.row代表的是当前行的行数据,也就是说,scope.row就是选中行对应的json数据,如下:
1 | { |
修改handleUpdate方法
1 | //弹出编辑窗口 |
修改handleEdit方法
1 | handleEdit() { |
至此修改功能就已经完成。
删除功能

需求:完成页面的删除功能。
1.找到页面的删除按钮,按钮上绑定了
@click="handleDelete(scope.row)"2.method的
handleDelete方法弹出提示框3.用户点击取消,提示操作已经被取消。
4.用户点击确定,发送异步请求并携带需要删除数据的主键ID
5.根据后台返回结果做不同的操作
如果返回成功,提示成功信息,并重新查询数据
如果返回失败,提示错误信息,并重新查询数据
修改handleDelete方法
1 | handleDelete(row) { |
拦截器
对于拦截器这节的知识,我们需要学习如下内容:
- 拦截器概念
- 入门案例
- 拦截器参数
- 拦截器工作流程分析
1 拦截器概念
讲解拦截器的概念之前,我们先看一张图:
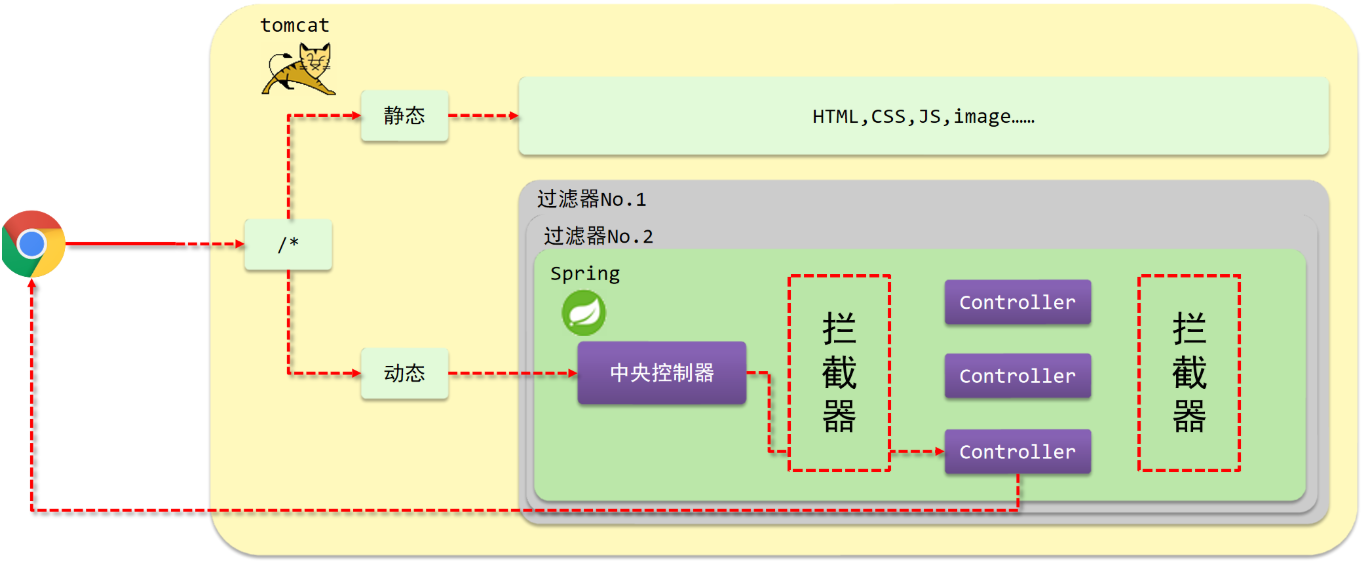
(1)浏览器发送一个请求会先到Tomcat的web服务器
(2)Tomcat服务器接收到请求以后,会去判断请求的是静态资源还是动态资源
(3)如果是静态资源,会直接到Tomcat的项目部署目录下去直接访问
(4)如果是动态资源,就需要交给项目的后台代码进行处理
(5)在找到具体的方法之前,我们可以去配置过滤器(可以配置多个),按照顺序进行执行
(6)然后进入到到中央处理器(SpringMVC中的内容),SpringMVC会根据配置的规则进行拦截
(7)如果满足规则,则进行处理,找到其对应的controller类中的方法进行执行,完成后返回结果
(8)如果不满足规则,则不进行处理
(9)这个时候,如果我们需要在每个Controller方法执行的前后添加业务,具体该如何来实现?
这个就是拦截器要做的事。
- 拦截器(Interceptor)是一种动态拦截方法调用的机制,在SpringMVC中动态拦截控制器方法的执行
- 作用:
- 在指定的方法调用前后执行预先设定的代码
- 阻止原始方法的执行
- 总结:拦截器就是用来做增强
看完以后,大家会发现
- 拦截器和过滤器在作用和执行顺序上也很相似
所以这个时候,就有一个问题需要思考:拦截器和过滤器之间的区别是什么?
- 归属不同:Filter属于Servlet技术,Interceptor属于SpringMVC技术
- 拦截内容不同:Filter对所有访问进行增强,Interceptor仅针对SpringMVC的访问进行增强

2 拦截器开发
步骤1:创建拦截器类
让类实现HandlerInterceptor接口,重写接口中的三个方法。
1 |
|
**注意:**拦截器类要被SpringMVC容器扫描到。
步骤2:配置拦截器类
1 |
|
步骤3:SpringMVC添加SpringMvcSupport包扫描
1 |
|
步骤4:运行程序测试
使用PostMan发送http://localhost/books

如果发送http://localhost/books/100会发现拦截器没有被执行,原因是拦截器的addPathPatterns方法配置的拦截路径是/books,我们现在发送的是/books/100,所以没有匹配上,因此没有拦截,拦截器就不会执行。
步骤5:修改拦截器拦截规则
1 |
|
这个时候,如果再次访问http://localhost/books/100,拦截器就会被执行。
最后说一件事,就是拦截器中的preHandler方法,如果返回true,则代表放行,会执行原始Controller类中要请求的方法,如果返回false,则代表拦截,后面的就不会再执行了。
步骤6:简化SpringMvcSupport的编写
1 |
|
此后咱们就不用再写SpringMvcSupport类了。
最后我们来看下拦截器的执行流程:
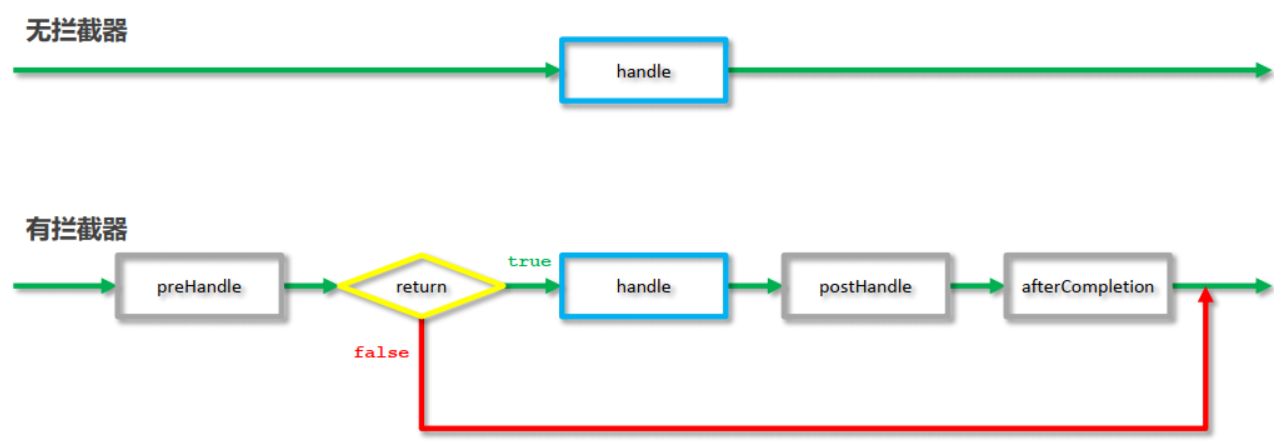
当有拦截器后,请求会先进入preHandle方法,
如果方法返回true,则放行继续执行后面的handle[controller的方法]和后面的方法
如果返回false,则直接跳过后面方法的执行。
3 拦截器参数
1 前置处理方法
原始方法之前运行preHandle
1 | public boolean preHandle(HttpServletRequest request, |
- request:请求对象
- response:响应对象
- handler:被调用的处理器对象,本质上是一个方法对象,对反射中的Method对象进行了再包装
使用request对象可以获取请求数据中的内容,如获取请求头的Content-Type
1 | public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { |
使用handler参数,可以获取方法的相关信息
1 | public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { |
2 后置处理方法
原始方法运行后运行,如果原始方法被拦截,则不执行
1 | public void postHandle(HttpServletRequest request, |
前三个参数和上面的是一致的。
modelAndView:如果处理器执行完成具有返回结果,可以读取到对应数据与页面信息,并进行调整
因为咱们现在都是返回json数据,所以该参数的使用率不高。
3 完成处理方法
拦截器最后执行的方法,无论原始方法是否执行
1 | public void afterCompletion(HttpServletRequest request, |
前三个参数与上面的是一致的。
ex:如果处理器执行过程中出现异常对象,可以针对异常情况进行单独处理
因为我们现在已经有全局异常处理器类,所以该参数的使用率也不高。
这三个方法中,最常用的是==preHandle==,在这个方法中可以通过返回值来决定是否要进行放行,我们可以把业务逻辑放在该方法中,如果满足业务则返回true放行,不满足则返回false拦截。
4 拦截器链配置
目前,我们在项目中只添加了一个拦截器,如果有多个,该如何配置?配置多个后,执行顺序是什么?
配置多个拦截器
步骤1:创建拦截器类
实现接口,并重写接口中的方法
1 |
|
步骤2:配置拦截器类
1 |
|
步骤3:运行程序,观察顺序
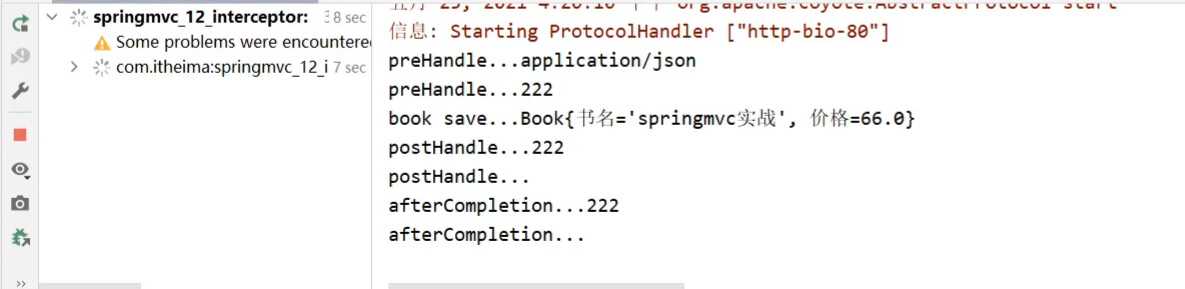
拦截器执行的顺序是和配置顺序有关。就和前面所提到的运维人员进入机房的案例,先进后出。
- 当配置多个拦截器时,形成拦截器链
- 拦截器链的运行顺序参照拦截器添加顺序为准
- 当拦截器中出现对原始处理器的拦截,后面的拦截器均终止运行
- 当拦截器运行中断,仅运行配置在前面的拦截器的afterCompletion操作
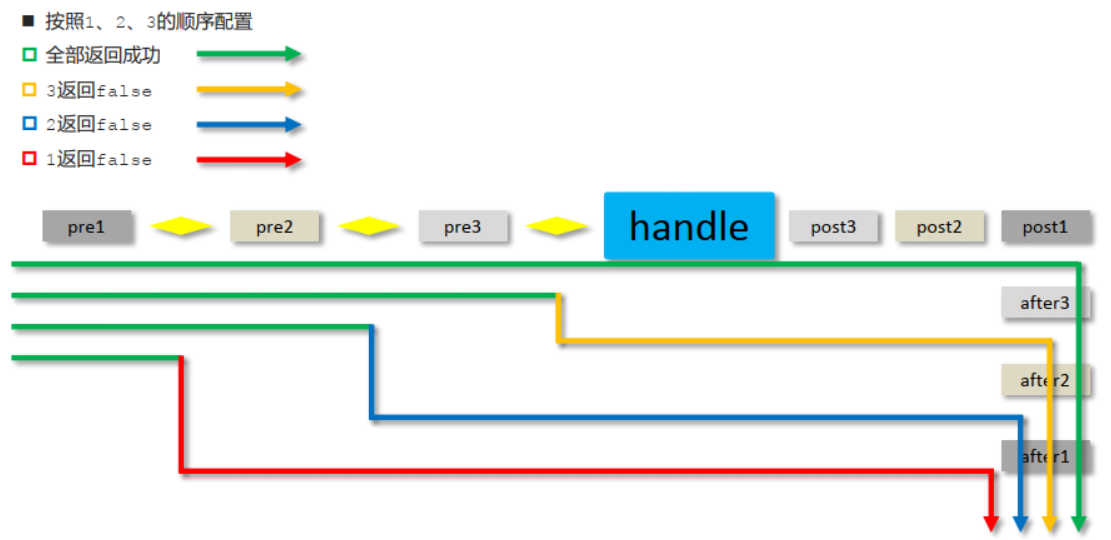
preHandle:与配置顺序相同,必定运行
postHandle:与配置顺序相反,可能不运行
afterCompletion:与配置顺序相反,可能不运行。
这个顺序不太好记,最终只需要把握住一个原则即可:==以最终的运行结果为准==
Maven高级
今日目标
- 理解并实现分模块开发
- 能够使用聚合工程快速构建项目
- 能够使用继承简化项目配置
- 能够根据需求配置生成、开发、测试环境,并在各个环境间切换运行
- 了解Maven的私服
1.1 分模块开发设计
(1)按照功能拆分
我们现在的项目都是在一个模块中,比如前面的SSM整合开发。虽然这样做功能也都实现了,但是也存在了一些问题,我们拿银行的项目为例来聊聊这个事。
- 网络没有那么发达的时候,我们需要到银行柜台或者取款机进行业务操作
- 随着互联网的发展,我们有了电脑以后,就可以在网页上登录银行网站使用U盾进行业务操作
- 再来就是随着智能手机的普及,我们只需要用手机登录APP就可以进行业务操作
上面三个场景出现的时间是不相同的,如果非要把三个场景的模块代码放入到一个项目,那么当其中某一个模块代码出现问题,就会导致整个项目无法正常启动,从而导致银行的多个业务都无法正常班理。所以我们会==按照功能==将项目进行拆分。
(2)按照模块拆分
比如电商的项目中,有订单和商品两个模块,订单中需要包含商品的详细信息,所以需要商品的模型类,商品模块也会用到商品的模型类,这个时候如果两个模块中都写模型类,就会出现重复代码,后期的维护成本就比较高。我们就想能不能将它们公共的部分抽取成一个独立的模块,其他模块要想使用可以像添加第三方jar包依赖一样来使用我们自己抽取的模块,这样就解决了代码重复的问题,这种拆分方式就说我们所说的==按照模块==拆分。
经过两个案例的分析,我们就知道:
- 将原始模块按照功能拆分成若干个子模块,方便模块间的相互调用,接口共享。
刚刚我们说了可以将domain层进行拆分,除了domain层,我们也可以将其他的层也拆成一个个对立的模块,如:
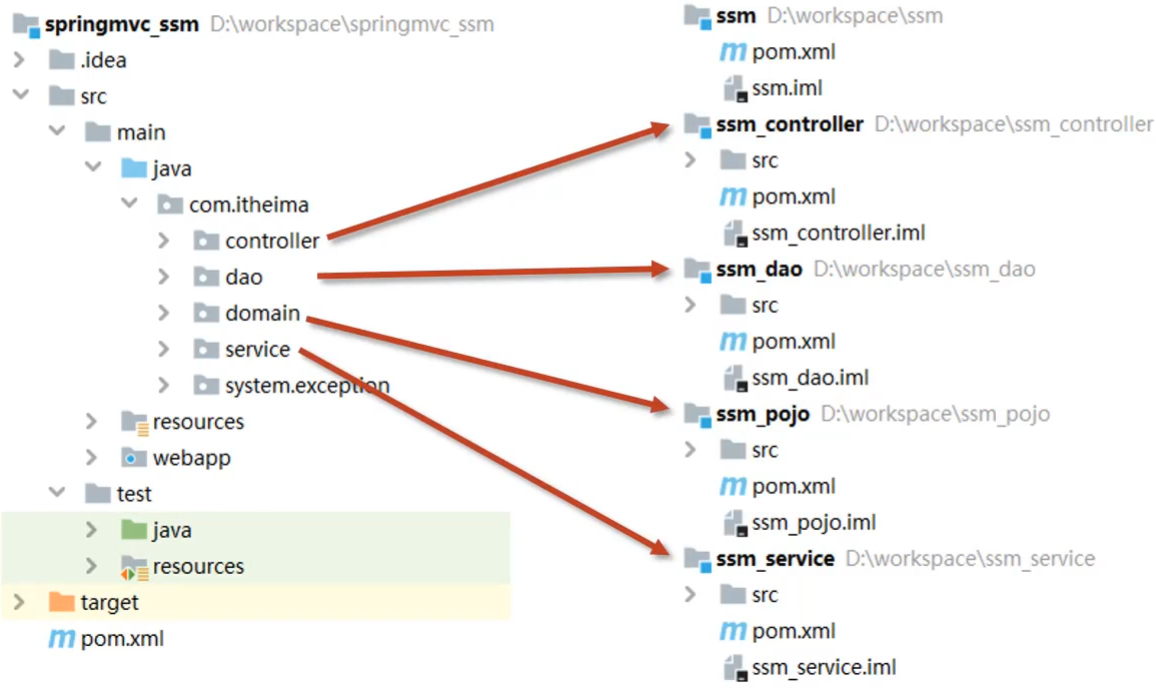
这样的话,项目中的每一层都可以单独维护,也可以很方便的被别人使用。关于分模块开发的意义,我们就说完了,说了这么多好处,那么该如何实现呢?
1.2 分模块开发实现
前面我们已经完成了SSM整合,接下来,咱们就基于SSM整合的项目来实现对项目的拆分。
1.2.1 环境准备
将资料\maven_02_ssm部署到IDEA中,将环境快速准备好,部署成功后,项目的格式如下:
1.2.2 抽取domain层
步骤1:创建新模块
创建一个名称为maven_03_pojo的jar项目,为什么项目名是从02到03这样创建,原因后面我们会提到,这块的名称可以任意。
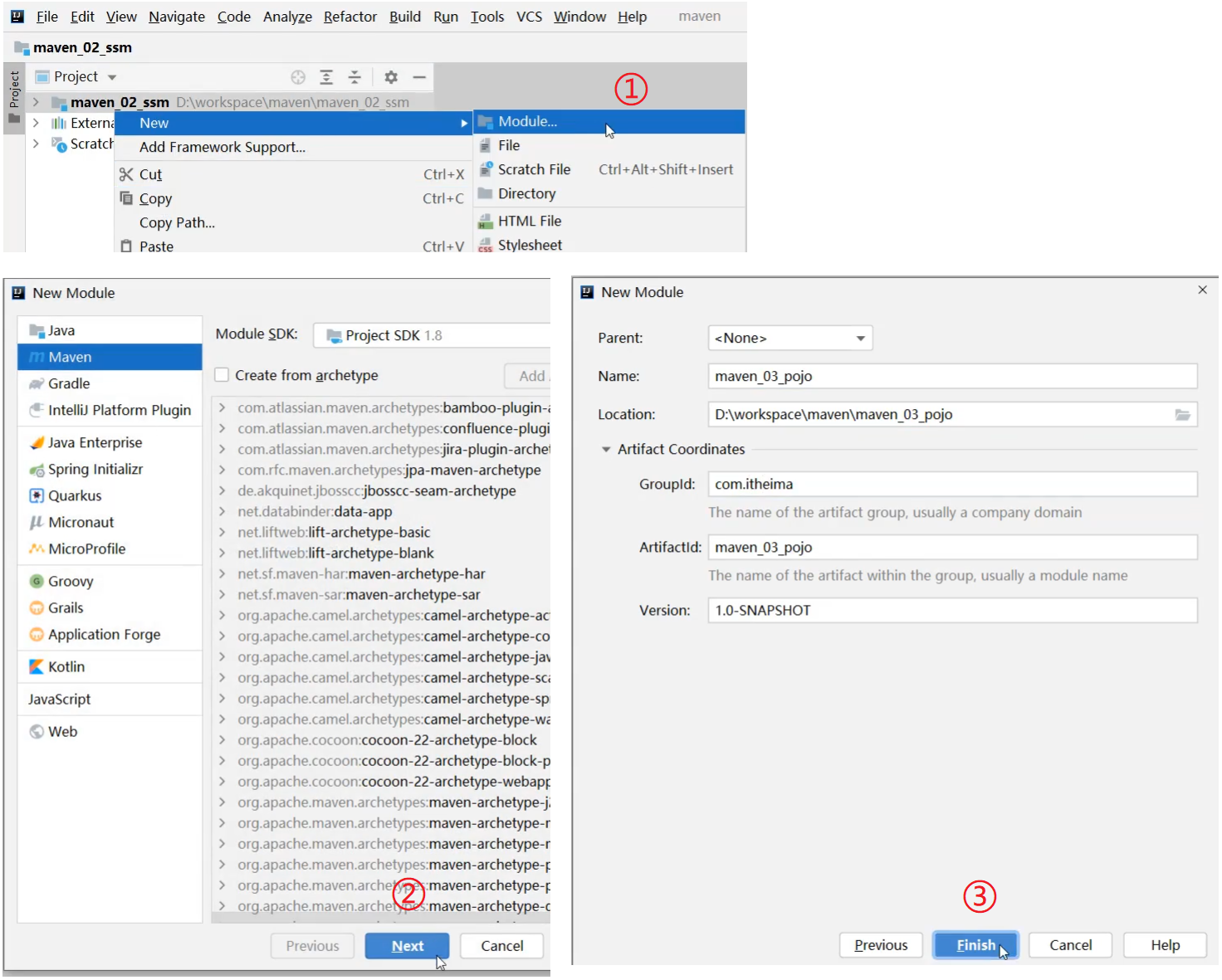
步骤2:项目中创建domain包
在maven_03_pojo项目中创建com.itheima.domain包,并将maven_02_ssm中Book类拷贝到该包中

步骤3:删除原项目中的domain包
删除后,maven_02_ssm项目中用到Book的类中都会有红色提示,如下:
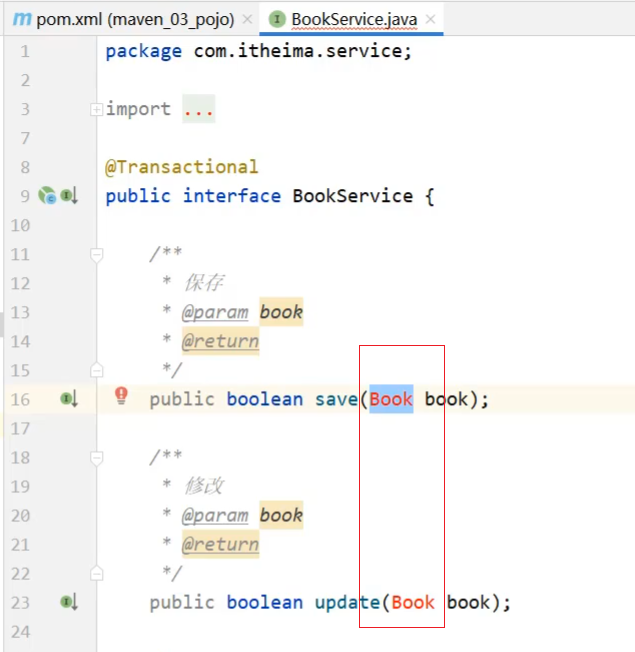
**说明:**出错的原因是maven_02_ssm中已经将Book类删除,所以该项目找不到Book类,所以报错
要想解决上述问题,我们需要在maven_02_ssm中添加maven_03_pojo的依赖。
步骤4:建立依赖关系
在maven_02_ssm项目的pom.xml添加maven_03_pojo的依赖
1 | <dependency> |
因为添加了依赖,所以在maven_02_ssm中就已经能找到Book类,所以刚才的报红提示就会消失。
步骤5:编译maven_02_ssm项目
编译maven_02_ssm你会在控制台看到如下错误
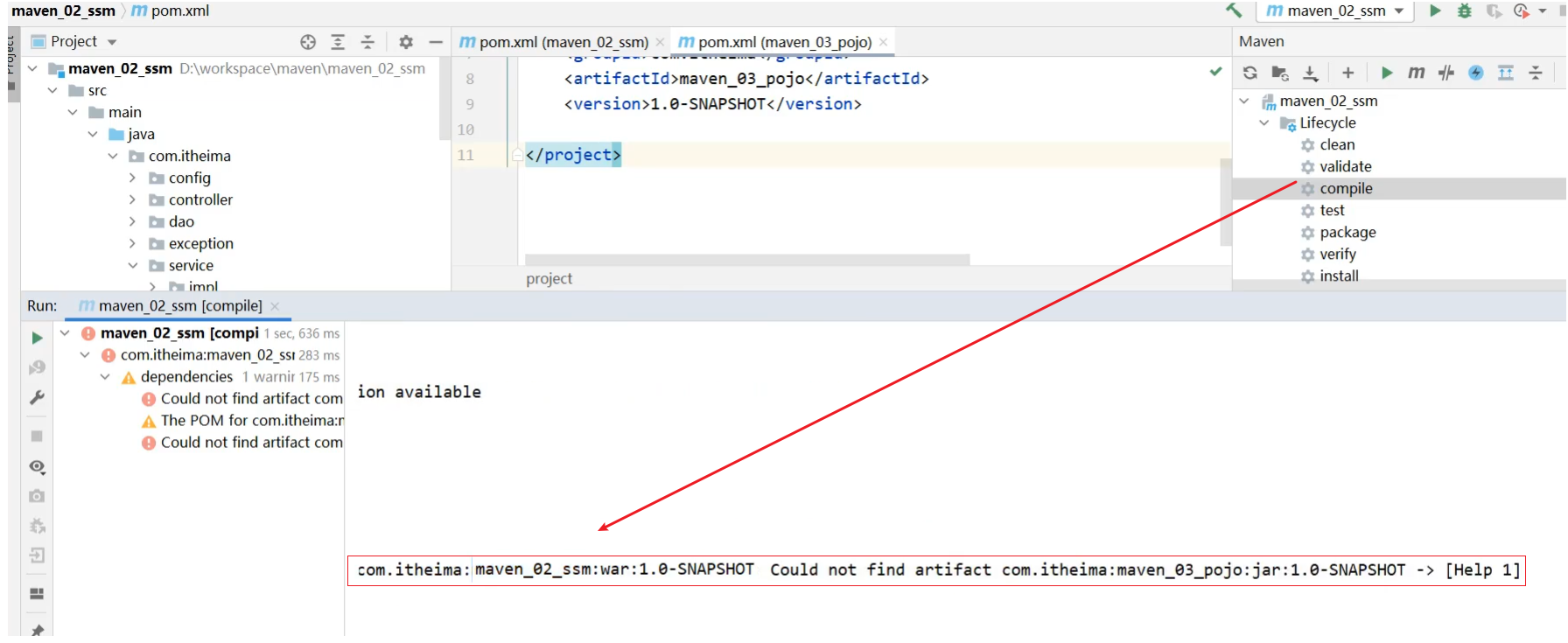
错误信息为:不能解决maven_02_ssm项目的依赖问题,找不到maven_03_pojo这个jar包。
为什么找不到呢?
原因是Maven会从本地仓库找对应的jar包,但是本地仓库又不存在该jar包所以会报错。
在IDEA中是有maven_03_pojo这个项目,所以我们只需要将maven_03_pojo项目安装到本地仓库即可。
步骤6:将项目安装本地仓库
将需要被依赖的项目maven_03_pojo,使用maven的install命令,把其安装到Maven的本地仓库中。
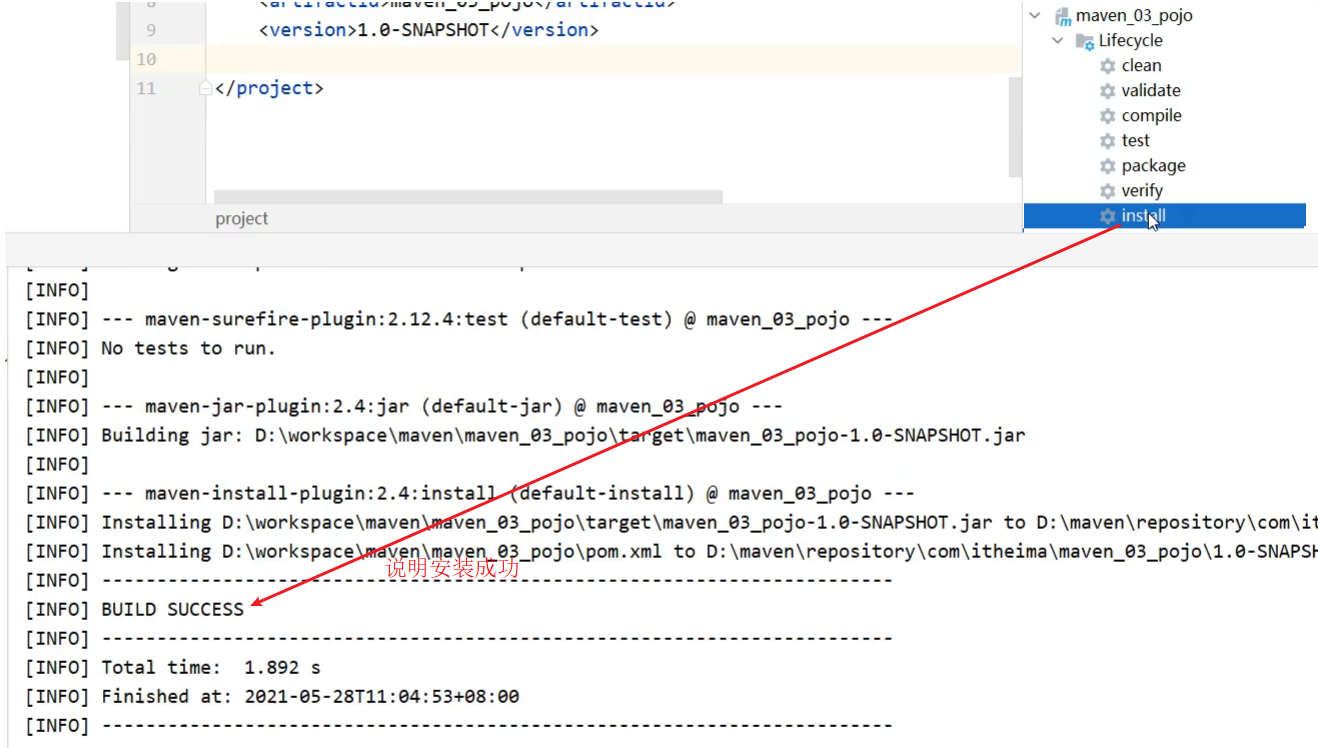
安装成功后,在对应的路径下就看到安装好的jar包
**说明:**具体安装在哪里,和你们自己电脑上Maven的本地仓库配置的位置有关。
当再次执行maven_02_ssm的compile的命令后,就已经能够成功编译。
2 依赖管理
我们现在已经能把项目拆分成一个个独立的模块,当在其他项目中想要使用独立出来的这些模块,只需要在其pom.xml使用
- 依赖传递
- 可选依赖
- 排除依赖
我们先来说说什么是依赖:
依赖指当前项目运行所需的jar,一个项目可以设置多个依赖。
格式为:
1 | <!--设置当前项目所依赖的所有jar--> |
2.1 依赖传递与冲突问题
回到我们刚才的项目案例中,打开Maven的面板,你会发现:
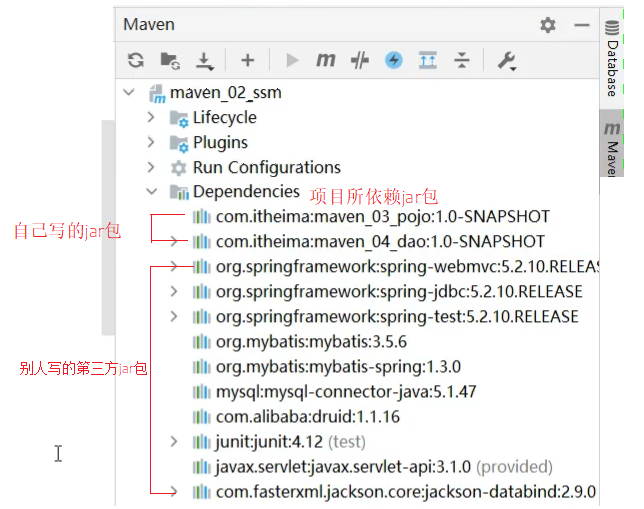
在项目所依赖的这些jar包中,有一个比较大的区别就是有的依赖前面有箭头>,有的依赖前面没有。
那么这个箭头所代表的含义是什么?
打开前面的箭头,你会发现这个jar包下面还包含有其他的jar包
你会发现有两个maven_03_pojo的依赖被加载到Dependencies中,那么maven_04_dao中的maven_03_pojo能不能使用呢?
要想验证非常简单,只需要把maven_02_ssm项目中pom.xml关于maven_03_pojo的依赖注释或删除掉

在Dependencies中移除自己所添加maven_03_pojo依赖后,打开BookServiceImpl的类,你会发现Book类依然存在,可以被正常使用
这个特性其实就是我们要讲解的==依赖传递==。
依赖是具有传递性的:
**说明:**A代表自己的项目;B,C,D,E,F,G代表的是项目所依赖的jar包;D1和D2 E1和E2代表是相同jar包的不同版本
(1) A依赖了B和C,B和C有分别依赖了其他jar包,所以在A项目中就可以使用上面所有jar包,这就是所说的依赖传递
(2) 依赖传递有直接依赖和间接依赖
- 相对于A来说,A直接依赖B和C,间接依赖了D1,E1,G,F,D2和E2
- 相对于B来说,B直接依赖了D1和E1,间接依赖了G
- 直接依赖和间接依赖是一个相对的概念
(3)因为有依赖传递的存在,就会导致jar包在依赖的过程中出现冲突问题,具体什么是冲突?Maven是如何解决冲突的?
这里所说的==依赖冲突==是指项目依赖的某一个jar包,有多个不同的版本,因而造成类包版本冲突。
情况一: 在maven_02_ssm的pom.xml中添加两个不同版本的Junit依赖:
1 | <dependencies> |
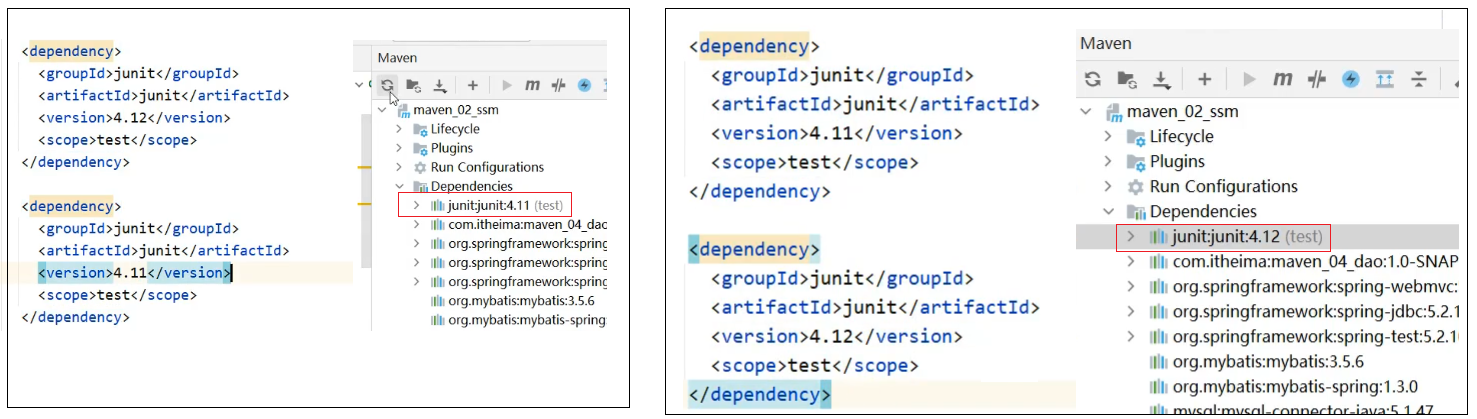
通过对比,会发现一个结论
- 特殊优先:当同级配置了相同资源的不同版本,后配置的覆盖先配置的。
情况二: 路径优先:当依赖中出现相同的资源时,层级越深,优先级越低,层级越浅,优先级越高
- A通过B间接依赖到E1
- A通过C间接依赖到E2
- A就会间接依赖到E1和E2,Maven会按照层级来选择,E1是2度,E2是3度,所以最终会选择E1
情况三: 声明优先:当资源在相同层级被依赖时,配置顺序靠前的覆盖配置顺序靠后的
- A通过B间接依赖到D1
- A通过C间接依赖到D2
- D1和D2都是两度,这个时候就不能按照层级来选择,需要按照声明来,谁先声明用谁,也就是说B在C之前声明,这个时候使用的是D1,反之则为D2
但是对应上面这些结果,大家不需要刻意去记它。因为不管Maven怎么选,最终的结果都会在Maven的Dependencies面板中展示出来,展示的是哪个版本,也就是说它选择的就是哪个版本,如:
如果想更全面的查看Maven中各个坐标的依赖关系,可以点击Maven面板中的show Dependencies
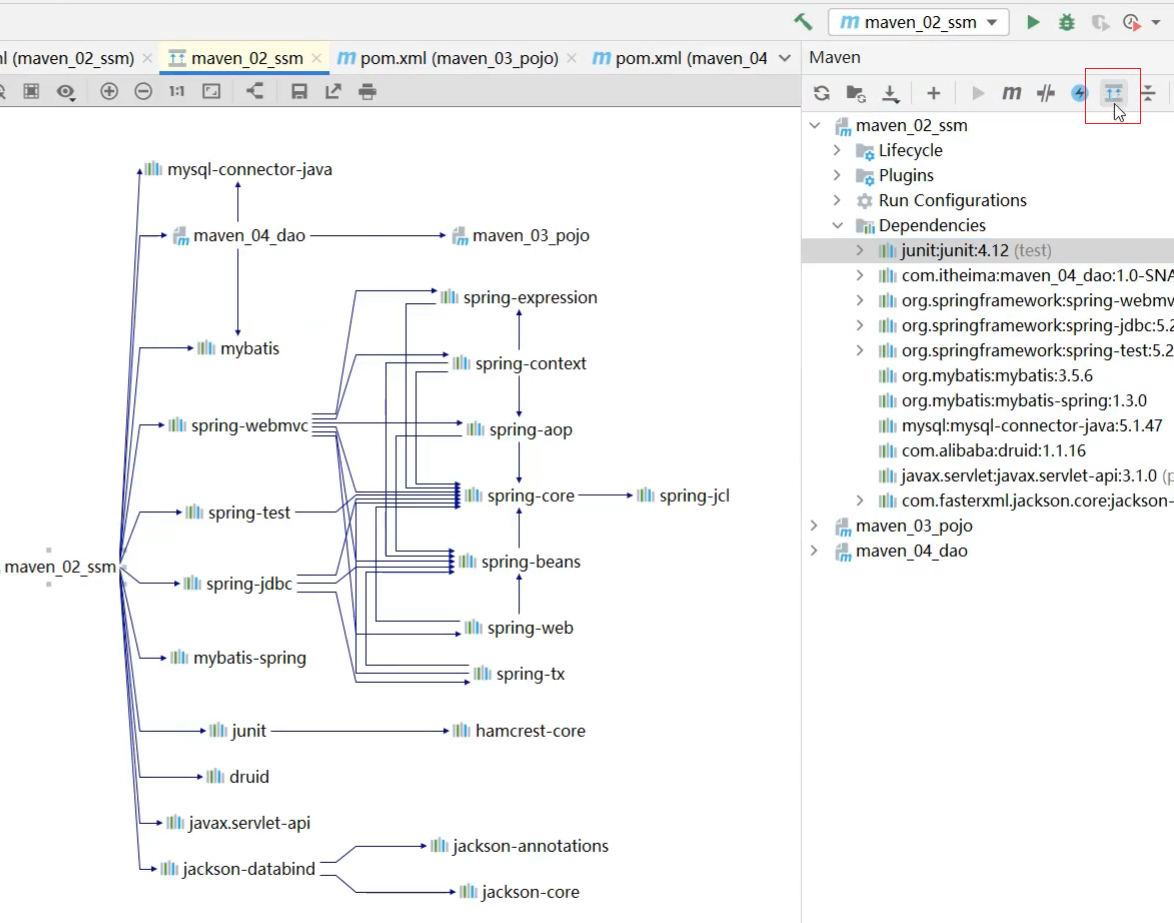
在这个视图中就能很明显的展示出jar包之间的相互依赖关系。
2.2 可选依赖和排除依赖
依赖传递介绍完以后,我们来思考一个问题,

- maven_02_ssm 依赖了 maven_04_dao
- maven_04_dao 依赖了 maven_03_pojo
- 因为现在有依赖传递,所以maven_02_ssm能够使用到maven_03_pojo的内容
- 如果说现在不想让maven_02_ssm依赖到maven_03_pojo,有哪些解决方案?
**说明:**在真实使用的过程中,maven_02_ssm中是需要用到maven_03_pojo的,我们这里只是用这个例子描述我们的需求。因为有时候,maven_04_dao出于某些因素的考虑,就是不想让别人使用自己所依赖的maven_03_pojo。
方案一:可选依赖
- 可选依赖指对外隐藏当前所依赖的资源—不透明
在maven_04_dao的pom.xml,在引入maven_03_pojo的时候,添加optional
1 | <dependency> |
此时BookServiceImpl就已经报错了,说明由于maven_04_dao将maven_03_pojo设置成可选依赖,导致maven_02_ssm无法引用到maven_03_pojo中的内容,导致Book类找不到。

方案二:排除依赖
- 排除依赖指主动断开依赖的资源,被排除的资源无需指定版本—不需要
前面我们已经通过可选依赖实现了阻断maven_03_pojo的依赖传递,对于排除依赖,则指的是已经有依赖的事实,也就是说maven_02_ssm项目中已经通过依赖传递用到了maven_03_pojo,此时我们需要做的是将其进行排除,所以接下来需要修改maven_02_ssm的pom.xml
1 | <dependency> |
这样操作后,BookServiceImpl中的Book类一样也会报错。
当然exclusions标签带s说明我们是可以依次排除多个依赖到的jar包,比如maven_04_dao中有依赖junit和mybatis,我们也可以一并将其排除。
1 | <dependency> |
介绍我这两种方式后,简单来梳理下,就是
A依赖B,B依赖C,C通过依赖传递会被A使用到,现在要想办法让A不去依赖C- 可选依赖是在B上设置
<optional>,A不知道有C的存在, - 排除依赖是在A上设置
<exclusions>,A知道有C的存在,主动将其排除掉。
3 聚合和继承
我们的项目已经从以前的单模块,变成了现在的多模块开发。项目一旦变成了多模块开发以后,就会引发一些问题,在这一节中我们主要会学习两个内容聚合和继承,用这两个知识来解决下分模块后的一些问题。
3.1 聚合
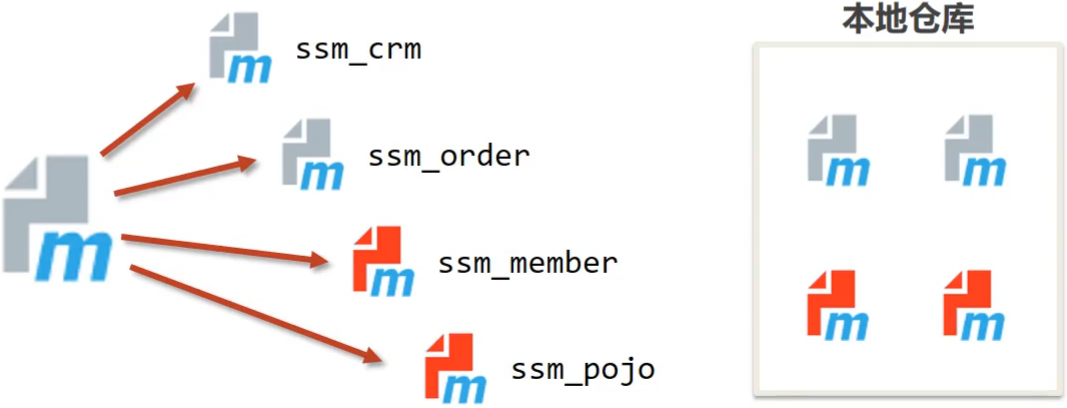
- 分模块开发后,需要将这四个项目都安装到本地仓库,目前我们只能通过项目Maven面板的
install来安装,并且需要安装四个,如果我们的项目足够多,那么一个个安装起来还是比较麻烦的 - 如果四个项目都已经安装成功,当ssm_pojo发生变化后,我们就得将ssm_pojo重新安装到maven仓库,但是为了确保我们对ssm_pojo的修改不会影响到其他项目模块,我们需要对所有的模块进行重新编译,那又需要将所有的模块再来一遍
项目少的话还好,但是如果项目多的话,一个个操作项目就容易出现漏掉或重复操作的问题,所以我们就想能不能抽取一个项目,把所有的项目管理起来,以后我们要想操作这些项目,只需要操作这一个项目,其他所有的项目都走一样的流程,这个不就很省事省力。
这就用到了我们接下来要讲解的==聚合==,
- 所谓聚合:将多个模块组织成一个整体,同时进行项目构建的过程称为聚合
- 聚合工程:通常是一个不具有业务功能的”空”工程(有且仅有一个pom文件)
- 作用:使用聚合工程可以将多个工程编组,通过对聚合工程进行构建,实现对所包含的模块进行同步构建
- 当工程中某个模块发生更新(变更)时,必须保障工程中与已更新模块关联的模块同步更新,此时可以使用聚合工程来解决批量模块同步构建的问题。
3.2 继承
我们已经完成了使用聚合工程去管理项目,聚合工程进行某一个构建操作,其他被其管理的项目也会执行相同的构建操作。那么接下来,我们再来分析下,多模块开发存在的另外一个问题,重复配置的问题,我们先来看张图:

spring-webmvc、spring-jdbc在三个项目模块中都有出现,这样就出现了重复的内容spring-test只在ssm_crm和ssm_goods中出现,而在ssm_order中没有,这里是部分重复的内容- 我们使用的spring版本目前是
5.2.10.RELEASE,假如后期要想升级spring版本,所有跟Spring相关jar包都得被修改,涉及到的项目越多,维护成本越高
面对上面的这些问题,我们就得用到接下来要学习的==继承==
- 所谓继承:描述的是两个工程间的关系,与java中的继承相似,子工程可以继承父工程中的配置信息,常见于依赖关系的继承。
- 作用:
- 简化配置
- 减少版本冲突
3.3 聚合与继承的区别
3.3.1 聚合与继承的区别
两种之间的作用:
- 聚合用于快速构建项目,对项目进行管理
- 继承用于快速配置和管理子项目中所使用jar包的版本
聚合和继承的相同点:
- 聚合与继承的pom.xml文件打包方式均为pom,可以将两种关系制作到同一个pom文件中
- 聚合与继承均属于设计型模块,并无实际的模块内容
聚合和继承的不同点:
- 聚合是在当前模块中配置关系,聚合可以感知到参与聚合的模块有哪些
- 继承是在子模块中配置关系,父模块无法感知哪些子模块继承了自己
相信到这里,大家已经能区分开什么是聚合和继承,但是有一个稍微麻烦的地方就是聚合和继承的工程构建,需要在聚合项目中手动添加modules标签,需要在所有的子项目中添加parent标签,万一写错了咋办?
4 属性
在这一章节内容中,我们将学习两个内容,分别是
- 属性
- 版本管理
属性中会继续解决分模块开发项目存在的问题,版本管理主要是认识下当前主流的版本定义方式。
4.1 属性
4.1.2 解决步骤
步骤1:父工程中定义属性
1 | <properties> |
步骤2:修改依赖的version
1 | <dependency> |
此时,我们只需要更新父工程中properties标签中所维护的jar包版本,所有子项目中的版本也就跟着更新。当然除了将spring相关版本进行维护,我们可以将其他的jar包版本也进行抽取,这样就可以对项目中所有jar包的版本进行统一维护,如:
1 | <!--定义属性--> |
5 多环境配置与应用
这一节中,我们会讲两个内容,分别是多环境开发和跳过测试
5.1 多环境开发
- 我们平常都是在自己的开发环境进行开发,
- 当开发完成后,需要把开发的功能部署到测试环境供测试人员进行测试使用,
- 等测试人员测试通过后,我们会将项目部署到生成环境上线使用。
- 这个时候就有一个问题是,不同环境的配置是不相同的,如不可能让三个环境都用一个数据库,所以就会有三个数据库的url配置,
- 我们在项目中如何配置?
- 要想实现不同环境之间的配置切换又该如何来实现呢?
maven提供配置多种环境的设定,帮助开发者在使用过程中快速切换环境。
5.2 跳过测试
前面在执行install指令的时候,Maven都会按照顺序从上往下依次执行,每次都会执行test,
对于test来说有它存在的意义,
- 可以确保每次打包或者安装的时候,程序的正确性,假如测试已经通过在我们没有修改程序的前提下再次执行打包或安装命令,由于顺序执行,测试会被再次执行,就有点耗费时间了。
- 功能开发过程中有部分模块还没有开发完毕,测试无法通过,但是想要把其中某一部分进行快速打包,此时由于测试环境失败就会导致打包失败。
遇到上面这些情况的时候,我们就想跳过测试执行下面的构建命令,具体实现方式有很多:
方式一:IDEA工具实现跳过测试
图中的按钮为Toggle 'Skip Tests' Mode,
Toggle翻译为切换的意思,也就是说在测试与不测试之间进行切换。
点击一下,出现测试画横线的图片,如下:

说明测试已经被关闭,再次点击就会恢复。
这种方式最简单,但是有点”暴力”,会把所有的测试都跳过,如果我们想更精细的控制哪些跳过哪些不跳过,就需要使用配置插件的方式。
方式二:配置插件实现跳过测试
在父工程中的pom.xml中添加测试插件配置
1 | <build> |
skipTests:如果为true,则跳过所有测试,如果为false,则不跳过测试
excludes:哪些测试类不参与测试,即排除,针对skipTests为false来设置的
includes: 哪些测试类要参与测试,即包含,针对skipTests为true来设置的
方式三:命令行跳过测试
使用Maven的命令行,mvn 指令 -D skipTests
注意事项:
- 执行的项目构建指令必须包含测试生命周期,否则无效果。例如执行compile生命周期,不经过test生命周期。
- 该命令可以不借助IDEA,直接使用cmd命令行进行跳过测试,需要注意的是cmd要在pom.xml所在目录下进行执行。
6 私服
这一节,我们主要学习的内容是:
- 私服简介
- 私服仓库分类
- 资源上传与下载
首先来说一说什么是私服?
6.1 私服简介
团队开发现状分析
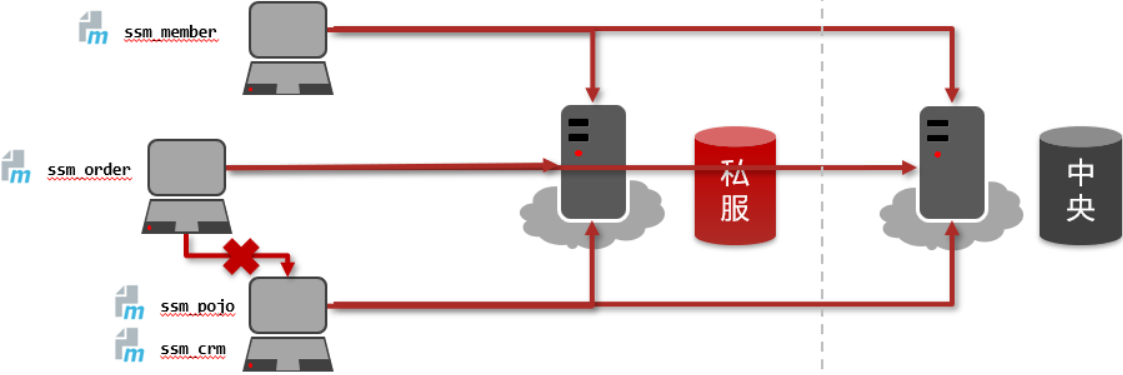
(1)张三负责ssm_crm的开发,自己写了一个ssm_pojo模块,要想使用直接将ssm_pojo安装到本地仓库即可
(2)李四负责ssm_order的开发,需要用到张三所写的ssm_pojo模块,这个时候如何将张三写的ssm_pojo模块交给李四呢?
(3)如果直接拷贝,那么团队之间的jar包管理会非常混乱而且容器出错,这个时候我们就想能不能将写好的项目上传到中央仓库,谁想用就直接联网下载即可
(4)Maven的中央仓库不允许私人上传自己的jar包,那么我们就得换种思路,自己搭建一个类似于中央仓库的东西,把自己的内容上传上去,其他人就可以从上面下载jar包使用
(5)这个类似于中央仓库的东西就是我们接下来要学习的==私服==
所以到这就有两个概念,一个是私服,一个是中央仓库
私服:公司内部搭建的用于存储Maven资源的服务器
远程仓库:Maven开发团队维护的用于存储Maven资源的服务器
所以说:
- 私服是一台独立的服务器,用于解决团队内部的资源共享与资源同步问题
搭建Maven私服的方式有很多,我们来介绍其中一种使用量比较大的实现方式:
- Nexus
- Sonatype公司的一款maven私服产品
- 下载地址:https://help.sonatype.com/repomanager3/download
6.2 私服安装
步骤1:下载解压
将资料\latest-win64.zip解压到一个空目录下。
步骤2:启动Nexus
使用cmd进入到解压目录下的nexus-3.30.1-01\bin,执行如下命令:
1 | nexus.exe /run nexus |
看到如下内容,说明启动成功。

步骤3:浏览器访问
访问地址为:
1 | http://localhost:8081 |
步骤4:首次登录重置密码
输入用户名和密码进行登录,登录成功后,出现如下页面
点击下一步,需要重新输入新密码,为了和后面的保持一致,密码修改为admin
设置是否运行匿名访问
点击完成
至此私服就已经安装成功。如果要想修改一些基础配置信息,可以使用:
- 修改基础配置信息
- 安装路径下etc目录中nexus-default.properties文件保存有nexus基础配置信息,例如默认访问端口。
- 修改服务器运行配置信息
- 安装路径下bin目录中nexus.vmoptions文件保存有nexus服务器启动对应的配置信息,例如默认占用内存空间。
6.3 私服仓库分类
私服资源操作流程分析:
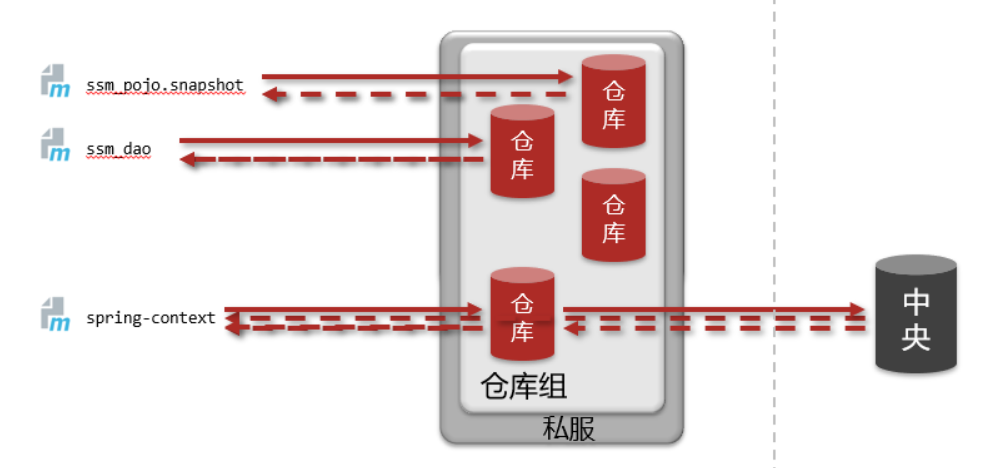
(1)在没有私服的情况下,我们自己创建的服务都是安装在Maven的本地仓库中
(2)私服中也有仓库,我们要把自己的资源上传到私服,最终也是放在私服的仓库中
(3)其他人要想使用你所上传的资源,就需要从私服的仓库中获取
(4)当我们要使用的资源不是自己写的,是远程中央仓库有的第三方jar包,这个时候就需要从远程中央仓库下载,每个开发者都去远程中央仓库下速度比较慢(中央仓库服务器在国外)
(5)私服就再准备一个仓库,用来专门存储从远程中央仓库下载的第三方jar包,第一次访问没有就会去远程中央仓库下载,下次再访问就直接走私服下载
(6)前面在介绍版本管理的时候提到过有SNAPSHOT和RELEASE,如果把这两类的都放到同一个仓库,比较混乱,所以私服就把这两个种jar包放入不同的仓库
(7)上面我们已经介绍了有三种仓库,一种是存放SNAPSHOT的,一种是存放RELEASE还有一种是存放从远程仓库下载的第三方jar包,那么我们在获取资源的时候要从哪个仓库种获取呢?
(8)为了方便获取,我们将所有的仓库编成一个组,我们只需要访问仓库组去获取资源。
所有私服仓库总共分为三大类:
宿主仓库hosted
- 保存无法从中央仓库获取的资源
- 自主研发
- 第三方非开源项目,比如Oracle,因为是付费产品,所以中央仓库没有
代理仓库proxy
- 代理远程仓库,通过nexus访问其他公共仓库,例如中央仓库
仓库组group
- 将若干个仓库组成一个群组,简化配置
- 仓库组不能保存资源,属于设计型仓库
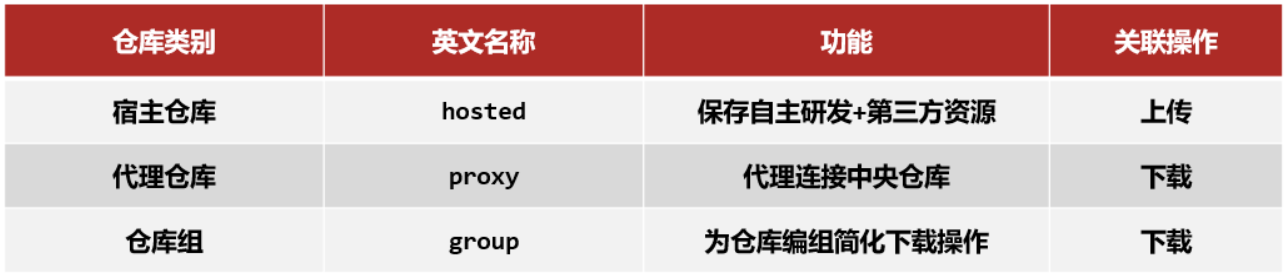
6.4 本地仓库访问私服配置
- 我们通过IDEA将开发的模块上传到私服,中间是要经过本地Maven的
- 本地Maven需要知道私服的访问地址以及私服访问的用户名和密码
- 私服中的仓库很多,Maven最终要把资源上传到哪个仓库?
- Maven下载的时候,又需要携带用户名和密码到私服上找对应的仓库组进行下载,然后再给IDEA
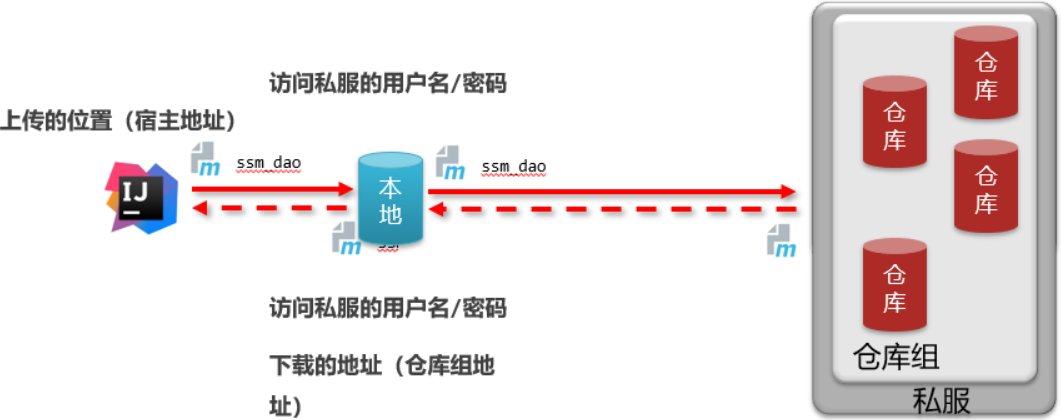
上面所说的这些内容,我们需要在本地Maven的配置文件settings.xml中进行配置。
步骤1:私服上配置仓库
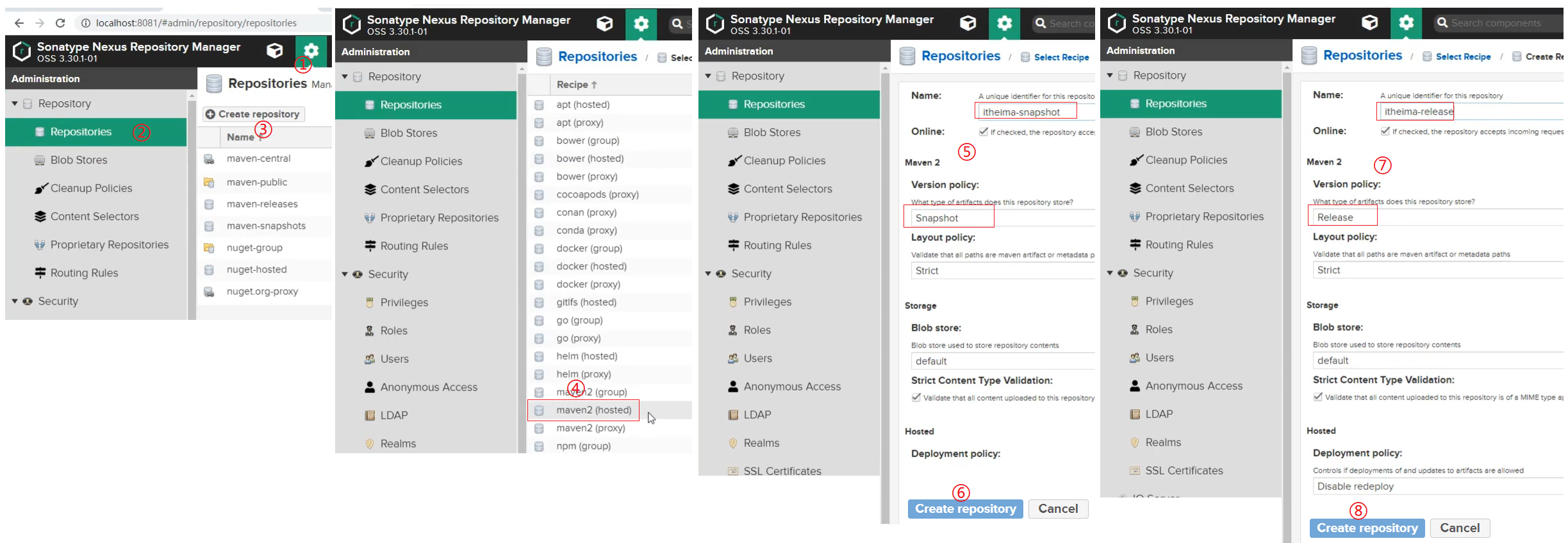
说明:
第5,6步骤是创建itheima-snapshot仓库
第7,8步骤是创建itheima-release仓库
步骤2:配置本地Maven对私服的访问权限
1 | <servers> |
步骤3:配置私服的访问路径
1 | <mirrors> |
为了避免阿里云Maven私服地址的影响,建议先将之前配置的阿里云Maven私服镜像地址注释掉,等练习完后,再将其恢复。
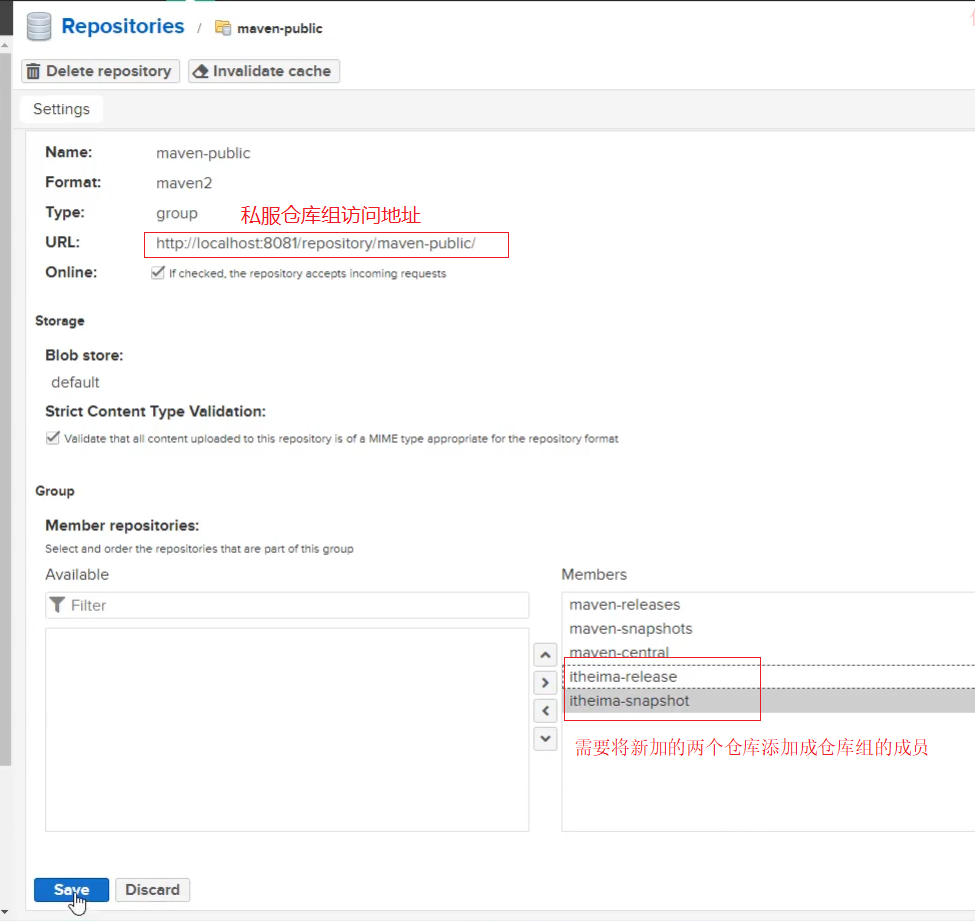
至此本地仓库就能与私服进行交互了。
6.5 私服资源上传与下载
本地仓库与私服已经建立了连接,接下来我们就需要往私服上上传资源和下载资源,具体的实现步骤为:
步骤1:配置工程上传私服的具体位置
1 | <!--配置当前工程保存在私服中的具体位置--> |
步骤2:发布资源到私服
或者执行Maven命令
1 | mvn deploy |
注意:
要发布的项目都需要配置distributionManagement标签,要么在自己的pom.xml中配置,要么在其父项目中配置,然后子项目中继承父项目即可。
发布成功,在私服中就能看到:
现在发布是在itheima-snapshot仓库中,如果想发布到itheima-release仓库中就需要将项目pom.xml中的version修改成RELEASE即可。
如果想删除已经上传的资源,可以在界面上进行删除操作:
如果私服中没有对应的jar,会去中央仓库下载,速度很慢。可以配置让私服去阿里云中下载依赖。
至此私服的搭建就已经完成,相对来说有点麻烦,但是步骤都比较固定,后期大家如果需要的话,就可以参考上面的步骤一步步完成搭建即可。
SpringBoot
SpringBoot 是由 Pivotal 团队提供的全新框架,其设计目的是用来==简化== Spring 应用的==初始搭建==以及==开发过程==。
使用了 Spring 框架后已经简化了我们的开发。而 SpringBoot 又是对 Spring 开发进行简化的,可想而知 SpringBoot 使用的简单及广泛性。既然 SpringBoot 是用来简化 Spring 开发的,那我们就先回顾一下,以 SpringMVC 开发为例:
- 创建工程,并在
pom.xml配置文件中配置所依赖的坐标

编写
web3.0的配置类作为
web程序,web3.0的配置类不能缺少,而这个配置类还是比较麻烦的,代码如下

- 编写
SpringMVC的配置类

做到这只是将工程的架子搭起来。要想被外界访问,最起码还需要提供一个 Controller 类,在该类中提供一个方法。
- 编写
Controller类

从上面的 SpringMVC 程序开发可以看到,前三步都是在搭建环境,而且这三步基本都是固定的。SpringBoot 就是对这三步进行简化了。接下来我们通过一个入门案例来体现 SpingBoot 简化 Spring 开发。
1.1 SpringBoot快速入门
1.1.1 开发步骤
SpringBoot 开发起来特别简单,分为如下几步:
- 创建新模块,选择Spring初始化,并配置模块相关基础信息
- 选择当前模块需要使用的技术集
- 开发控制器类
- 运行自动生成的Application类
知道了 SpringBoot 的开发步骤后,接下来我们进行具体的操作
1.1.1.1 创建新模块
- 点击
+选择New Module创建新模块
选择
Spring Initializr,用来创建SpringBoot工程以前我们选择的是
Maven,今天选择Spring Initializr来快速构建SpringBoot工程。而在Module SDK这一项选择我们安装的JDK版本。
对
SpringBoot工程进行相关的设置我们使用这种方式构建的
SpringBoot工程其实也是Maven工程,而该方式只是一种快速构建的方式而已。
==注意:打包方式这里需要设置为
Jar==选中
Web,然后勾选Spring Web由于我们需要开发一个
web程序,使用到了SpringMVC技术,所以按照下图红框进行勾选
- 下图界面不需要任何修改,直接点击
Finish完成SpringBoot工程的构建
经过以上步骤后就创建了如下结构的模块,它会帮我们自动生成一个 Application 类,而该类一会再启动服务器时会用到
==注意:==
在创建好的工程中不需要创建配置类
创建好的项目会自动生成其他的一些文件,而这些文件目前对我们来说没有任何作用,所以可以将这些文件删除。
可以删除的目录和文件如下:
.mvn.gitignoreHELP.mdmvnwmvnw.cmd
1.1.1.2 创建 Controller
在 com.itheima.controller 包下创建 BookController ,代码如下:
1 |
|
1.1.1.3 启动服务器
运行 SpringBoot 工程不需要使用本地的 Tomcat 和 插件,只运行项目 com.itheima 包下的 Application 类,我们就可以在控制台看出如下信息
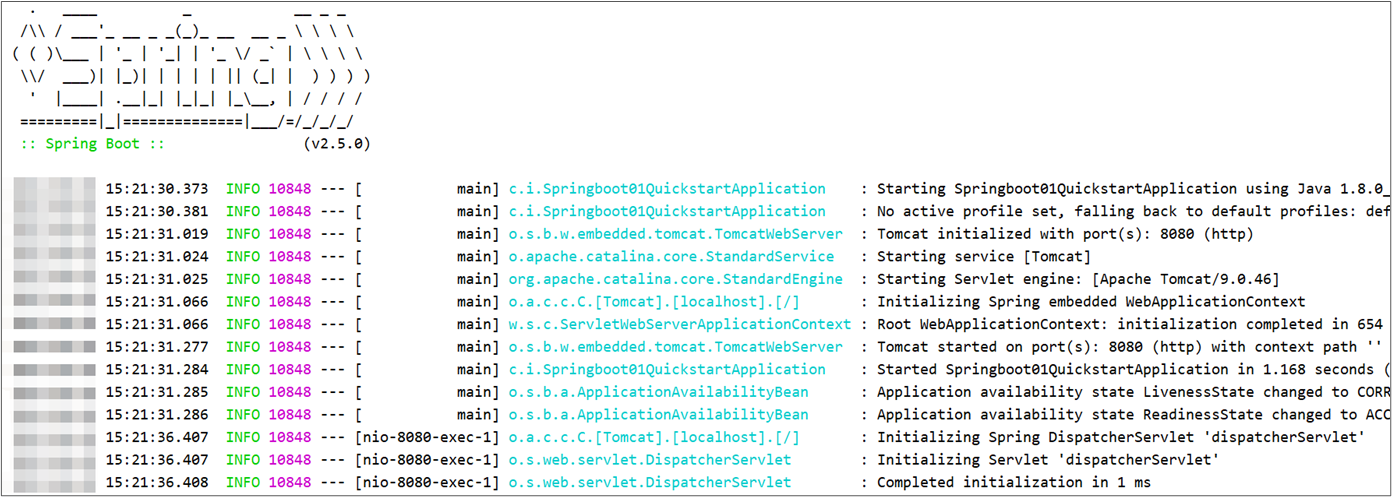
1.1.1.4 进行测试
使用 Postman 工具来测试我们的程序
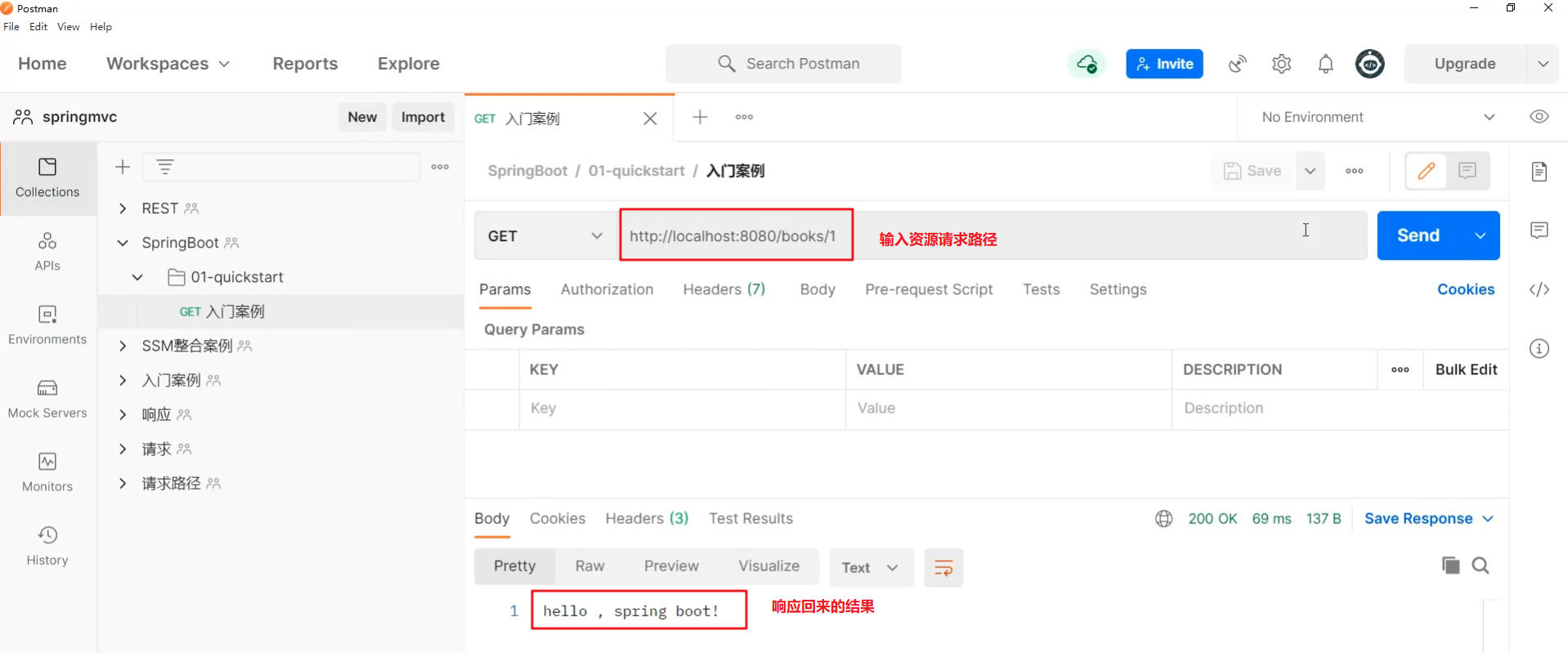
通过上面的入门案例我们可以看到使用 SpringBoot 进行开发,使整个开发变得很简单,那它是如何做到的呢?
要研究这个问题,我们需要看看 Application 类和 pom.xml 都书写了什么。先看看 Applicaion 类,该类内容如下:
1 |
|
这个类中的东西很简单,就在类上添加了一个 @SpringBootApplication 注解,而在主方法中就一行代码。我们在启动服务器时就是执行的该类中的主方法。
再看看 pom.xml 配置文件中的内容
1 |
|
我们代码之所以能简化,就是因为指定的父工程和 Spring Web 依赖实现的。
1.1.4 SpringBoot工程快速启动
1.1.4.1 问题导入

以后我们和前端开发人员协同开发,而前端开发人员需要测试前端程序就需要后端开启服务器,这就受制于后端开发人员。为了摆脱这个受制,前端开发人员尝试着在自己电脑上安装 Tomcat 和 Idea ,在自己电脑上启动后端程序,这显然不现实。
我们后端可以将 SpringBoot 工程打成 jar 包,该 jar 包运行不依赖于 Tomcat 和 Idea 这些工具也可以正常运行,只是这个 jar 包在运行过程中连接和我们自己程序相同的 Mysql 数据库即可。这样就可以解决这个问题,如下图

那现在问题是如何打包呢?
1.1.4.2 打包
由于我们在构建 SpringBoot 工程时已经在 pom.xml 中配置了如下插件
1 | <plugin> |
所以我们只需要使用 Maven 的 package 指令打包就会在 target 目录下生成对应的 Jar 包。
==注意:该插件必须配置,不然打好的
jar包也是有问题的。==
1.1.4.3 启动
进入 jar 包所在位置,在 命令提示符 中输入如下命令
1 | jar -jar springboot_01_quickstart-0.0.1-SNAPSHOT.jar |
执行上述命令就可以看到 SpringBoot 运行的日志信息
2.1 配置文件格式
我们现在启动服务器默认的端口号是 8080,访问路径可以书写为
1 | http://localhost:8080/books/1 |
在线上环境我们还是希望将端口号改为 80,这样在访问的时候就可以不写端口号了,如下
1 | http://localhost/books/1 |
而 SpringBoot 程序如何修改呢?SpringBoot 提供了多种属性配置方式
application.properties1
server.port=80
application.yml1
2server:
port: 81application.yaml1
2server:
port: 82
==注意:
SpringBoot程序的配置文件名必须是application,只是后缀名不同而已。==
2.1.1 三种配合文件的优先级
在三种配合文件中分别配置不同的端口号,启动服务查看绑定的端口号。用这种方式就可以看到哪个配置文件的优先级更高一些
application.properties 文件内容如下:
1 | =80 |
application.yml 文件内容如下:
1 | server: |
application.yaml 文件内容如下:
1 | server: |
启动服务,在控制台可以看到使用的端口号是 80。说明 application.properties 的优先级最高
注释掉 application.properties 配置文件内容。再次启动服务,在控制台可以看到使用的端口号是 81,说明 application.yml 配置文件为第二优先级。
从上述的验证结果可以确定三种配置文件的优先级是:
==application.properties > application.yml > application.yaml==
==注意:==
SpringBoot核心配置文件名为application
SpringBoot内置属性过多,且所有属性集中在一起修改,在使用时,通过提示键+关键字修改属性例如要设置日志的级别时,可以在配置文件中书写
logging,就会提示出来。配置内容如下
2
3
level:
root: info
2.2 yaml格式
上面讲了三种不同类型的配置文件,而 properties 类型的配合文件之前我们学习过,接下来我们重点学习 yaml 类型的配置文件。
YAML(YAML Ain’t Markup Language),一种数据序列化格式。这种格式的配置文件在近些年已经占有主导地位,那么这种配置文件和前期使用的配置文件是有一些优势的,我们先看之前使用的配置文件。
最开始我们使用的是 xml ,格式如下:
1 | <enterprise> |
而 properties 类型的配置文件如下
1 | =itcast |
yaml 类型的配置文件内容如下
1 | enterprise: |
优点:
容易阅读
yaml类型的配置文件比xml类型的配置文件更容易阅读,结构更加清晰容易与脚本语言交互
以数据为核心,重数据轻格式
yaml更注重数据,而xml更注重格式
YAML 文件扩展名:
.yml(主流).yaml
上面两种后缀名都可以,以后使用更多的还是 yml 的。
2.2.1 语法规则
大小写敏感
属性层级关系使用多行描述,每行结尾使用冒号结束
使用缩进表示层级关系,同层级左侧对齐,只允许使用空格(不允许使用Tab键)
空格的个数并不重要,只要保证同层级的左侧对齐即可。
属性值前面添加空格(属性名与属性值之间使用冒号+空格作为分隔)
# 表示注释
==核心规则:数据前面要加空格与冒号隔开==
数组数据在数据书写位置的下方使用减号作为数据开始符号,每行书写一个数据,减号与数据间空格分隔,例如
1 | enterprise: |
2.2.2 读取配置数据
2.2.2.1 使用 @Value注解
使用 @Value("表达式") 注解可以从配合文件中读取数据,注解中用于读取属性名引用方式是:${一级属性名.二级属性名……}
我们可以在 BookController 中使用 @Value 注解读取配合文件数据,如下
1 |
|
2.2.2.2 Environment对象
上面方式读取到的数据特别零散,SpringBoot 还可以使用 @Autowired 注解注入 Environment 对象的方式读取数据。这种方式 SpringBoot 会将配置文件中所有的数据封装到 Environment 对象中,如果需要使用哪个数据只需要通过调用 Environment 对象的 getProperty(String name) 方法获取。具体代码如下:
1 |
|
==注意:这种方式,框架内容大量数据,而在开发中我们很少使用。==
2.2.2.3 自定义对象
SpringBoot 还提供了将配置文件中的数据封装到我们自定义的实体类对象中的方式。具体操作如下:
将实体类
bean的创建交给Spring管理。在类上添加
@Component注解使用
@ConfigurationProperties注解表示加载配置文件在该注解中也可以使用
prefix属性指定只加载指定前缀的数据在
BookController中进行注入
具体代码如下:
Enterprise 实体类内容如下:
1 |
|
BookController 内容如下:
1 |
|
==注意:==
使用第三种方式,在实体类上有如下警告提示
这个警告提示解决是在 pom.xml 中添加如下依赖即可
1 | <dependency> |
2.2.3 yaml文件
在 application.yml 中使用 --- 来分割不同的配置,内容如下
1 | #开发 |
上面配置中 spring.profiles 是用来给不同的配置起名字的。而如何告知 SpringBoot 使用哪段配置呢?可以使用如下配置来启用都一段配置
1 | #设置启用的环境 |
综上所述,application.yml 配置文件内容如下
1 | #设置启用的环境 |
==注意:==
在上面配置中给不同配置起名字的 spring.profiles 配置项已经过时。最新用来起名字的配置项是
1 | #开发 |
2.2.4 properties文件
properties 类型的配置文件配置多环境需要定义不同的配置文件
application-dev.properties是开发环境的配置文件。我们在该文件中配置端口号为801
=80
application-test.properties是测试环境的配置文件。我们在该文件中配置端口号为811
=81
application-pro.properties是生产环境的配置文件。我们在该文件中配置端口号为821
=82
SpringBoot 只会默认加载名为 application.properties 的配置文件,所以需要在 application.properties 配置文件中设置启用哪个配置文件,配置如下:
1 | =pro |
2.2.5 命令行启动参数设置
使用 SpringBoot 开发的程序以后都是打成 jar 包,通过 java -jar xxx.jar 的方式启动服务的。那么就存在一个问题,如何切换环境呢?因为配置文件打到的jar包中了。
我们知道 jar 包其实就是一个压缩包,可以解压缩,然后修改配置,最后再打成jar包就可以了。这种方式显然有点麻烦,而 SpringBoot 提供了在运行 jar 时设置开启指定的环境的方式,如下
1 | java –jar xxx.jar –-spring.profiles.active=test |
那么这种方式能不能临时修改端口号呢?也是可以的,可以通过如下方式
1 | java –jar xxx.jar –-server.port=88 |
当然也可以同时设置多个配置,比如即指定启用哪个环境配置,又临时指定端口,如下
1 | java –jar springboot.jar –-server.port=88 –-spring.profiles.active=test |
大家进行测试后就会发现命令行设置的端口号优先级高(也就是使用的是命令行设置的端口号),配置的优先级其实 SpringBoot 官网已经进行了说明,参见 :
1 | https://docs.spring.io/spring-boot/docs/current/reference/html/spring-boot-features.html#boot-features-external-config |
进入上面网站后会看到如下页面

如果使用了多种方式配合同一个配置项,优先级高的生效。
2.3 配置文件分类

有这样的场景,我们开发完毕后需要测试人员进行测试,由于测试环境和开发环境的很多配置都不相同,所以测试人员在运行我们的工程时需要临时修改很多配置,如下
1 | java –jar springboot.jar –-spring.profiles.active=test --server.port=85 --server.servlet.context-path=/heima --server.tomcat.connection-timeout=-1 …… …… …… …… …… |
针对这种情况,SpringBoot 定义了配置文件不同的放置的位置;而放在不同位置的优先级时不同的。
SpringBoot 中4级配置文件放置位置:
- 1级:classpath:application.yml
- 2级:classpath:config/application.yml
- 3级:file :application.yml
- 4级:file :config/application.yml
==说明:==级别越高优先级越高
3.0 SpringBoot整合junit
回顾 Spring 整合 junit
1 |
|
使用 @RunWith 注解指定运行器,使用 @ContextConfiguration 注解来指定配置类或者配置文件。而 SpringBoot 整合 junit 特别简单,分为以下三步完成
- 在测试类上添加
SpringBootTest注解 - 使用
@Autowired注入要测试的资源 - 定义测试方法进行测试
3.1 环境准备
创建一个名为 springboot_07_test 的 SpringBoot 工程,工程目录结构如下
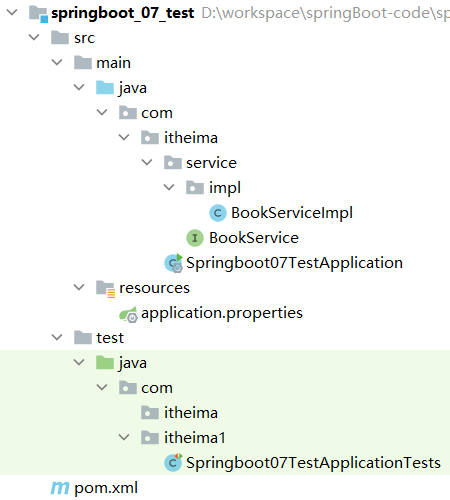
在 com.itheima.service 下创建 BookService 接口,内容如下
1 | public interface BookService { |
在 com.itheima.service.impl 包写创建一个 BookServiceImpl 类,使其实现 BookService 接口,内容如下
1 |
|
3.2 编写测试类
在 test/java 下创建 com.itheima 包,在该包下创建测试类,将 BookService 注入到该测试类中
1 |
|
==注意:==这里的引导类所在包必须是测试类所在包及其子包。
例如:
- 引导类所在包是
com.itheima- 测试类所在包是
com.itheima如果不满足这个要求的话,就需要在使用
@SpringBootTest注解时,使用classes属性指定引导类的字节码对象。如@SpringBootTest(classes = Springboot07TestApplication.class)
MyBatisPlus
今日目标
基于MyBatisPlus完成标准Dao的增删改查功能
掌握MyBatisPlus中的分页及条件查询构建
掌握主键ID的生成策略
了解MyBatisPlus的代码生成器
1.0 MyBatisPlus入门案例与简介
这一节我们来学习下MyBatisPlus的入门案例与简介,这个和其他课程都不太一样,其他的课程都是先介绍概念,然后再写入门案例。而对于MyBatisPlus的学习,我们将顺序做了调整,主要的原因MyBatisPlus主要是对MyBatis的简化,所有我们先体会下它简化在哪,然后再学习它是什么,以及它帮我们都做哪些事。
1.1 入门案例
MybatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工具,旨在简化开发、提供效率。
开发方式
- 基于MyBatis使用MyBatisPlus
- 基于Spring使用MyBatisPlus
- ==基于SpringBoot使用MyBatisPlus==
SpringBoot刚刚我们学习完成,它能快速构建Spring开发环境用以整合其他技术,使用起来是非常简单,对于MP的学习,我们也基于SpringBoot来构建学习。
学习之前,我们先来回顾下,SpringBoot整合Mybatis的开发过程:
创建SpringBoot工程
勾选配置使用的技术,能够实现自动添加起步依赖包
设置dataSource相关属性(JDBC参数)
定义数据层接口映射配置

我们可以参考着上面的这个实现步骤把SpringBoot整合MyBatisPlus来快速实现下,具体的实现步骤为:
步骤1:创建数据库及表
1 | create database if not exists mybatisplus_db character set utf8; |
步骤2:创建SpringBoot工程
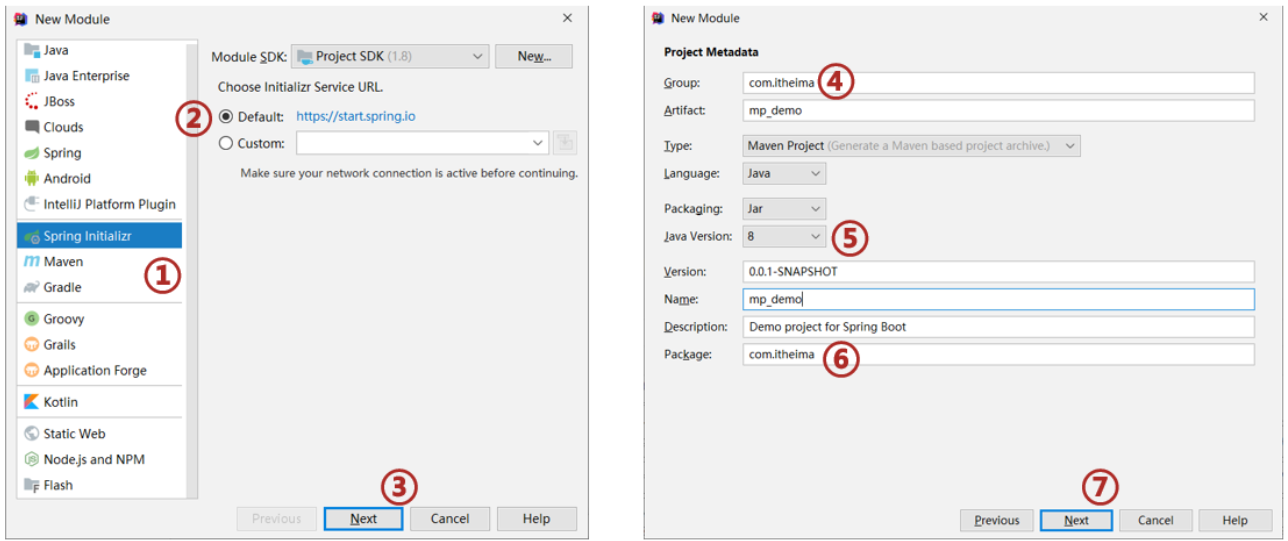
步骤3:勾选配置使用技术
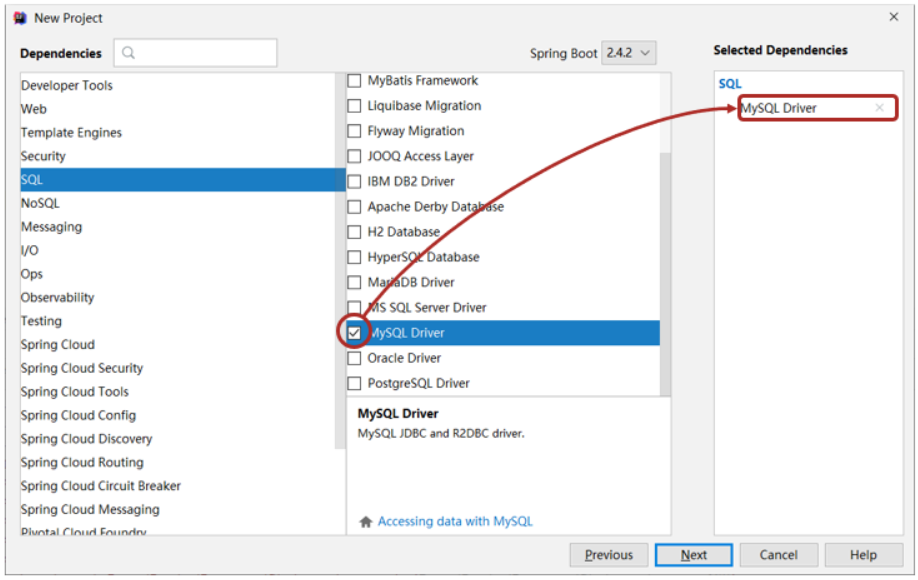
说明:
- 由于MP并未被收录到idea的系统内置配置,无法直接选择加入,需要手动在pom.xml中配置添加
步骤4:pom.xml补全依赖
1 | <dependency> |
说明:
druid数据源可以加也可以不加,SpringBoot有内置的数据源,可以配置成使用Druid数据源
从MP的依赖关系可以看出,通过依赖传递已经将MyBatis与MyBatis整合Spring的jar包导入,我们不需要额外在添加MyBatis的相关jar包

步骤5:添加MP的相关配置信息
resources默认生成的是properties配置文件,可以将其替换成yml文件,并在文件中配置数据库连接的相关信息:application.yml
1 | spring: |
说明:==serverTimezone是用来设置时区,UTC是标准时区,和咱们的时间差8小时,所以可以将其修改为Asia/Shanghai==
步骤6:根据数据库表创建实体类
1 | public class User { |
步骤7:创建Dao接口
1 |
|
步骤8:编写引导类
1 |
|
**说明:**Dao接口要想被容器扫描到,有两种解决方案:
- 方案一:在Dao接口上添加
@Mapper注解,并且确保Dao处在引导类所在包或其子包中- 该方案的缺点是需要在每一Dao接口中添加注解
- 方案二:在引导类上添加
@MapperScan注解,其属性为所要扫描的Dao所在包- 该方案的好处是只需要写一次,则指定包下的所有Dao接口都能被扫描到,
@Mapper就可以不写。
- 该方案的好处是只需要写一次,则指定包下的所有Dao接口都能被扫描到,
步骤9:编写测试类
1 |
|
说明:
userDao注入的时候下面有红线提示的原因是什么?
UserDao是一个接口,不能实例化对象
只有在服务器启动IOC容器初始化后,由框架创建DAO接口的代理对象来注入
现在服务器并未启动,所以代理对象也未创建,IDEA查找不到对应的对象注入,所以提示报红
一旦服务启动,就能注入其代理对象,所以该错误提示不影响正常运行。
查看运行结果:

跟之前整合MyBatis相比,你会发现我们不需要在DAO接口中编写方法和SQL语句了,只需要继承BaseMapper接口即可。整体来说简化很多。
1.2 MybatisPlus简介
MyBatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工具,旨在==简化开发、提高效率==
通过刚才的案例,相信大家能够体会简化开发和提高效率这两个方面的优点。
MyBatisPlus的官网为:https://mp.baomidou.com/
说明:

现在的页面中,这一行已经被删除,现在再去访问https://mybatis.plus会发现访问不到,这个就有很多可能性供我们猜想了,所以大家使用baomidou的网址进行访问即可。
官方文档中有一张很多小伙伴比较熟悉的图片:

从这张图中我们可以看出MP旨在成为MyBatis的最好搭档,而不是替换MyBatis,所以可以理解为MP是MyBatis的一套增强工具,它是在MyBatis的基础上进行开发的,我们虽然使用MP但是底层依然是MyBatis的东西,也就是说我们也可以在MP中写MyBatis的内容。
对于MP的学习,大家可以参考着官方文档来进行学习,里面都有详细的代码案例。
MP的特性:
- 无侵入:只做增强不做改变,不会对现有工程产生影响
- 强大的 CRUD 操作:内置通用 Mapper,少量配置即可实现单表CRUD 操作
- 支持 Lambda:编写查询条件无需担心字段写错
- 支持主键自动生成
- 内置分页插件
- ……
2.0 标准数据层开发
在这一节中我们重点学习的是数据层标准的CRUD(增删改查)的实现与分页功能。代码比较多,我们一个个来学习。
2.1 标准CRUD使用
对于标准的CRUD功能都有哪些以及MP都提供了哪些方法可以使用呢?
我们先来看张图:

对于这张图的方法,我们挨个来演示下:
首先说下,案例中的环境就是咱们入门案例的内容,第一个先来完成新增功能
2.2 新增
在进行新增之前,我们可以分析下新增的方法:
1 | int insert (T t) |
T:泛型,新增用来保存新增数据
int:返回值,新增成功后返回1,没有新增成功返回的是0
在测试类中进行新增操作:
1 |
|
执行测试后,数据库表中就会添加一条数据。
但是数据中的主键ID,有点长,那这个主键ID是如何来的?我们更想要的是主键自增,应该是5才对,这个是我们后面要学习的主键ID生成策略,这块的这个问题,我们暂时先放放。
2.3 删除
在进行删除之前,我们可以分析下删除的方法:
1 | int deleteById (Serializable id) |
Serializable:参数类型
思考:参数类型为什么是一个序列化类?
从这张图可以看出,
- String和Number是Serializable的子类,
- Number又是Float,Double,Integer等类的父类,
- 能作为主键的数据类型都已经是Serializable的子类,
- MP使用Serializable作为参数类型,就好比我们可以用Object接收任何数据类型一样。
int:返回值类型,数据删除成功返回1,未删除数据返回0。
在测试类中进行新增操作:
1 |
|
2.4 修改
在进行修改之前,我们可以分析下修改的方法:
1 | int updateById(T t); |
T:泛型,需要修改的数据内容,注意因为是根据ID进行修改,所以传入的对象中需要有ID属性值
int:返回值,修改成功后返回1,未修改数据返回0
在测试类中进行新增操作:
1 |
|
**说明:**修改的时候,只修改实体对象中有值的字段。
2.5 根据ID查询
在进行根据ID查询之前,我们可以分析下根据ID查询的方法:
1 | T selectById (Serializable id) |
- Serializable:参数类型,主键ID的值
- T:根据ID查询只会返回一条数据
在测试类中进行新增操作:
1 |
|
2.6 查询所有
在进行查询所有之前,我们可以分析下查询所有的方法:
1 | List<T> selectList(Wrapper<T> queryWrapper) |
- Wrapper:用来构建条件查询的条件,目前我们没有可直接传为Null
- List
:因为查询的是所有,所以返回的数据是一个集合
在测试类中进行新增操作:
1 |
|
我们所调用的方法都是来自于DAO接口继承的BaseMapper类中。里面的方法有很多,我们后面会慢慢去学习里面的内容。
2.7 Lombok
代码写到这,我们会发现DAO接口类的编写现在变成最简单的了,里面什么都不用写。反过来看看模型类的编写都需要哪些内容:
- 私有属性
- setter…getter…方法
- toString方法
- 构造函数
虽然这些内容不难,同时也都是通过IDEA工具生成的,但是过程还是必须得走一遍,那么对于模型类的编写有没有什么优化方法?就是我们接下来要学习的Lombok。
概念
- Lombok,一个Java类库,提供了一组注解,简化POJO实体类开发。
使用步骤
步骤1:添加lombok依赖
1 | <dependency> |
注意:版本可以不用写,因为SpringBoot中已经管理了lombok的版本。
步骤2:安装Lombok的插件
==新版本IDEA已经内置了该插件,如果删除setter和getter方法程序有报红,则需要安装插件==
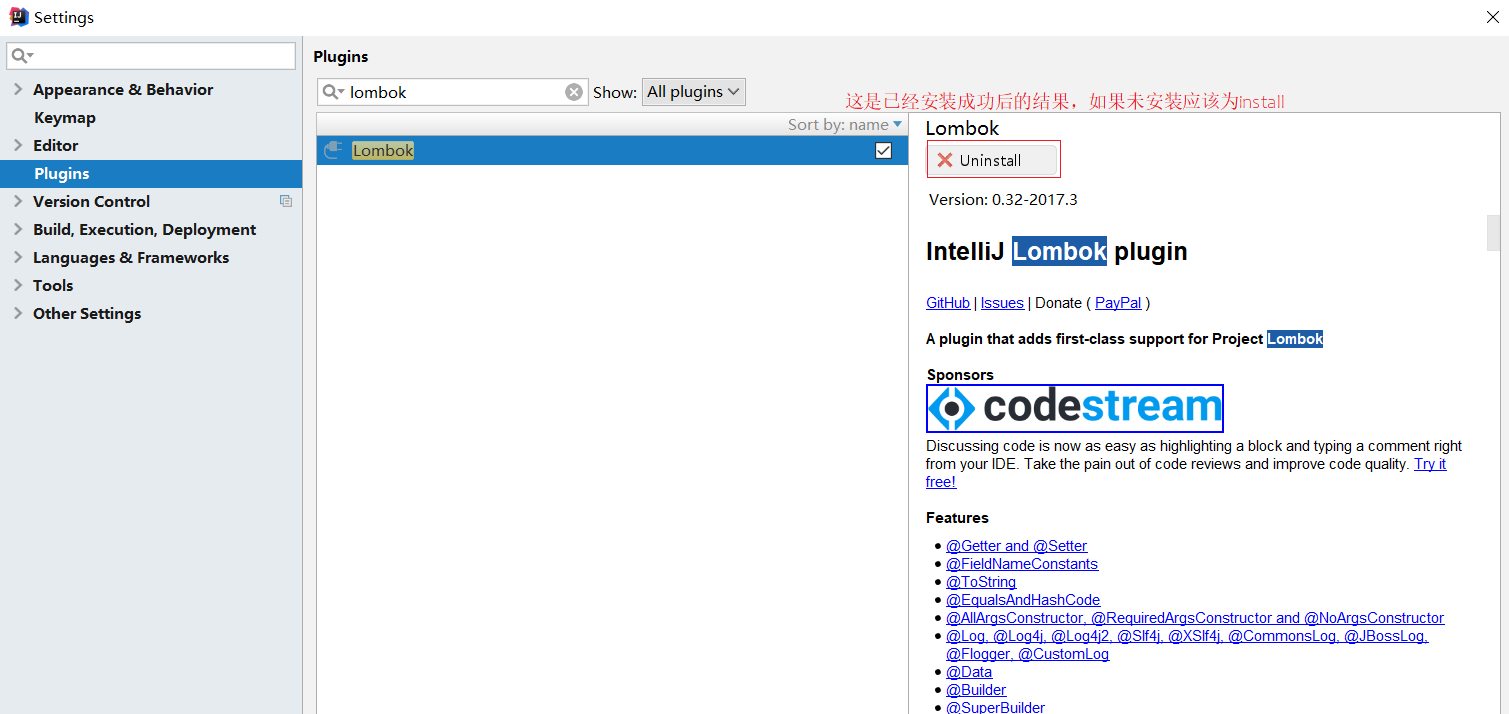
如果在IDEA中找不到lombok插件,可以访问如下网站
https://plugins.jetbrains.com/plugin/6317-lombok/versions
根据自己IDEA的版本下载对应的lombok插件,下载成功后,在IDEA中采用离线安装的方式进行安装。
步骤3:模型类上添加注解
Lombok常见的注解有:
- @Setter:为模型类的属性提供setter方法
- @Getter:为模型类的属性提供getter方法
- @ToString:为模型类的属性提供toString方法
- @EqualsAndHashCode:为模型类的属性提供equals和hashcode方法
- ==@Data:是个组合注解,包含上面的注解的功能==
- ==@NoArgsConstructor:提供一个无参构造函数==
- ==@AllArgsConstructor:提供一个包含所有参数的构造函数==
Lombok的注解还有很多,上面标红的三个是比较常用的,其他的大家后期用到了,再去补充学习。
1 |
|
说明:
Lombok只是简化模型类的编写,我们之前的方法也能用,比如有人会问:我如果只想要有name和password的构造函数,该如何编写?
1 |
|
这种方式是被允许的。
2.8 分页功能
基础的增删改查就已经学习完了,刚才我们在分析基础开发的时候,有一个分页功能还没有实现,在MP中如何实现分页功能,就是咱们接下来要学习的内容。
分页查询使用的方法是:
1 | IPage<T> selectPage(IPage<T> page, Wrapper<T> queryWrapper) |
- IPage:用来构建分页查询条件
- Wrapper:用来构建条件查询的条件,目前我们没有可直接传为Null
- IPage:返回值,你会发现构建分页条件和方法的返回值都是IPage
IPage是一个接口,我们需要找到它的实现类来构建它,具体的实现类,可以进入到IPage类中按ctrl+h,会找到其有一个实现类为Page。
步骤1:调用方法传入参数获取返回值
1 |
|
步骤2:设置分页拦截器
这个拦截器MP已经为我们提供好了,我们只需要将其配置成Spring管理的bean对象即可。
1 |
|
**说明:**上面的代码记不住咋办呢?
这些内容在MP的官方文档中有详细的说明,我们可以查看官方文档类配置
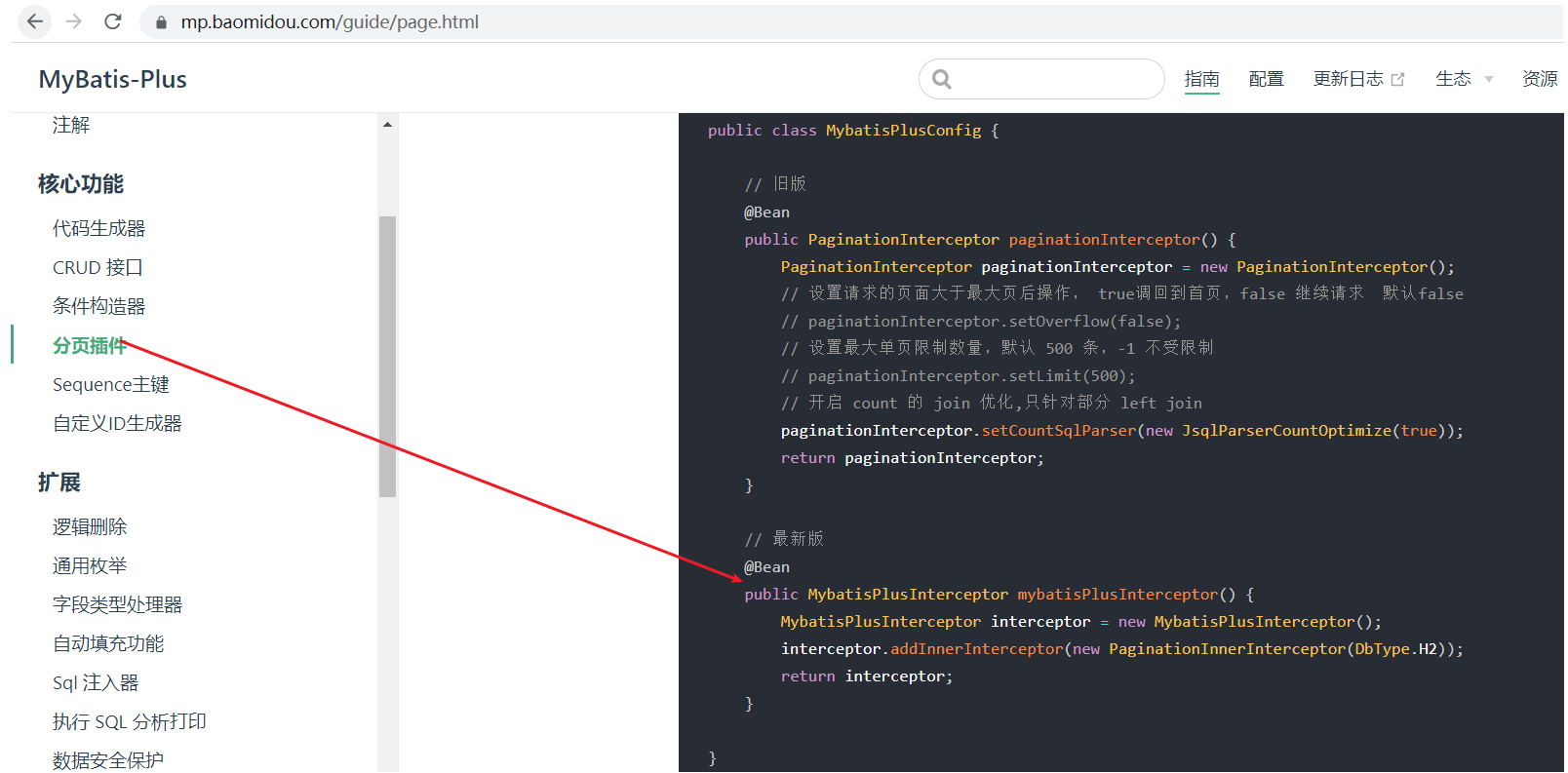
步骤3:运行测试程序

如果想查看MP执行的SQL语句,可以修改application.yml配置文件,
1 | mybatis-plus: |
打开日志后,就可以在控制台打印出对应的SQL语句,开启日志功能性能就会受到影响,调试完后记得关闭。
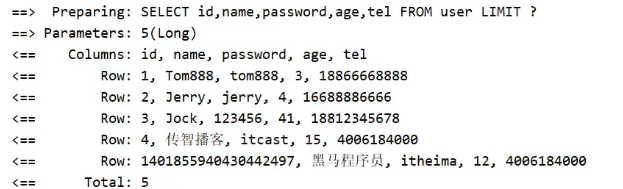
3.0 映射匹配兼容性
前面我们已经能从表中查询出数据,并将数据封装到模型类中,这整个过程涉及到一张表和一个模型类:

之所以数据能够成功的从表中获取并封装到模型对象中,原因是表的字段列名和模型类的属性名一样。
那么问题就来了:
问题1:表字段与编码属性设计不同步
当表的列名和模型类的属性名发生不一致,就会导致数据封装不到模型对象,这个时候就需要其中一方做出修改,那如果前提是两边都不能改又该如何解决?
MP给我们提供了一个注解@TableField,使用该注解可以实现模型类属性名和表的列名之间的映射关系

问题2:编码中添加了数据库中未定义的属性
当模型类中多了一个数据库表不存在的字段,就会导致生成的sql语句中在select的时候查询了数据库不存在的字段,程序运行就会报错,错误信息为:
==Unknown column ‘多出来的字段名称’ in ‘field list’==
具体的解决方案用到的还是@TableField注解,它有一个属性叫exist,设置该字段是否在数据库表中存在,如果设置为false则不存在,生成sql语句查询的时候,就不会再查询该字段了。
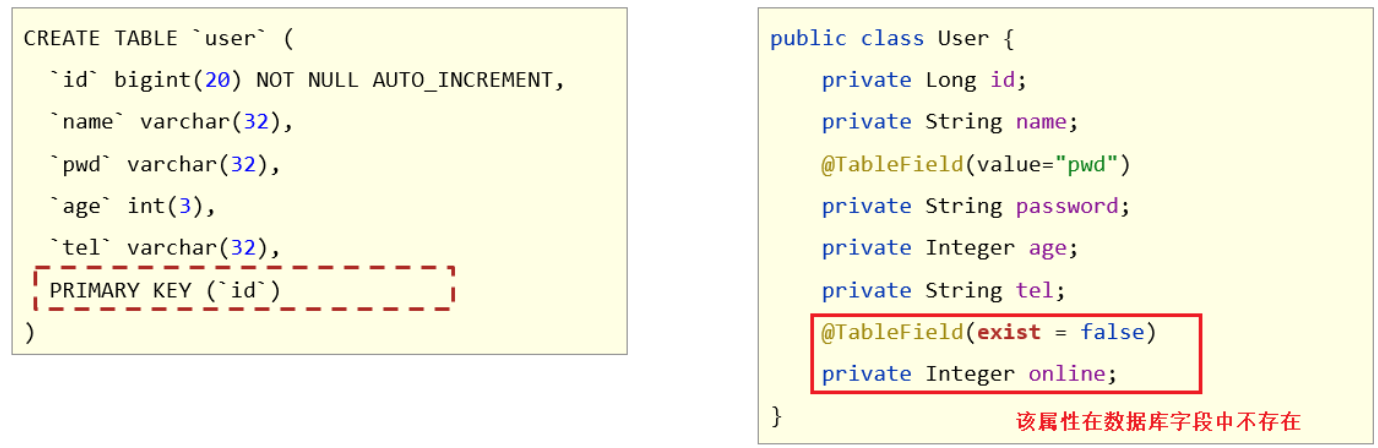
问题3:采用默认查询开放了更多的字段查看权限
查询表中所有的列的数据,就可能把一些敏感数据查询到返回给前端,这个时候我们就需要限制哪些字段默认不要进行查询。解决方案是@TableField注解的一个属性叫select,该属性设置默认是否需要查询该字段的值,true(默认值)表示默认查询该字段,false表示默认不查询该字段。
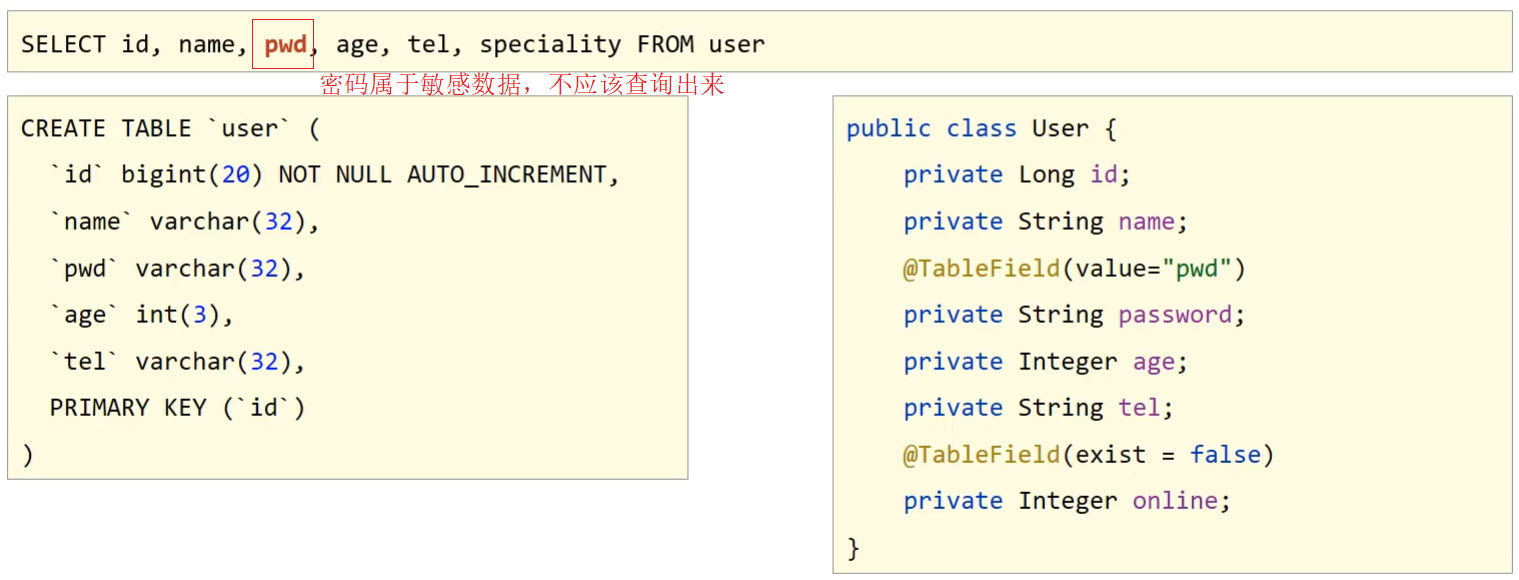
知识点1:@TableField
| 名称 | @TableField |
|---|---|
| 类型 | ==属性注解== |
| 位置 | 模型类属性定义上方 |
| 作用 | 设置当前属性对应的数据库表中的字段关系 |
| 相关属性 | value(默认):设置数据库表字段名称 exist:设置属性在数据库表字段中是否存在,默认为true,此属性不能与value合并使用 select:设置属性是否参与查询,此属性与select()映射配置不冲突 |
问题4:表名与编码开发设计不同步
该问题主要是表的名称和模型类的名称不一致,导致查询失败,这个时候通常会报如下错误信息:
==Table ‘databaseName.tableNaem’ doesn’t exist==,翻译过来就是数据库中的表不存在。
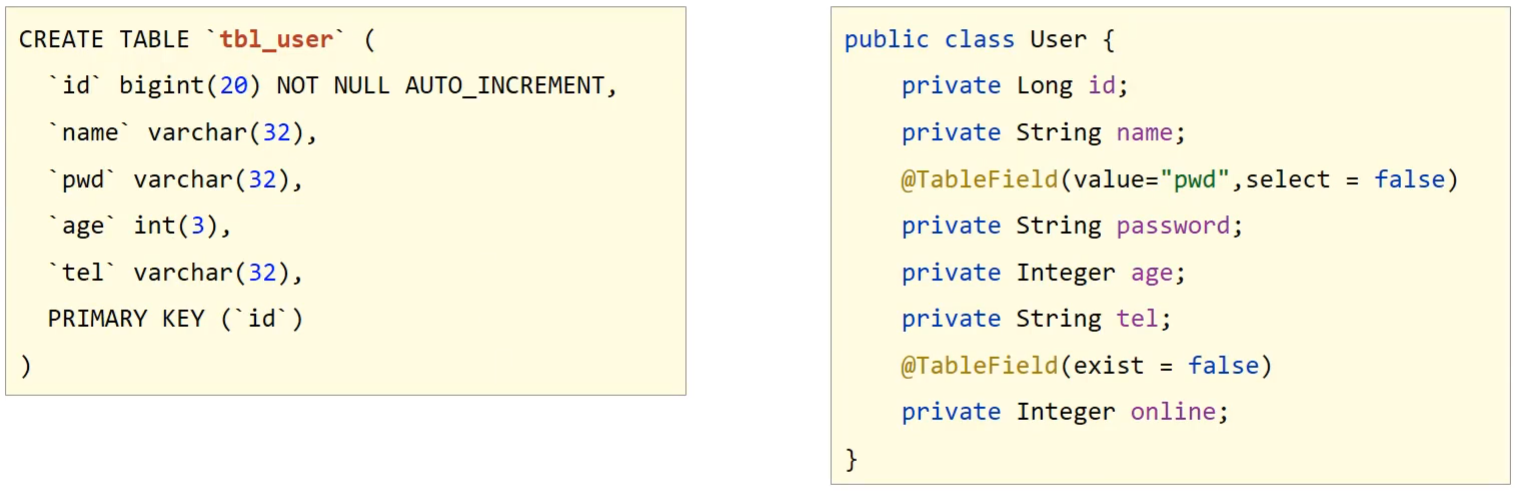
解决方案是使用MP提供的另外一个注解@TableName来设置表与模型类之间的对应关系。

知识点2:@TableName
| 名称 | @TableName |
|---|---|
| 类型 | ==类注解== |
| 位置 | 模型类定义上方 |
| 作用 | 设置当前类对应于数据库表关系 |
| 相关属性 | value(默认):设置数据库表名称 |
4.0 DML编程控制
查询相关的操作我们已经介绍完了,紧接着我们需要对另外三个,增删改进行内容的讲解。挨个来说明下,首先是新增(insert)中的内容。
4.1 id生成策略控制
前面我们在新增的时候留了一个问题,就是新增成功后,主键ID是一个很长串的内容,我们更想要的是按照数据库表字段进行自增长,在解决这个问题之前,我们先来分析下ID该如何选择:
- 不同的表应用不同的id生成策略
- 日志:自增(1,2,3,4,……)
- 购物订单:特殊规则(FQ23948AK3843)
- 外卖单:关联地区日期等信息(10 04 20200314 34 91)
- 关系表:可省略id
- ……
不同的业务采用的ID生成方式应该是不一样的,那么在MP中都提供了哪些主键生成策略,以及我们该如何进行选择?
在这里我们又需要用到MP的一个注解叫@TableId
知识点1:@TableId
| 名称 | @TableId |
|---|---|
| 类型 | ==属性注解== |
| 位置 | 模型类中用于表示主键的属性定义上方 |
| 作用 | 设置当前类中主键属性的生成策略 |
| 相关属性 | value(默认):设置数据库表主键名称 type:设置主键属性的生成策略,值查照IdType的枚举值 |
4.2 逻辑删除
接下来要讲解是删除中比较重要的一个操作,逻辑删除,先来分析下问题:

这是一个员工和其所签的合同表,关系是一个员工可以签多个合同,是一个一(员工)对多(合同)的表
员工ID为1的张业绩,总共签了三个合同,如果此时他离职了,我们需要将员工表中的数据进行删除,会执行delete操作
如果表在设计的时候有主外键关系,那么同时也得将合同表中的前三条数据也删除掉

后期要统计所签合同的总金额,就会发现对不上,原因是已经将员工1签的合同信息删除掉了
如果只删除员工不删除合同表数据,那么合同的员工编号对应的员工信息不存在,那么就会出现垃圾数据,就会出现无主合同,根本不知道有张业绩这个人的存在
所以经过分析,我们不应该将表中的数据删除掉,而是需要进行保留,但是又得把离职的人和在职的人进行区分,这样就解决了上述问题,如:
区分的方式,就是在员工表中添加一列数据
deleted,如果为0说明在职员工,如果离职则将其改完1,(0和1所代表的含义是可以自定义的)
所以对于删除操作业务问题来说有:
- 物理删除:业务数据从数据库中丢弃,执行的是delete操作
- 逻辑删除:为数据设置是否可用状态字段,删除时设置状态字段为不可用状态,数据保留在数据库中,执行的是update操作
介绍完逻辑删除,逻辑删除的本质为:
逻辑删除的本质其实是修改操作。如果加了逻辑删除字段,查询数据时也会自动带上逻辑删除字段。
执行的SQL语句为:
UPDATE tbl_user SET ==deleted===1 where id = ? AND ==deleted===0
执行数据结果为:
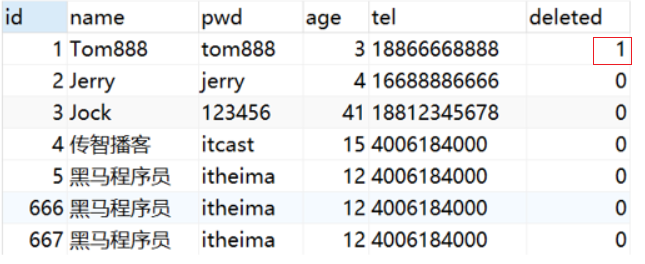
知识点1:@TableLogic
| 名称 | @TableLogic |
|---|---|
| 类型 | ==属性注解== |
| 位置 | 模型类中用于表示删除字段的属性定义上方 |
| 作用 | 标识该字段为进行逻辑删除的字段 |
| 相关属性 | value:逻辑未删除值 delval:逻辑删除值 |
4.3 乐观锁
4.3.1 概念
在讲解乐观锁之前,我们还是先来分析下问题:
业务并发现象带来的问题:==秒杀==
- 假如有100个商品或者票在出售,为了能保证每个商品或者票只能被一个人购买,如何保证不会出现超买或者重复卖
- 对于这一类问题,其实有很多的解决方案可以使用
- 第一个最先想到的就是锁,锁在一台服务器中是可以解决的,但是如果在多台服务器下锁就没有办法控制,比如12306有两台服务器在进行卖票,在两台服务器上都添加锁的话,那也有可能会导致在同一时刻有两个线程在进行卖票,还是会出现并发问题
- 我们接下来介绍的这种方式是针对于小型企业的解决方案,因为数据库本身的性能就是个瓶颈,如果对其并发量超过2000以上的就需要考虑其他的解决方案了。
简单来说,乐观锁主要解决的问题是当要更新一条记录的时候,希望这条记录没有被别人更新。
参考官方文档来实现:
https://mp.baomidou.com/guide/interceptor-optimistic-locker.html#optimisticlockerinnerinterceptor

5.0 快速开发
5.1 代码生成器原理分析
造句:
我们可以往空白内容进行填词造句,比如:
在比如:
观察我们之前写的代码,会发现其中也会有很多重复内容,比如:

那我们就想,如果我想做一个Book模块的开发,是不是只需要将红色部分的内容全部更换成Book即可,如:

所以我们会发现,做任何模块的开发,对于这段代码,基本上都是对红色部分的调整,所以我们把去掉红色内容的东西称之为==模板==,红色部分称之为==参数==,以后只需要传入不同的参数,就可以根据模板创建出不同模块的dao代码。
除了Dao可以抽取模块,其实我们常见的类都可以进行抽取,只要他们有公共部分即可。再来看下模型类的模板:

- ① 可以根据数据库表的表名来填充
- ② 可以根据用户的配置来生成ID生成策略
- ③到⑨可以根据数据库表字段名称来填充
所以只要我们知道是对哪张表进行代码生成,这些内容我们都可以进行填充。
分析完后,我们会发现,要想完成代码自动生成,我们需要有以下内容:
- 模板: MyBatisPlus提供,可以自己提供,但是麻烦,不建议
- 数据库相关配置:读取数据库获取表和字段信息
- 开发者自定义配置:手工配置,比如ID生成策略
5.2 代码生成器实现
步骤1:创建一个Maven项目
代码2:导入对应的jar包
1 |
|
步骤3:编写引导类
1 |
|
步骤4:创建代码生成类
1 | public class CodeGenerator { |
对于代码生成器中的代码内容,我们可以直接从官方文档中获取代码进行修改,
https://mp.baomidou.com/guide/generator.html
步骤5:运行程序
运行成功后,会在当前项目中生成很多代码,代码包含controller,service,mapper和entity
至此代码生成器就已经完成工作,我们能快速根据数据库表来创建对应的类,简化我们的代码开发。
5.3 MP中Service的CRUD
回顾我们之前业务层代码的编写,编写接口和对应的实现类:
1 | public interface UserService{ |
接口和实现类有了以后,需要在接口和实现类中声明方法
1 | public interface UserService{ |
MP看到上面的代码以后就说这些方法也是比较固定和通用的,那我来帮你抽取下,所以MP提供了一个Service接口和实现类,分别是:IService和ServiceImpl,后者是对前者的一个具体实现。
以后我们自己写的Service就可以进行如下修改:
1 | public interface UserService extends IService<User>{ |
修改以后的好处是,MP已经帮我们把业务层的一些基础的增删改查都已经实现了,可以直接进行使用。
编写测试类进行测试:
1 |
|
**注意:**mybatisplus_04_generator项目中对于MyBatis的环境是没有进行配置,如果想要运行,需要提取将配置文件中的内容进行完善后在运行。
思考:在MP封装的Service层都有哪些方法可以用?
查看官方文档:https://mp.baomidou.com/guide/crud-interface.html,这些提供的方法大家可以参考官方文档进行学习使用,方法的名称可能有些变化,但是方法对应的参数和返回值基本类似。
 微信
微信 支付宝
支付宝

